Loop Engineering
The core of Loop Engineering


The AI landscape is unfolding fast, tools and concepts are created on the fly…remember when Context Engineering was new, then Harness Engineering…now we have Loop Engineering.
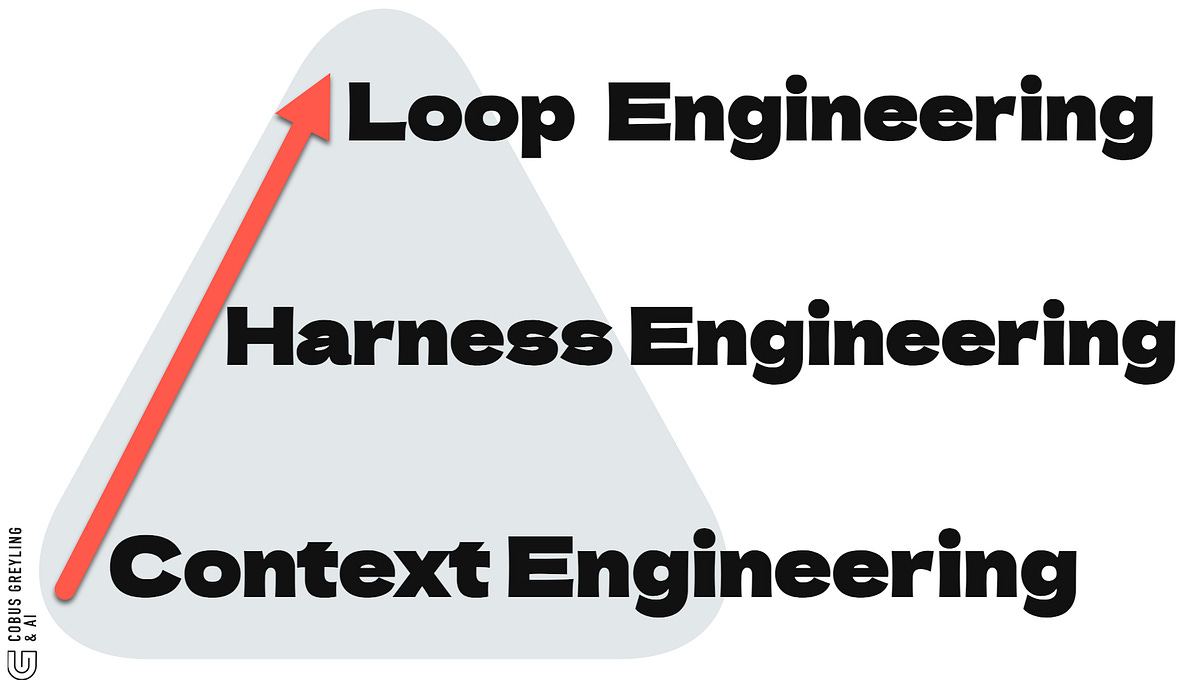
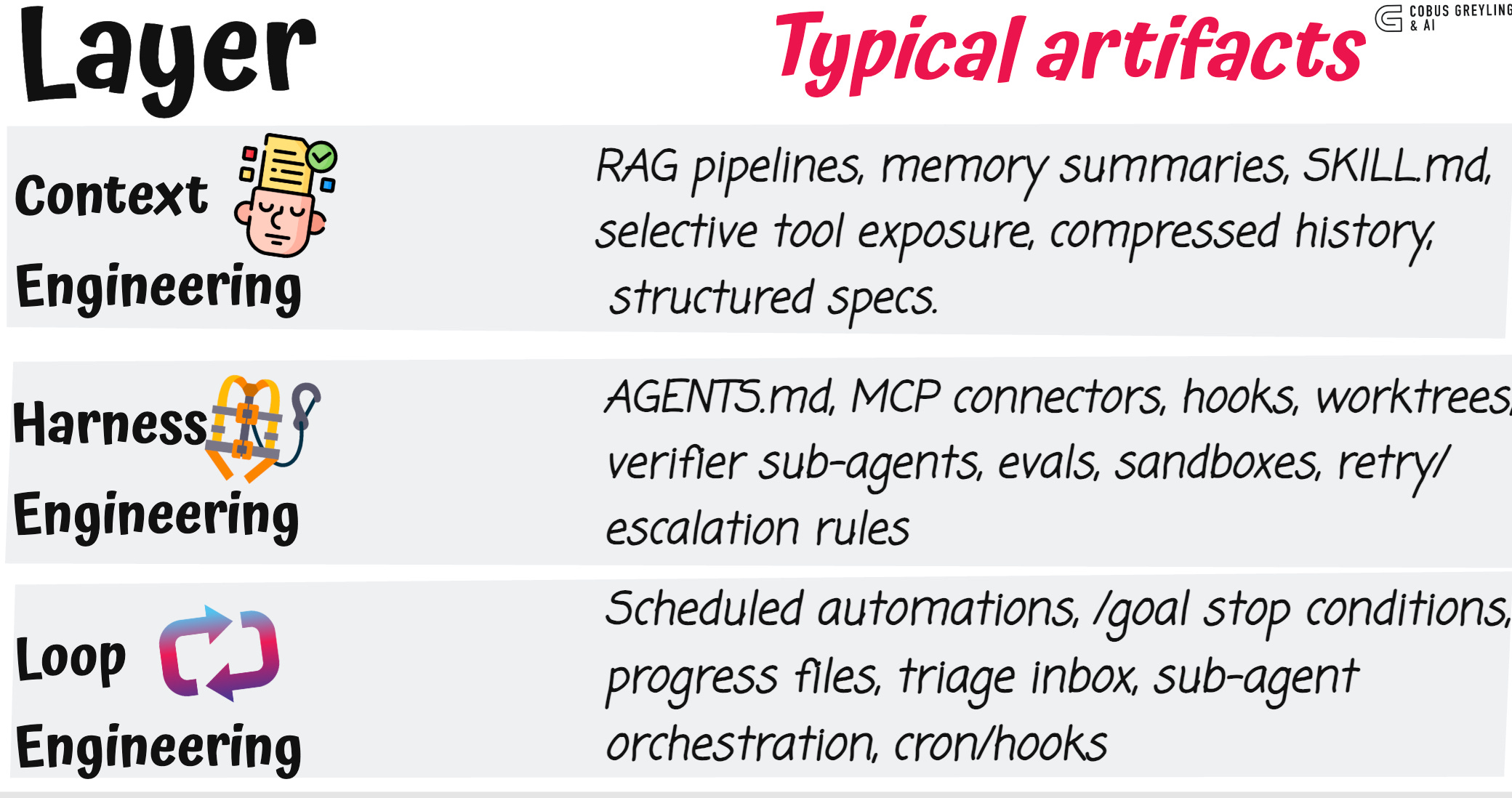
Think of it as three layers, each solving a different problem…

The harness equips a single agent run; the loop is what keeps poking agents on a schedule, spawning helpers, and feeding itself.
Loop engineering is the shift from you being the one who prompts the coding agent turn-by-turn to you designing a system (the loop) that discovers work, hands tasks to agents (often sub-agents), verifies results, persists state, and decides the next action…on a schedule or until a goal is met.
Addy’s framing:
“Loop engineering is replacing yourself as the person who prompts the agent. You design the system that does it instead. A loop here can be thought of a recursive goal where you define a purpose and the AI iterates until complete.”
He quotes two key practitioners:
Peter Steinberger, the creator of OpenClaw…“You shouldn’t be prompting coding agents anymore. You should be designing loops that prompt your agents.”
The tooling convergence is striking: both Claude Code and OpenAI Codex have landed on very similar primitives, so the “loop shape” is becoming somewhat tool-agnostic.
and Boris Cherny (head of Claude Code at Anthropic): “I don’t prompt Claude anymore. I have loops running that prompt Claude and figuring out what to do. My job is to write loops.”
The old workflow (write prompt > read output >write next prompt) is being replaced by building small autonomous control systems that use the agents. Addy calls this one level above “agent harness engineering.”
Anthropic / Boris Cherny Perspective
Boris Cherny has been saying this publicly in talks, interviews, and posts.
Recent signals:
In speeches and workshops (widely clipped): “Now I don’t prompt Claude anymore, I have loops that are running. My job is to write loops.”
“A lot of my code these days is written by ‘routines’. I’m not doing the prompting — I create the routines that do the prompting.”
Apparently loops was named as the feature they’d be proudest of in 10 years.
Other coverage notes Claude Code users running 10–15 parallel agents, using persistent memory files (CLAUDE.md / skills), sub-agents, and loops that scan GitHub/Slack/Twitter, decide what to build, implement, test, and self-fix.
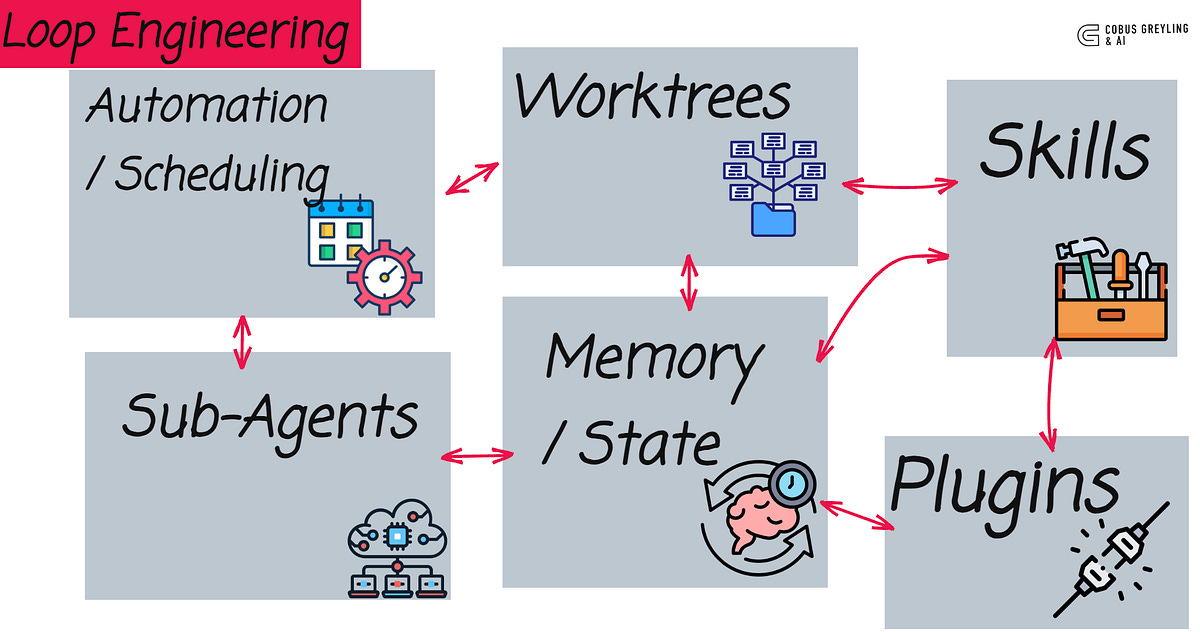
The Five Building Blocks + Memory
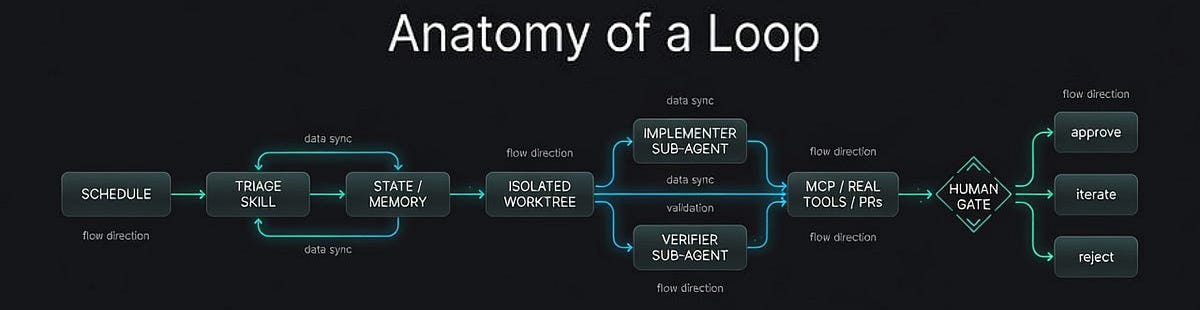
A loop that actually runs unattended is not one long prompt.
It is a small system with six parts. Five are capabilities. The sixth is the spine that holds state between runs.
Automations / Scheduling is the heartbeat
Without a schedule, you have a one-off agent session. With one, you have discovery and triage on a cadence.
This is the piece that turns “I should check CI every morning” into something that happens whether or not you open a terminal.
In Claude Code that might be /loop, /schedule, or /goal — run until a verifiable condition is met, with a separate model checking “done” so the worker does not grade its own homework.
Hooks and GitHub Actions carry the same idea into persistence outside the chat.
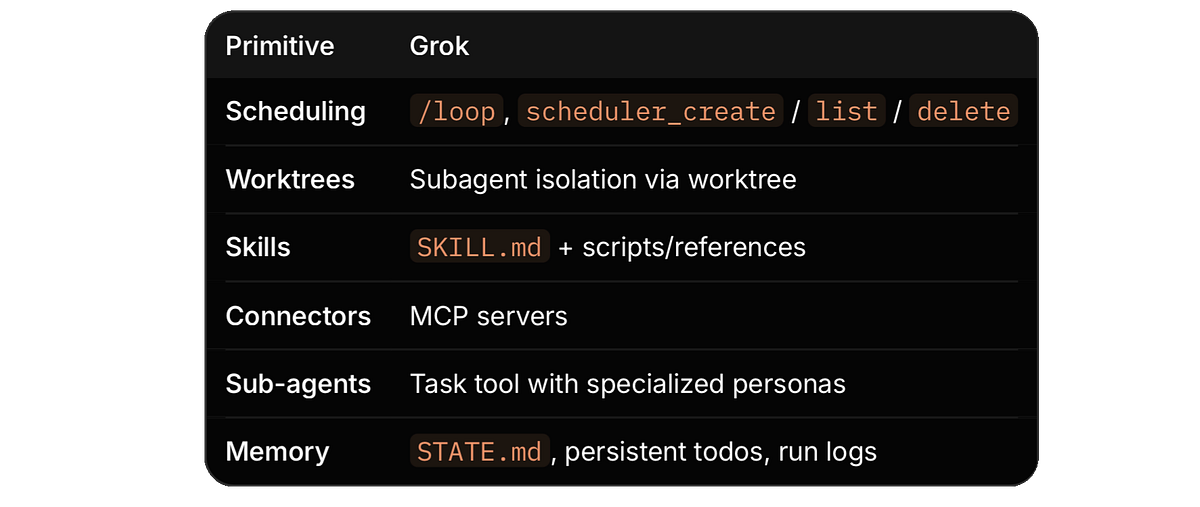
In Grok: /loop [interval] <prompt> plus the underlying scheduler tools (scheduler_create, scheduler_list, scheduler_delete). Recurring, durable, fire-immediately.
The heartbeat does not need to be clever but it needs to be reliable.
Worktrees for safe parallel execution
Two agents editing the same files at the same time is merge disaster waiting to happen.
Isolated git worktrees, or equivalent checkouts, give each agent its own working directory while sharing history.
Both major coding-agent tools ship this, sub-agents can be launched into fresh checkouts so parallel work does not collide.
In Grok: pass isolation: “worktree” when spawning subagents, or use dedicated sessions. Cleanup matters. A loop that leaves orphaned worktrees behind is a loop you will regret.
Skills persistent project knowledge
Every session, the agent starts cold.
Conventions, build commands, review standards, and the incident that taught you “we do not do it that way”, all of it has to be re-derived unless you externalise it.
Skills are how you pay down intent debt.
A SKILL.md (plus optional scripts and references) holds the knowledge that should survive across runs. Claude Code uses CLAUDE.md and skills, packaged as plugins for sharing. Grok uses the same pattern.
Without skills, every loop run is day one.
Plugins & Connectors reach into real tools
A loop that can only read the filesystem is a loop that can only suggest.
MCP-based connectors let the loop act: open PRs, update Linear tickets, post to Slack, query a database, trigger a runbook. The loop stops being a commentator and starts being an operator.
MCP has become the common substrate, so connectors written for one tool often port to another. Both Claude Code and Grok support it.
But there are various options…to name a few…

Sub-agents are the maker/checker split
The agent that wrote the code is a poor judge of its own work. This is not a model limitation. It is a structural one.
One agent (or team) explores and implements. A different one, sometimes a stronger model, always with different instructions…verifies against specs, skills, and tests.
In unattended loops, the verifier is what lets you walk away with some confidence. /goal in several tools applies the same principle: a fresh model decides whether the stopping condition has been met.
Memory is the durable spine
None of the above survives a session boundary on its own…
The loop must read from and write to something external: a STATE.md, a LOOP-STATE.json, a Linear board column, a GitHub Project view. Good state answers three questions:
• What are we working on right now?
• What did we try last time, and what happened?
• What is waiting for a human?
For multi-day or multi-run loops, this is non-negotiable. The state file is often the most important artifact the loop produces.
What Grok already ships
The Grok TUI maps onto this stack without much translation:
The realities nobody should skip
Loops are early.
The economics and verification challenges are real.
Token costs vary wildly.
Sub-agents and frequent cadences multiply fast.
A 5-minute loop that spawns implementer + verifier on every run will burn through a limited plan before breakfast.
Triage should be cheap; sub-agents should spawn only when state says actionable.
“Done” is a claim until you confirm it. Unattended loops make unattended mistakes. The verifier helps. It does not replace you reading what landed in the repo.
Comprehension debt grows faster with good loops.
Speed can mask the gap between what exists and what you actually understand. The loop shipped it, but that does not mean you know how it works.
Cognitive surrender is the comfortable trap.
The same loop design can accelerate someone who stays the engineer, or let someone abdicate judgment entirely. Build the loop like someone who intends to stay the engineer — not just the person who presses go.
Lastly
Prompting directly is still powerful and often it is the right tool.
But the leverage point has moved.
Peter Steinberger put it plainly…you should not be prompting coding agents anymore…you should be designing loops that prompt your agents.
Boris Cherny at Anthropic says the same from the inside: his job is to write loops, not individual prompts.
That is loop engineering. Not a bigger prompt but a system that discovers, assigns, verifies, persists and knows when to hand off to you.
Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. From Language Models, AI Agents to Agentic Applications, Development Frameworks & Data-Centric Productivity Tools, I share insights and ideas on how these technologies are shaping the future.
GitHub - cobusgreyling/loop-engineering: Practical reference and patterns for loop engineering …
Practical reference and patterns for loop engineering - designing systems that prompt and orchestrate AI coding agents…github.com
COBUS GREYLING - At the intersection of AI & Language
Cobus Greyling is an AI Evangelist & thought leader dedicated to exploring the intersection of artificial intelligence…cobusgreyling.me
Effective harnesses for long-running agents
Anthropic is an AI safety and research company that’s working to build reliable, interpretable, and steerable AI…www.anthropic.com
When AI builds itself
Our progress toward recursive self-improvement, and its implications.www.anthropic.com
Addy Osmani on X (formerly Twitter): “https://t.co/hIe0UX7z6T / X”
https://t.co/hIe0UX7z6Tx.com