Multi-Modal Agentic Applications
Known by various names — AI Agents, Agents, Agentic Applications, and more. In this article, I provide a brief overview of what an AI Agent is and explore why being multi-modal is a game-changer.

At the conclusion of this article, I have included a fundamental demonstration of LangChain interactions using OpenAI’s multimodal Small Language Model, gpt-4o-mini.
My goal is always to distill complex concepts into their simplest forms, and these working notebooks exemplify the basic integration of multiple modalities for interacting with the model.
Introduction
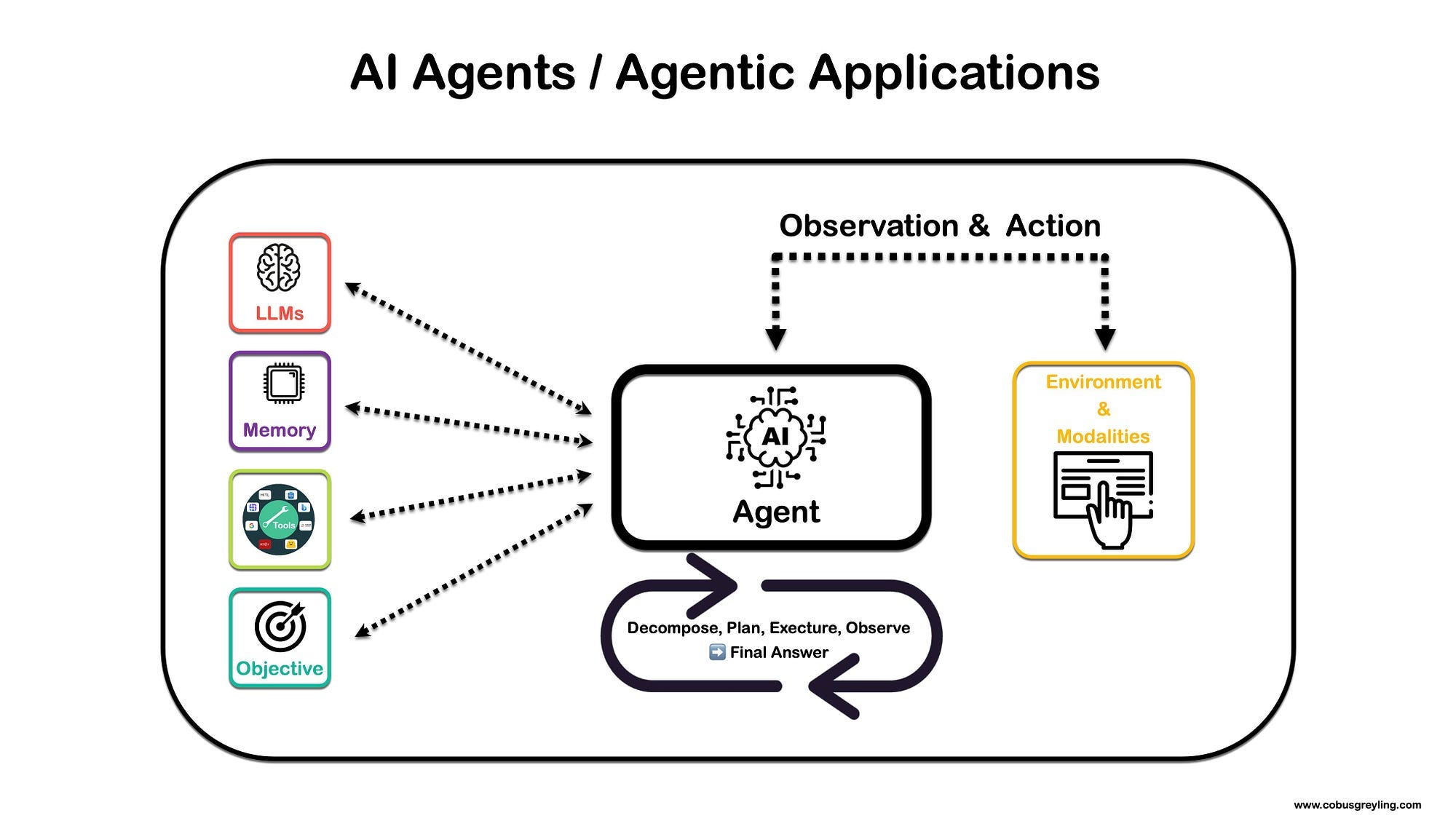
An AI Agent is a software program designed to perform tasks or make decisions autonomously based on the tools that are available.
As shown in the image below, agents rely on one or more Large Language Models or Foundation Models to break down complex tasks into manageable sub-tasks.
These sub-tasks are organised into a sequence of actions that the agent can execute.
The agent also has access to a set of defined tools, each with a description that helps it determine when and how to use these tools in sequence to address challenges and reach a final conclusion.
Tools
The tools available to the agent can include APIs for research portals such as Arxiv, HuggingFace, GALE, Bing search, and Serp API.
One notable tool is the Human-In-The-Loop feature, which allows the agent to contact a live human if it encounters uncertainty about the next step or conclusion. This human agent can provide answers to specific questions, ensuring the agent can address challenges more effectively.
AI Agents & Autonomy
There is this fear regarding AI agents and their level of autonomy…there are three limiting factors to agents, which also introduces a certain level of safety…
The number of loops or iterations the agent is allowed.
The tools at the disposal of the Agent. The number and the nature of the tools available to the agent determines how autonomous the agent is. The agent follows a process of decomposing a problem into smaller sequential steps or problems, in order to solve the larger challenge. For each of these steps, one or more tools can be selected by the agent.
A human can be added as a tool, if the agent is below a certain level of confidence, it can reach out to a human for input; human as a tool.
Decomposition & Planning
The code below shows a complete working example of a LangChain Agentanswering an extremely ambiguous and complex question:
What is the square root of the year of birth of the person who is regarded as the father of the iPhone?
To solve this question, the agent prototype had at its disposal:
Multi-Modal Agents
There are two angles to multi-modal agents…
Firstly, language models with vision capabilities enhance AI agents by adding an additional modality.
I have often contemplated the best use cases for multi-modal models, and utilising these models in agent applications that require vision represents an excellent example.
Secondly, there are a number of developments which include Ferrit-UI from Apple, and the WebVoyager / LangChain implementation where GUI elements are mapped and defined with named bounding boxes.
As seen below:
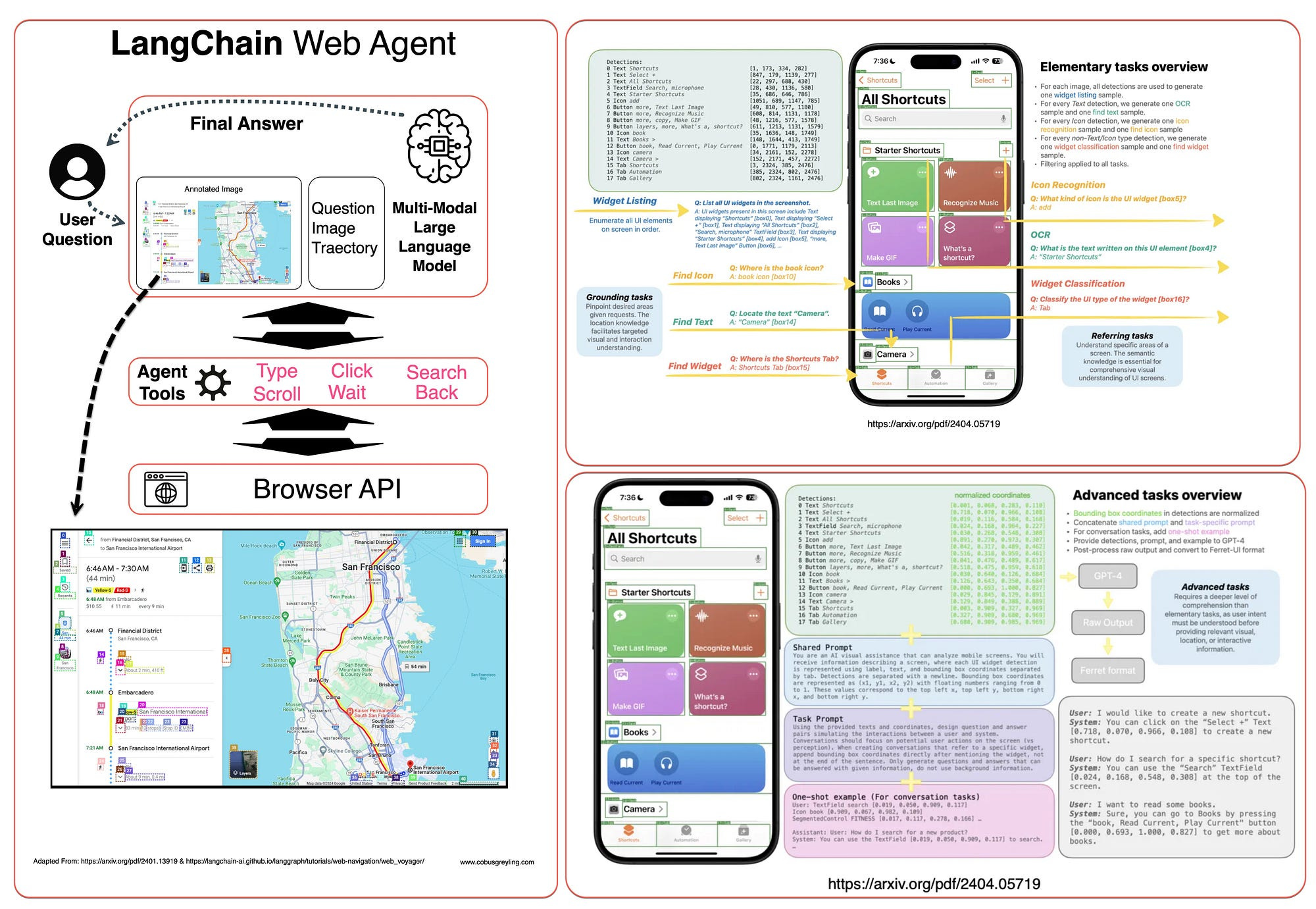
LangChain Multi-Modal Generative Application
Below is fully working code, you can copy it and paste it directly into a notebook and run. The only thing you will need is an OpenAI API Key.
In the code below, LangChain demonstrates how to pass multimodal input directly to models. Currently, all input should be formatted according to OpenAI’s specifications. For other model providers that support multimodal input, LangChain implemented logic within the class to convert the data into the required format.
### Image URL Setup
image_url = "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg"
#### Package Installation
pip install -q langchain_core
pip install -q langchain_openai
#### Environment Setup
import os
os.environ['OPENAI_API_KEY'] = str("<Your OpenAI API Key goes here>")
#### Model Initialization
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o-mini")
### The httpx library fetches the image from the URL, and the base64
### library encodes the image data in base64 format.
### This conversion is necessary to send the image data as part of the
### input to the mode.
import base64
import httpx
image_data = base64.b64encode(httpx.get(image_url).content).decode("utf-8")
### Constructing the message. This creates a HumanMessage object that contains
### two types of input: a text prompt asking to describe the weather in the
### image, and the image itself in base64 format.
message = HumanMessage(
content=[
{"type": "text", "text": "describe the weather in this image"},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{image_data}"},
},
],
)
### The model.invoke method sends the message to the model,
### which processes it and returns a response.
response = model.invoke([message])
### The result, which should be a description of the weather in the image,
### is then printed out.
print(response.content)The response:
he weather in the image appears to be clear and pleasant,
with a bright blue sky scattered with clouds.
The lush green grass and vibrant foliage suggest it is likely a warm season,
possibly spring or summer.
The overall scene conveys a calm and inviting atmosphere,
ideal for outdoor activities.Describing an image…
### HumanMessage: This is an object that encapsulates the input data meant
### for the AI model. It includes a list of content items,
### each specifying a different type of input.
message = HumanMessage(
content=[
{"type": "text", "text": "describe the weather in this image"},
{"type": "image_url", "image_url": {"url": image_url}},
],
)
### The model response is assigned
response = model.invoke([message])
###. And the response is printed out
print(response.content)Response:
The weather in the image appears to be pleasant and clear.
The sky is mostly blue with some fluffy clouds scattered across it,
suggesting a sunny day.
The vibrant green grass and foliage indicate that it might be spring or summer,
with warm temperatures and good visibility.
The overall atmosphere looks calm and inviting,
perfect for a walk along the wooden path.Comparing to images…
### The HUmanMessage object encapsulates text input and two images.
### The model is asked to compare the two images.
message = HumanMessage(
content=[
{"type": "text", "text": "are these two images the same?"},
{"type": "image_url", "image_url": {"url": image_url}},
{"type": "image_url", "image_url": {"url": image_url}},
],
)
response = model.invoke([message])
print(response.content)And the response…
Yes, the two images are the same.This working code below shows how to create a custom tool that can be created
### It allows you to restrict a function's input to specific literal
### values—in this case, specific weather conditions
### ("sunny," "cloudy," or "rainy").
from typing import Literal
### It's used to define a custom tool that the AI model can use during
### its execution.
from langchain_core.tools import tool
### This decorator registers the function as a tool that the model can use.
### Tools are custom functions that can be invoked by the AI model to perform
### specific tasks.
@tool
### Function Body: The function currently doesn't perform any action (pass simply means "do nothing"),
### but in a full implementation, it might process the input weather condition in some way, such as generating a description.
def weather_tool(weather: Literal["sunny", "cloudy", "rainy"]) -> None:
"""Describe the weather"""
pass
### This line binds the weather_tool to the AI model,
### creating a new model instance (model_with_tools) that is capable of
### using this tool. Now, whenever the model processes input,
### it can invoke weather_tool if needed.
model_with_tools = model.bind_tools([weather_tool])
### This section constructs a HumanMessage object containing both a
### text prompt and an image URL. The prompt asks the model to
### 'describe the weather in this image,' while the image URL points to the
### image to be analyzed.
message = HumanMessage(
content=[
{"type": "text", "text": "describe the weather in this image"},
{"type": "image_url", "image_url": {"url": image_url}},
],
)
### model_with_tools.invoke([message]): This line sends the constructed
### message to the model instance that has the weather_tool bound to it.
### The agent processes the inputs and, if necessary, uses the tool to help
### generate its response.
response = model_with_tools.invoke([message])
### response.tool_calls: This attribute contains a log of any tool calls the
### model made while processing the message.
### If the agent decided to use weather_tool to help generate a response,
### that action would be recorded here.
print(response.tool_calls): This line prints the list of tool calls to the console, providing insight into whether and how the model used the weather_tool.
print(response.tool_calls)And the response…
[{'name': 'weather_tool', 'args': {'weather': 'sunny'}, 'id': 'call_l5qYYYSpUQf2UbBE450bNjqo', 'type': 'tool_call'}]I’m currently the Chief Evangelist @ Kore.ai. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.