

NVIDIA Says Small Language Models Are The Future of Agentic AI
From LLM-centric to SLM-first architectures

TLDR
NVIDIA does not want you to use one Large Language Model for all AI Agent tasks.
The reasoning includes cost, latency, overhead, LLM impediments like Hosting needs, commercial commitments etc.
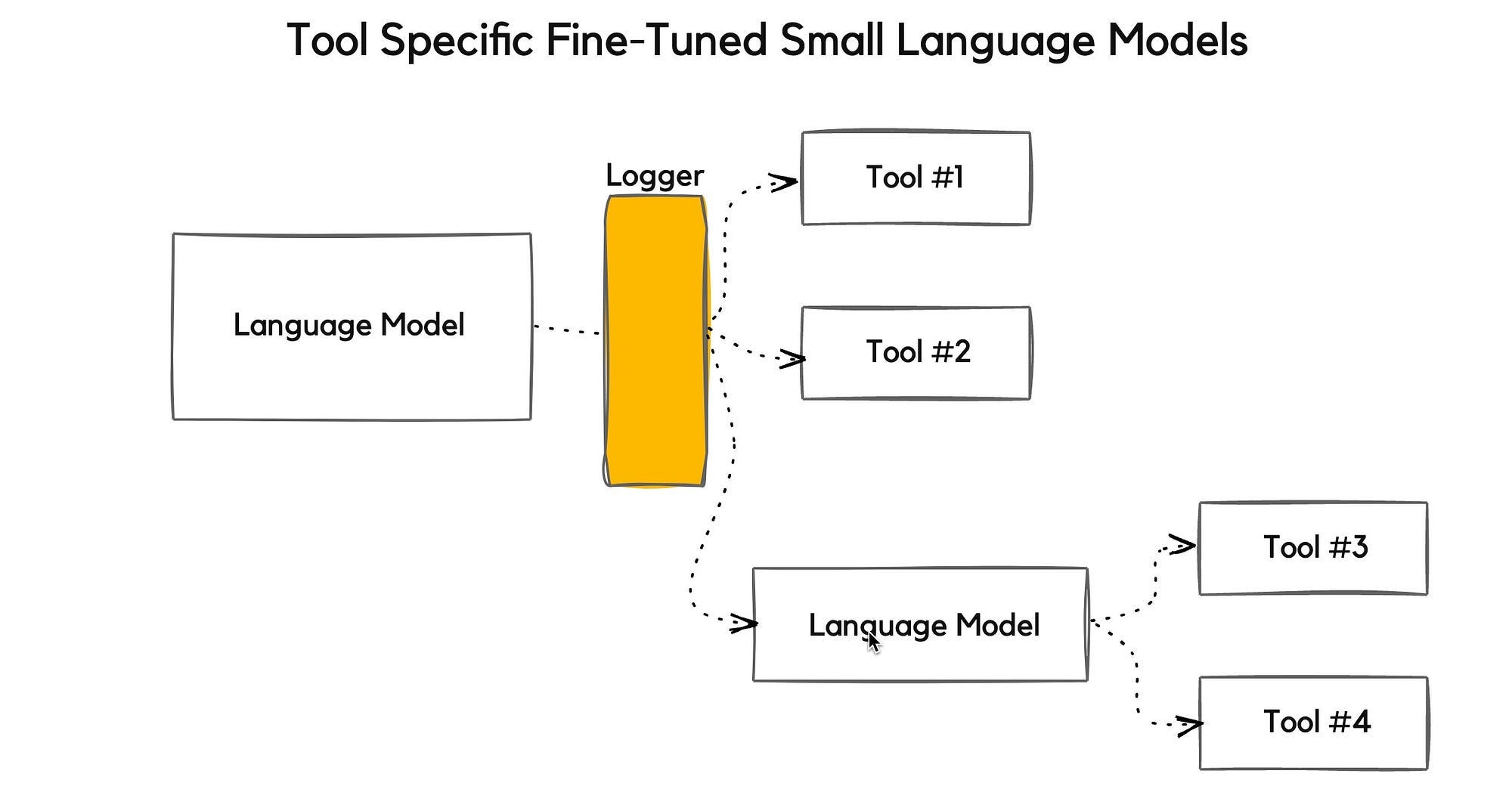
They are proposing a data flywheel approach of examining usage data, then clustering usage data according to tools available.
(SLMs) are sufficiently powerful, inherently more suitable & necessarily more economical for many invocations in agentic systems, and are therefore the future of agentic AI.
~ NVIDIA
And subsequently, having task specific Small Language Models fine-tuned for the available tools.
Currently we have seen scenarios where Agentic applications are optimised to cater for LLM requirements. This is a situation where the tail is wagging the tail.
NVIDIA is proposing the selection of models based on sub-tasks and continuous improvement. Hence the use-case and actual usage patterns being used to train the Small Language Models.
Small, rather than large, language models are the future of agentic AI
~ NVIDIA
More on the Study
This is one of the most sobering papers you will read…I have always been a proponent of bringing sanity to the market and this is exactly what NVIDIA has done here.
NVIDIA highlights the significance of the operational and economic impact even a partial shift from LLMs to SLMs can have on the AI Agent industry.
The core components powering most modern AI agents are (very) Large Language Models.
Language Models enable AI Agents to make strategic decisions about when and how to use available tools, control the flow of operations needed to complete tasks and, if necessary, break down complex tasks into manageable subtasks and to perform reasoning for action planning and problem-solving.
A typical AI Agent then simply communicates with a chosen LLM API endpoint by making requests to centralised cloud infrastructure that hosts these models
Agentic interactions are natural pathways for gathering data for future improvement.
~ NVIDIA
LLM API endpoints are specifically designed to serve a large volume of diverse requests using one generalist LLM. This operational model is deeply ingrained in the industry
NVIDIA asserts that the dominance of LLMs in the design of AI Agents is both excessive and misaligned with the functional demands of most agentic use-cases.
Small Language Models
They offer several advantages: lower latency, reduced memory and computational requirements and significantly lower operational costs, all while maintaining adequate task performance in constrained domains.
Small Language Models for Subtasks
AI Agent systems typically decompose complex goals into modular sub-tasks, each of which can be reliably handled by specialised or fine-tuned SLMs
So why not have use-case specific models for specific sub-tasks. Hence a situation where SLMs are used by default and LLMs are invoked selectively and sparingly.
With modern training, prompting and agentic augmentation techniques, capability — not the parameter count — is the binding constraint.

SLMs are more economical in agentic systems due to:
Inference efficiency
Fine-tuning agility
Edge deployment
Parameter utilisation
NVIDIA argues that incorporating multiple Language Models of different sizes and capabilities for queries or operations of different levels of complexity offers a natural way for the introduction of SLMs.
Barriers to Adoption
As mentioned, Small Language Models (SLMs) hold immense potential for efficient, task-specific AI solutions, but their adoption faces some real challenges.
High upfront costs for centralised Large Language Model (LLM) infrastructure, the use of generic benchmarks in SLM development, and a lack of buzz — SLMs often fly under the radar compared to their heavily marketed LLM counterparts — are holding things back.
But there’s a way to bridge the gap, and it’s a game-changer for organisations looking to optimise.

A 6-step algorithm to transform bulky, general-purpose LLMs into lean, specialised SLM agents.
It starts with gathering usage data from your existing LLM setup and
Scrubbing it clean of any sensitive info.
Next, the algorithm spots recurring task patterns by clustering the data, helping you pinpoint what your AI actually needs to do.
From there, you pick the right SLMs for each task type and
fine-tune them with tailored datasets.
A continuous improvement loop to keep your SLMs sharp and effective over time.

Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. From Language Models, AI Agents to Agentic Applications, Development Frameworks & Data-Centric Productivity Tools, I share insights and ideas on how these technologies are shaping the future.
