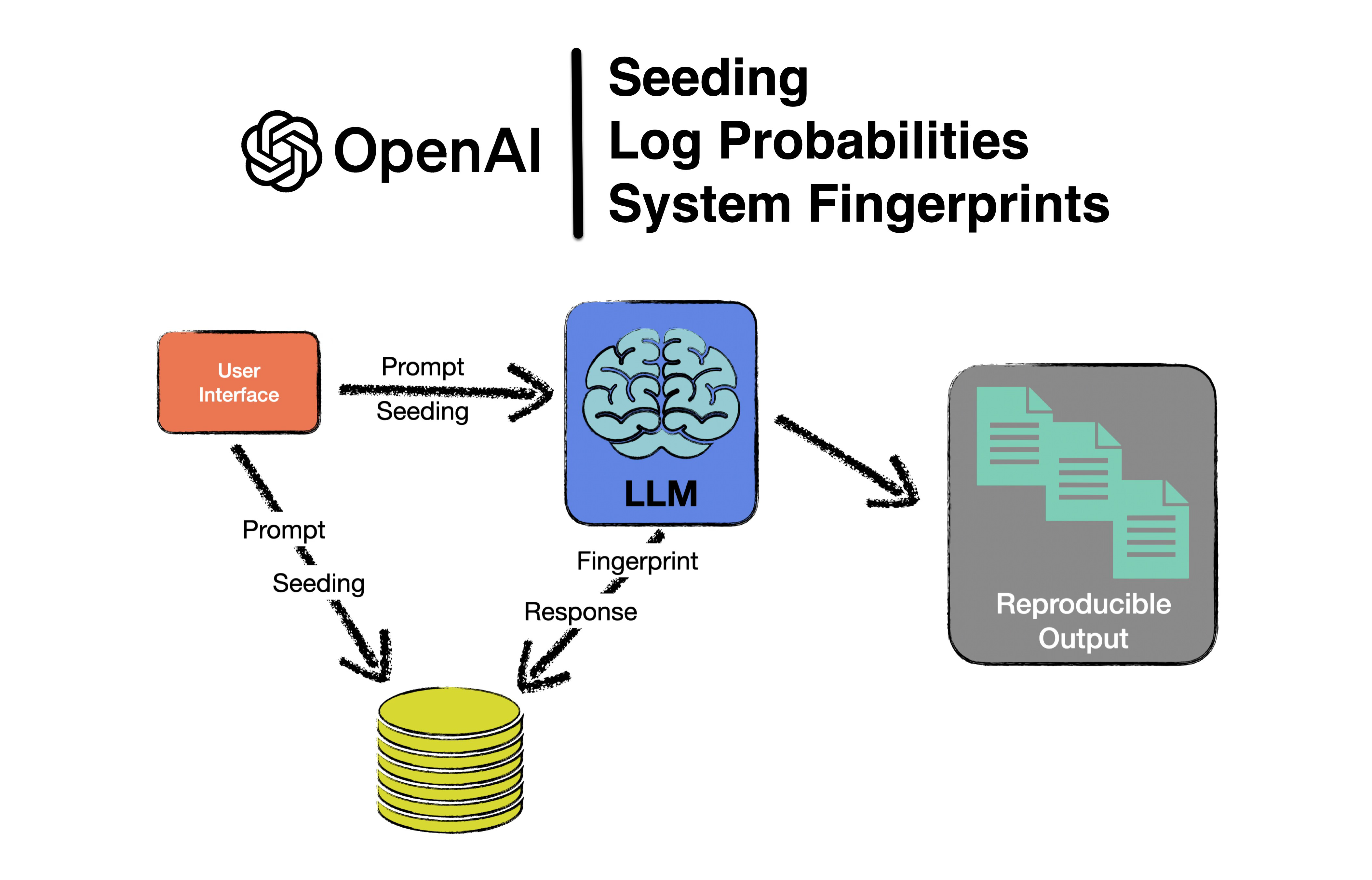
OpenAI Seeding, Model Fingerprints & Log Probabilities
Practical considerations when implementing seeding & system fingerprints.

For an overview of seeding and the advantages of reproducing output, please read a previous article I wrote.
Seed Parameter
The value assigned to the seed parameter is associated with the LLM response; and the combination of the user prompt and the seed parameter value is used to replicate the same LLM response.
The value assigned to the seed parameter is an arbitrary integer where the enterprise can decide on the logic and meaning behind the starting value and increments.
Considering a complex multi-assistant enterprise environment different seeding parameters can assist in identifying the query source, the related system etc.
In the example below I assigned an arbitrary value of 123 to the seedparameter.
To reproduce the response, the same prompt wording must be submitted with the relevant seed parameter which was assigned to the specific query.
Hence the prompting of the LLM needs to be seeded upfront, in order to track-back and reproduce or reuse the interaction.

This implies that for each interaction, a seed reference number needs to be generated and stored with the prompt submitted in order to be able to replicate the response.
When combining the prompt with the seed reference, the response can be replicated. However, once the prompt changes the seed value is ignored and the prompt is addressed by the LLM with a new response.
It would be interesting to know to what degree the user prompt can deviate before the seed parameter is ignored and a new response is generated.
System Fingerprint
Saving the seeded user prompt will most probably not suffice if underlying changes take place in the model.
To help track OpenAI environmental or model changes, OpenAI is exposing a system_fingerprint parameter and value. If this value changes, different outputs will be generated due to changes to the OpenAI environment.
Hence saving the generated output from the LLM and the system_fingerprintwith the seed information is important. Should the system_fingerprint be different, then most probably the LLM response will change.
Below is an example fingerprint value:
"system_fingerprint": "fp_44709d6fcb"This fingerprint represents the backend configuration that the model runs with and can be used in conjunction with the seed request parameter to understand when backend changes have been made that might impact determinism.
Considering the image below, the responses from the OpenAI end-point do return the parameter system_fingerprint, but it has a value of None.
This feature is in beta and will most probably be populated in the near future.

Log Probabilities
OpenAI is also launching a feature to return the log probabilities for the most likely output tokens generated by GPT-4 Turbo and GPT-3.5 Turbo in the next few weeks, which will be useful for building features such as autocomplete in a search experience.
Considerations
Seeding
Being able to reproduce LLM output is a valuable feature, it’s tantamount to a caching feature. But it does necessitate the overhead of architectural changes and additional data storage.
Fingerprints
When seeding is implemented, a process of comparing system fingerprints at certain times will also be required. This is to ensure that even though the correct user input and seeding are sent to the LLM, the response might be unexpected due to a change in the fingerprint.
Also, even if seeding is not implemented, being alerted when the system fingerprint changes allows for timely application inspection.
Lastly, a human-in-the-loop process can be used, with a human inspecting LLM responses and flagging generated responses which need to be reproduced.
It would be convenient to somehow be alerted to system changes, or at least have an overlap of fingerprints, where an older fingerprint is valid for a short period of time and can be referenced while the new fingerprint is tested.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.