Multi-Label Text Classification With Google Cloud Vertex AI
Using Google Cloud Vertex AI a ML model can be trained which facilitates multi-label responses.


In previous posts I wrote an overview of Google Cloud Vertex AI, data preparation and creating a text classification model.
Considering text classification within Vertex AI, the text data type options are:
Single label text classification
Multi-label text classification
Entity extraction
Emotion detection
Below you can see the option is selected to train a multi-label text classification model.
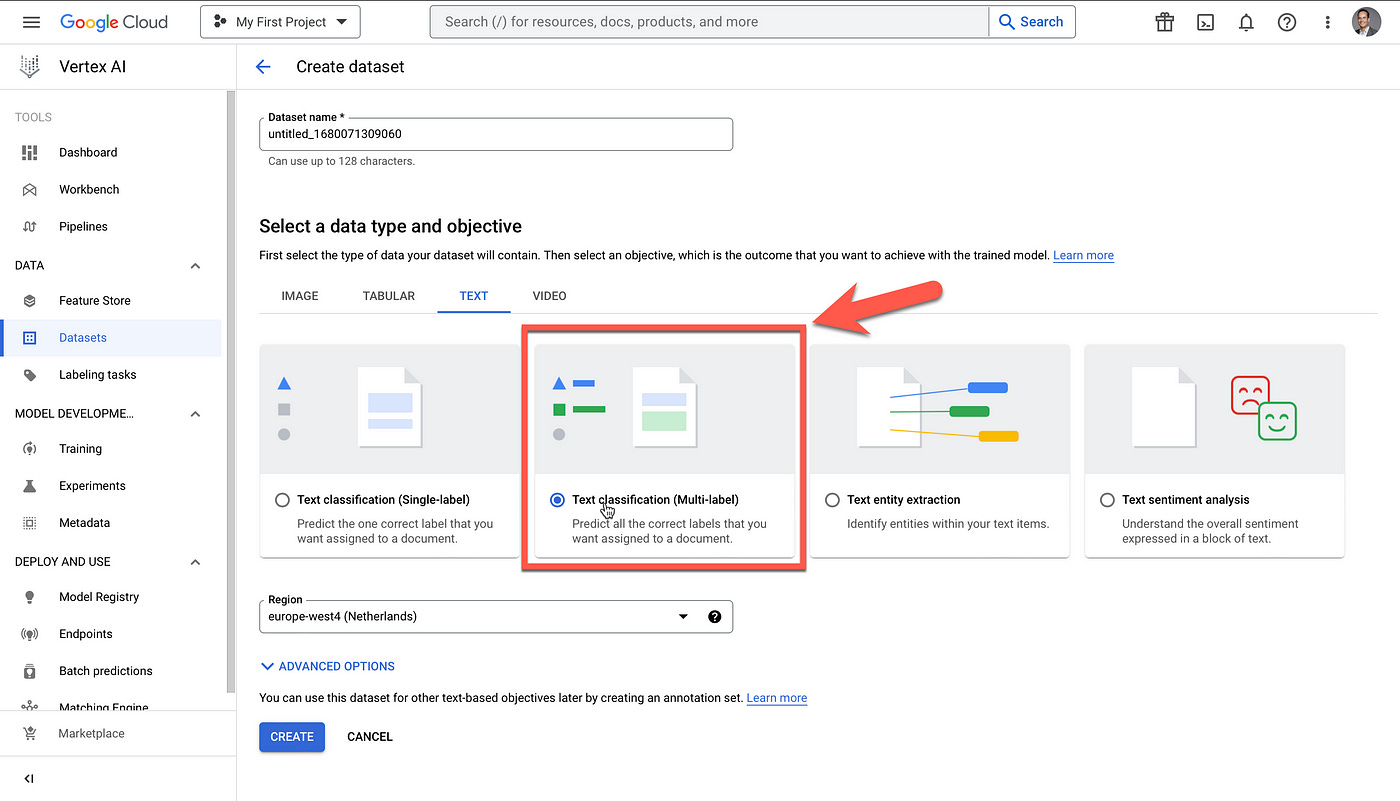
For multi-label classification using Vertex AI, the training data can have one or multiple labels assigned to a document.
The idea of having multiple labels associated with a piece of text, still does not address needs of establishing a data taxonomy.
NLU Engines have been incorporating taxonomies / hierarchies for a number of years already. Where intents/labels/classifications can be extended to sub-intents. One can think of this as a process of categorising intents into smaller sub-categories.
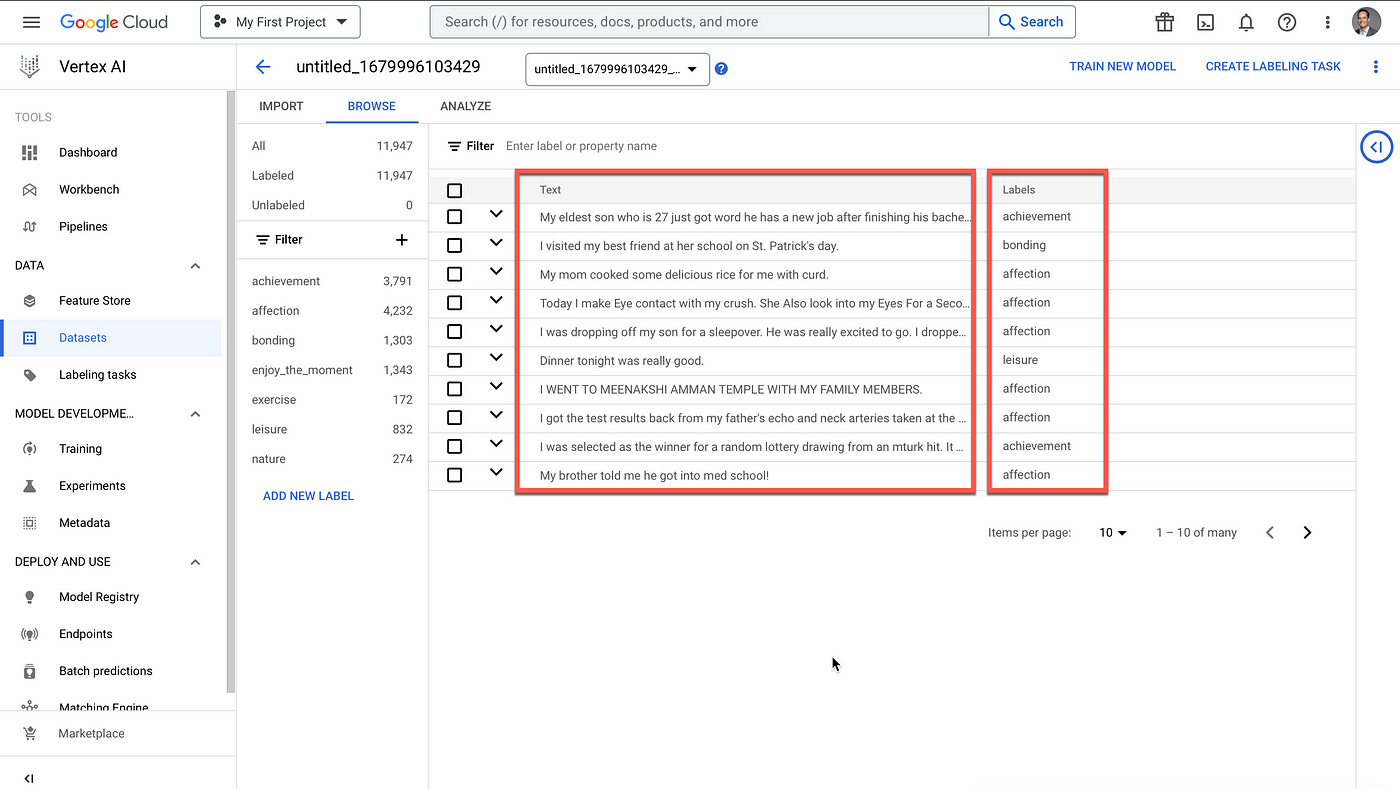
Considering the image below, it shows the data view for the text and labels to be incorporated into the model. NLU Engines typically have incorporated a GUI for entering data.
Google Cloud Vertex AI has a convoluted and complex structure for datastorage in Google Cloud for classification training.
In the image below the natural inclination is to add data directly into the Vertex AI console.
I actually tried to create a new label via the GUI, which is possible. But it is not possible to manage the labels and training data. It is also not possible to add examples or update text strings.
Some intent management frameworks have a drag and drop interface where intents can be split, merged, sub categories created, sub-intents, etc.
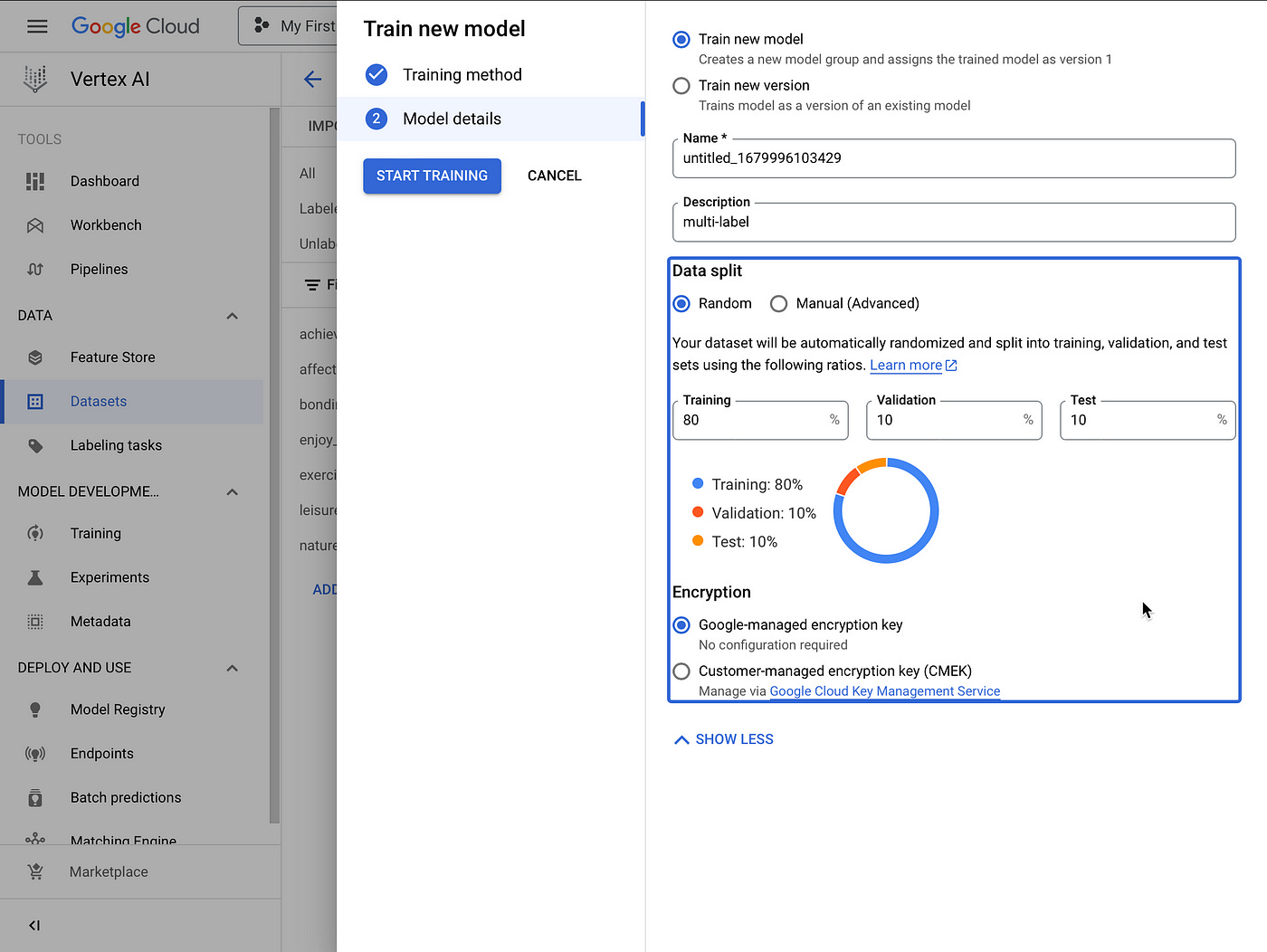
The split of data for training, validation and testing is shown an a convenient graphic with ratios which can be easily set.
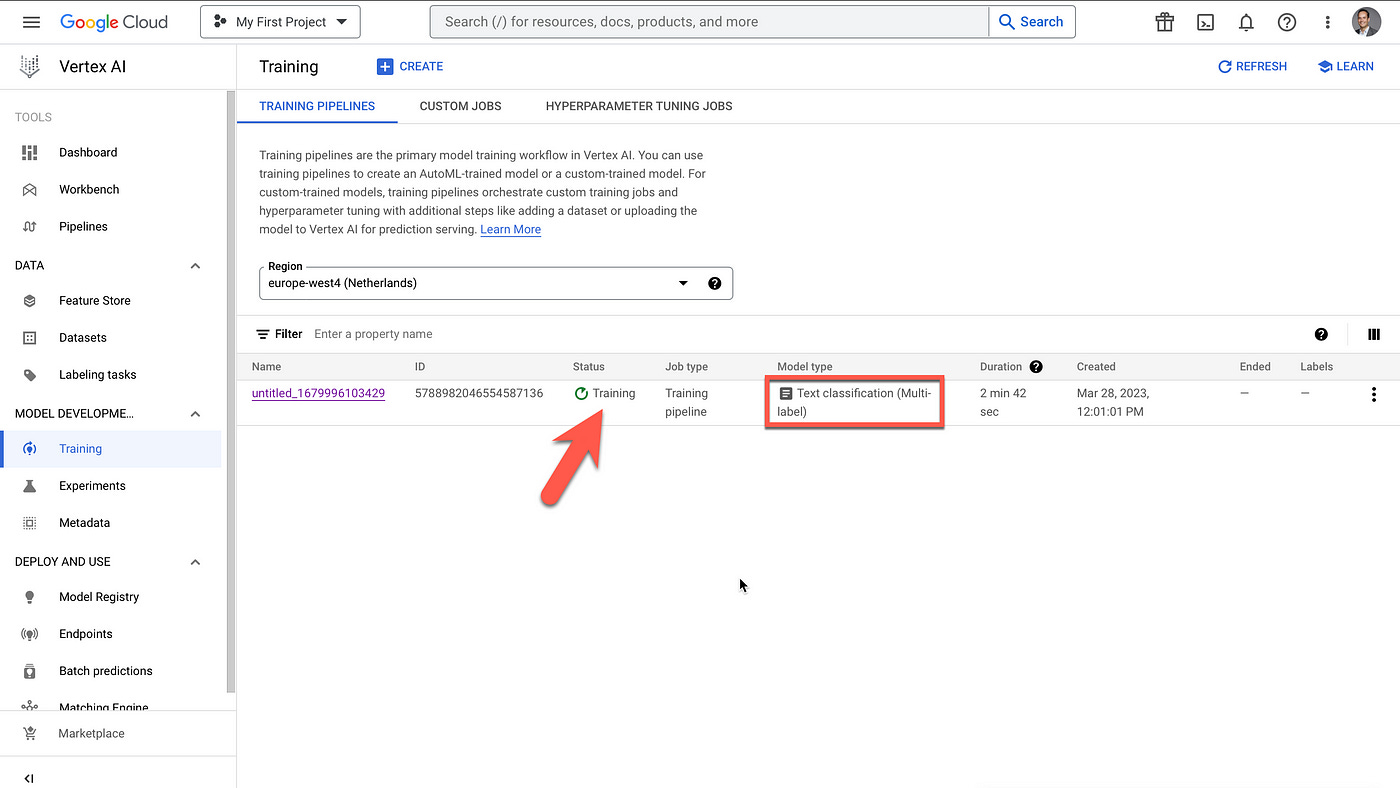
Considering the image below, the training time of the multi-label model ended up to be quite long. For 11,947 training data items, the model training time was 4 hours, 48 minutes.
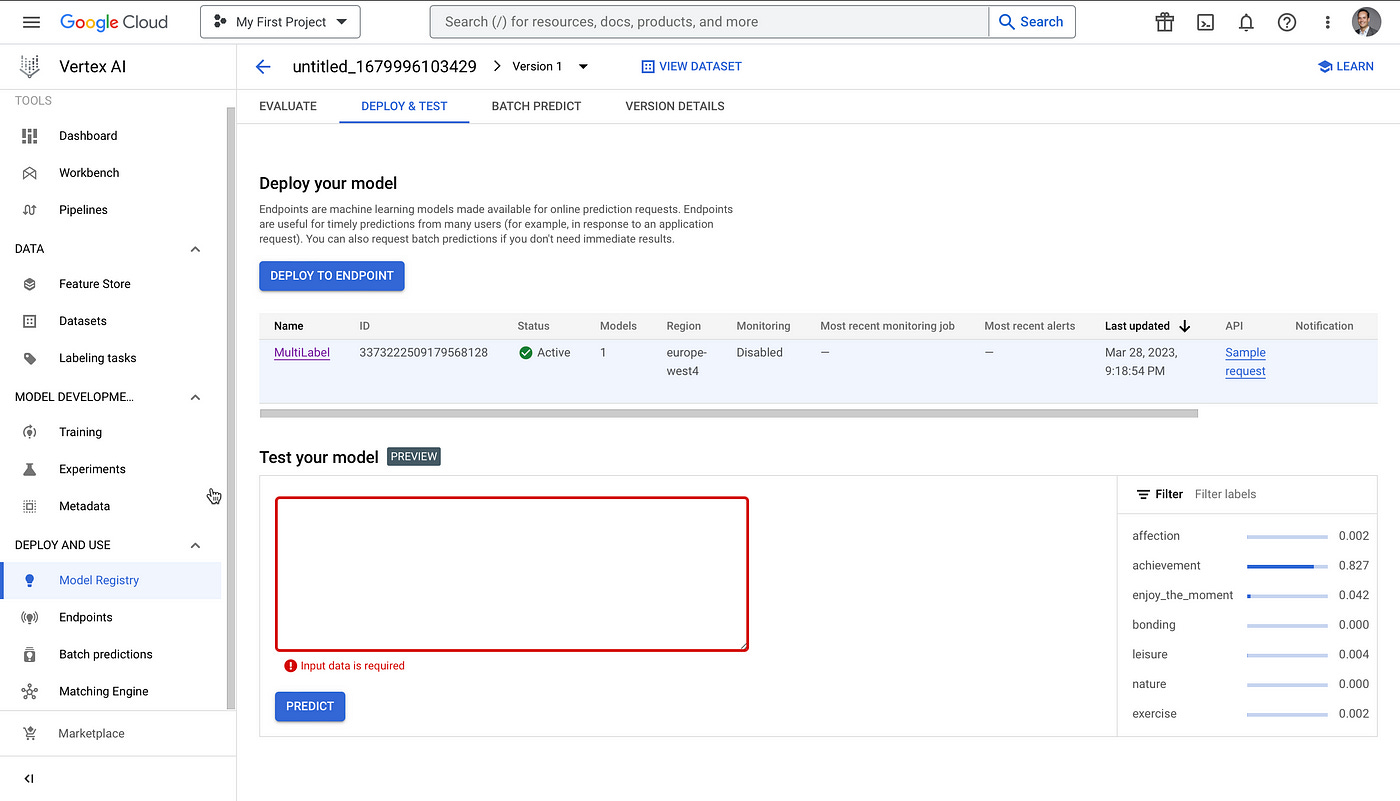
Lastly, the model can be tested and interacted with, via the model preview panel. This allows for a quick avenue of testing the model.
In Closing
The process of preparation of training data is described by Google in detail.
However, considering the emergence of data-centric AI and the importance of structuring training data…I would say Vertex AI’s one obvious vulnerability is the process of curating, structuring and augmenting AI training data.

⭐️ Please follow me on LinkedIn for updates on Conversational AI ⭐️
I’m currently the Chief Evangelist @ HumanFirst. I explore and write about all things at the intersection of AI and language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces and more.

