Phi-3 Is A Small Language Model Which Can Run On Your Phone
Phi-3 is a family of small language models with short & long context lengths.


Introduction
Choosing the right language model depends on an organisation’s specific needs, task complexity, and available resources.
Small language models are ideal for organisations aiming to build applications that run locally on a device (rather than in the cloud).
Some argue that Large language models are better suited for applications requiring the orchestration of complex tasks, advanced reasoning, data analysis, and contextual understanding.
Small language models provide potential solutions for regulated industriesand sectors needing high-quality results while keeping data on their own premises.
Latency refers to the delay in communication between Large Language Models (LLMs) and the cloud when retrieving information to generate answers to user prompts. In some use-cases cases, makers can prioritise waiting for high-quality answers, while in others, speed is crucial for user satisfaction. However, for conversational experiences, latency is a non-negotiable.
Cost is also a consideration that makes the use of SLMs very attractive.
Back To Phi-3
Small Language Models (SLMs), which can operate offline, significantly broaden AI’s applicability.
What we’re going to start to see is not a shift from large to small, but a shift from a singular category of models to a portfolio of models where customers get the ability to make a decision on what is the best model for their scenario .~ Source
There are a number of features which are part and parcel of Large Language Models. For instance Natural Language Generation, dialog and conversational context management, reasoning and knowledge.
The knowledge portion is not being used to a large degree as RAG is used to inject contextual reference data at inference. Hence Small Language Models (SLMs) are ideal, even though they lack being knowledge intensive.
Seeing that the knowledge intensive nature of LLMs are not used in any-case.
The model simply does not have the capacity to store too much “factual knowledge”, which can be seen for example with low performance on TriviaQA.
However, we believe such weakness can be resolved by augmentation with a search engine. ~ Source
Another limitation related to the model’s capacity is that the model is primarily restricted to English.
Practical Use
Below is an example of how anyone can interact with the Phi-3 small language model. Within HuggingFace’s HuggingChat, anyone can go to settings and under models select the Phi-3 model.
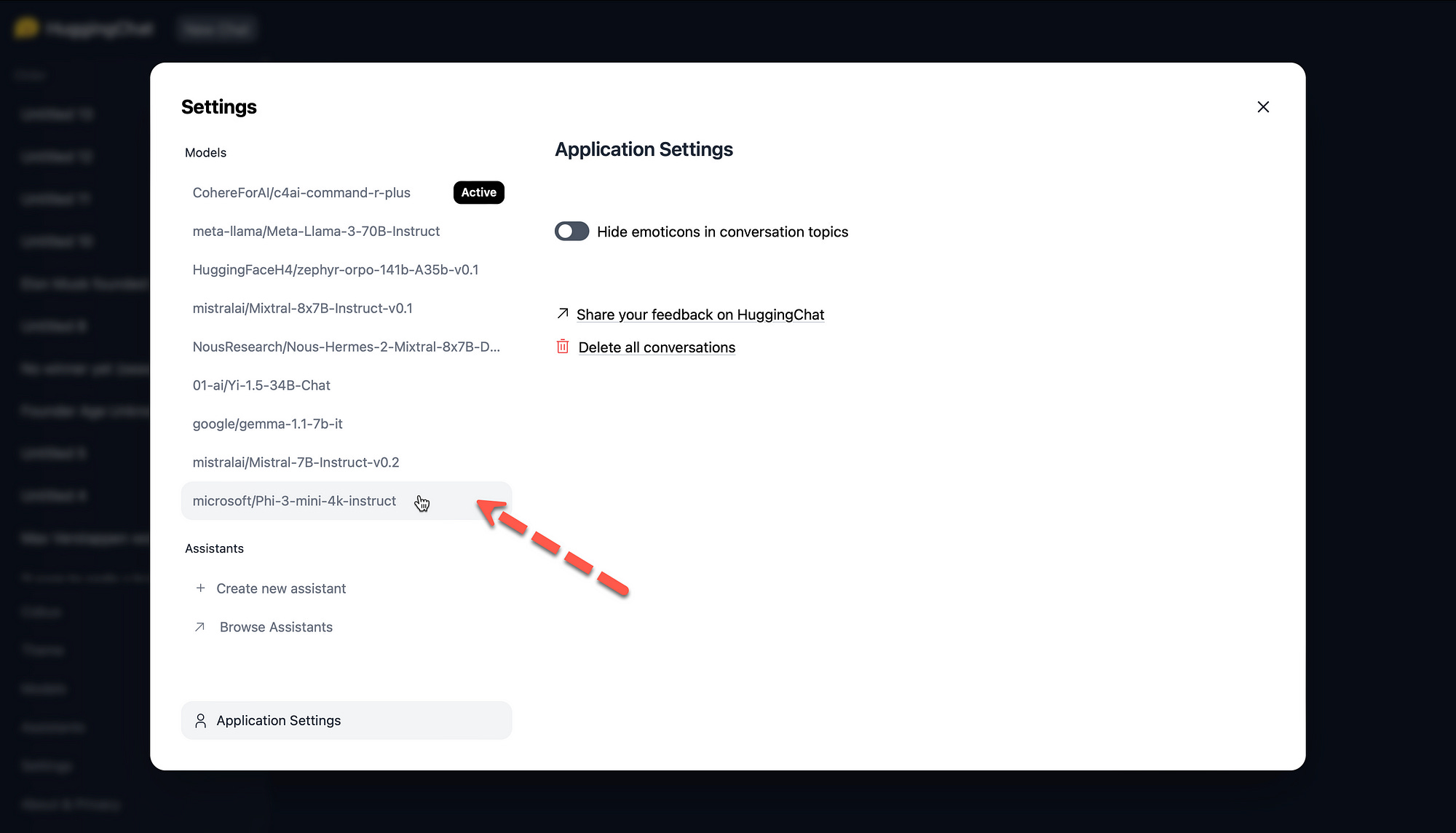
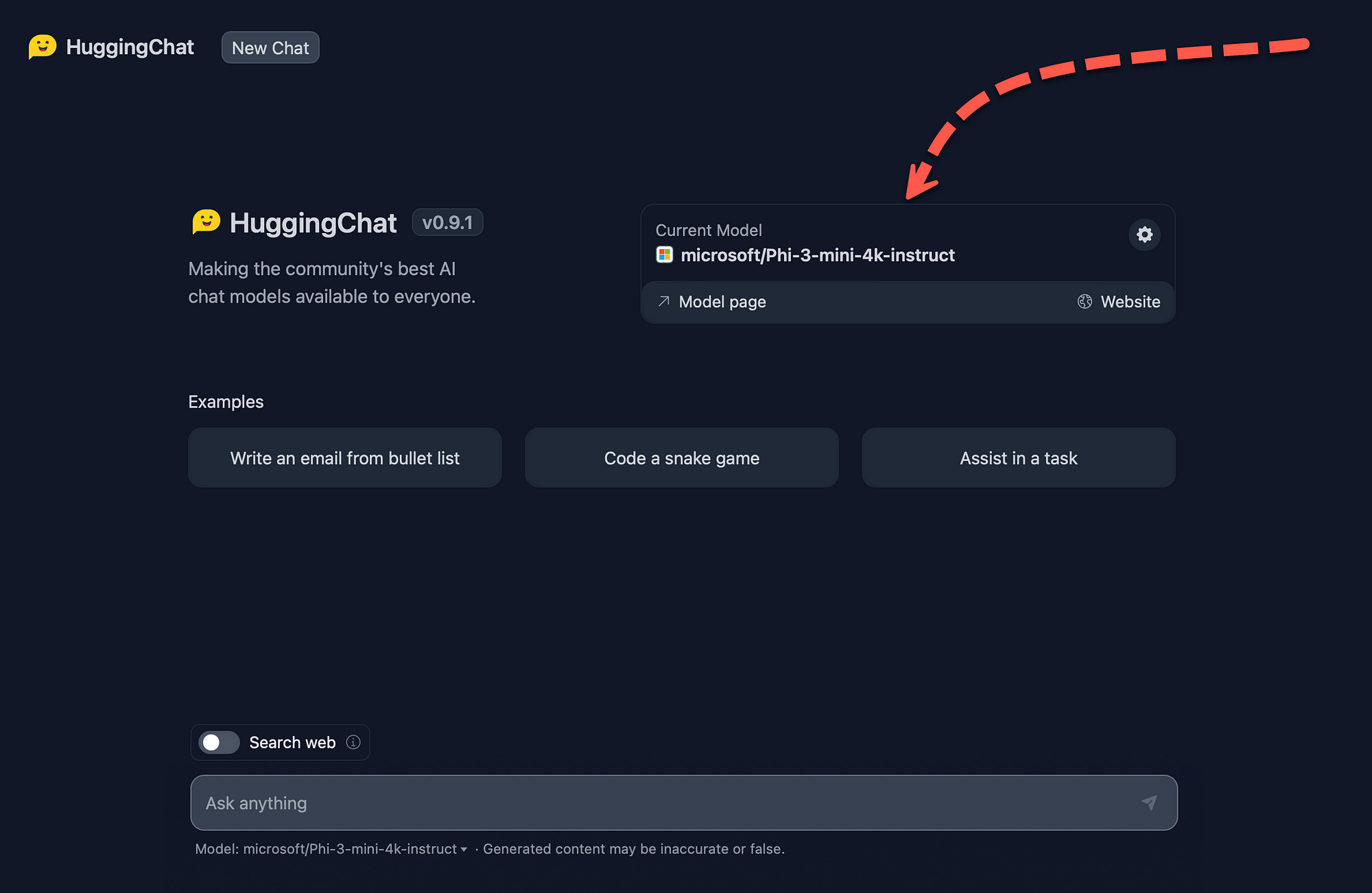
Once settings are closed, the model is shown in the chat window, and the user can chat with the model.
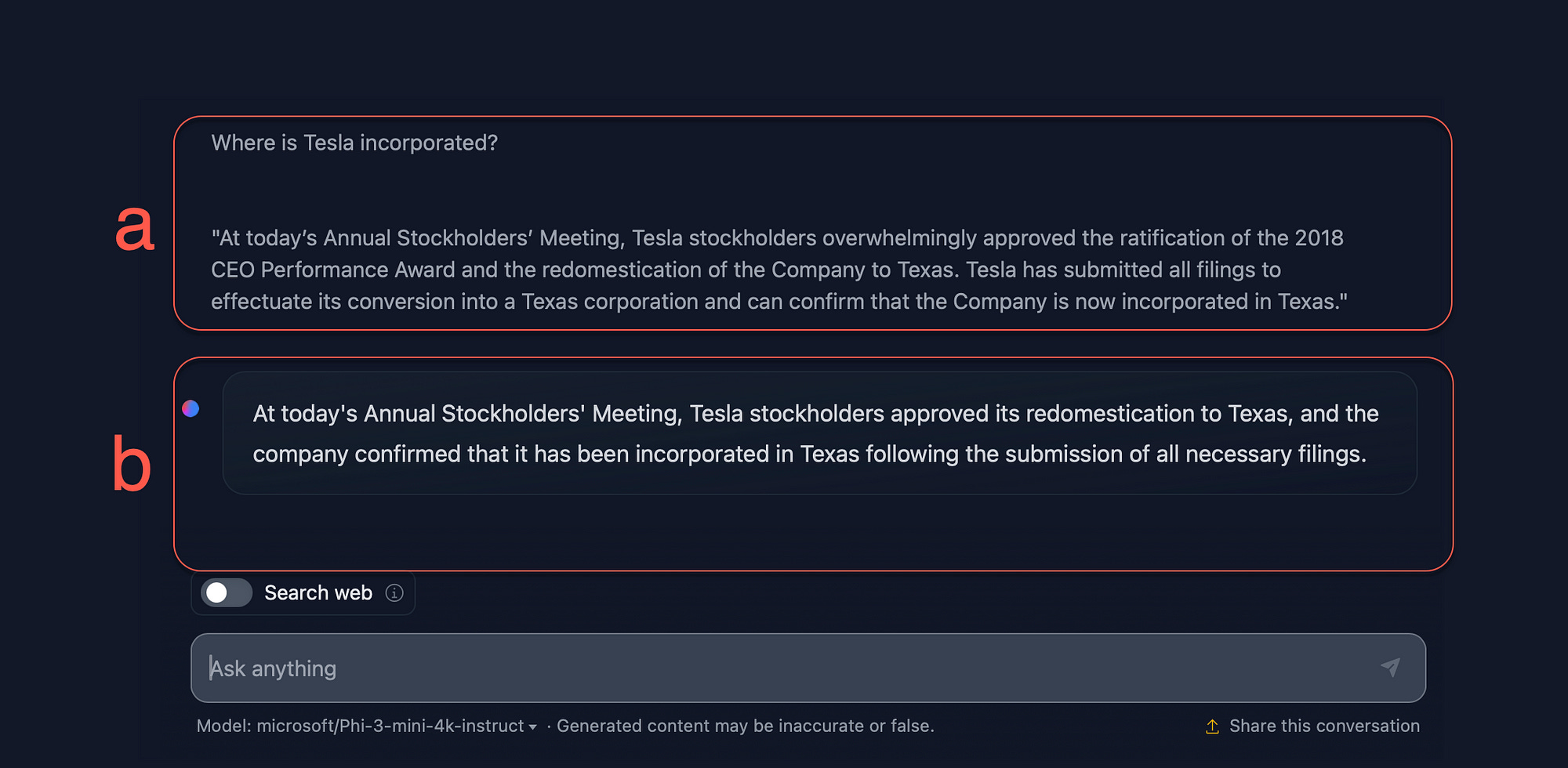
Considering the image below, a question is asked (a)Where is Tesla incorporated? with contextual reference data at the bottom.
The SLM returns a factual accurate response (b) based on the contextual reference data supplied.
Phi-3 Training
Phi-3 exemplifies a model trained on:
very granular data,
composed of heavily filtered,
publicly available web data &
synthetic data.
The model is further aligned for robustness, safety, and chat format.
There is now immense focus on optimising the functionality and performance of models running locally, rather than just scaling up their size.
It has been shown that combining LLM-based filtering of public web data with LLM-created synthetic data enables smaller language models to achieve performance typically seen only in much larger models.
For instance, the previous model, Phi-2 (with 2.7 billion parameters), matched the performance of models 25 times larger, trained on regular data.
With its small size, Phi-3-mini can easily run locally on a modern phone, yet it achieves quality on par with models like Mistral 7B and GPT-3.5.

Phi-3-mini is a highly capable language model designed to run locally on a cell phone, thanks to its compact size and efficient quantisation to 4-bits, which reduces its memory footprint to approximately 1.8GB.
Tested on an iPhone 14 with an A16 Bionic chip, it operates natively and fully offline, achieving speeds of over 12 tokens per second.
The model features a default context length of 4K tokens and is already chat fine tuned. Its training is divided into two phases:
Involves a variety of web sources to teach the model general knowledge and language understanding.
Integrates more heavily filtered web data from Phase 1 with synthetic data to enhance logical reasoning and niche skills.
Post-training of Phi-3-mini involves two stages:
1. Supervised Fine-Tuning (SFT): Utilises highly curated, high-quality data across diverse domains such as math, coding, reasoning, conversation, model identity, and safety. Initially, the data comprises English-only examples.
2. Direct Preference Optimisation (DPO): Focuses on chat format data, reasoning, and responsible AI efforts to steer the model away from unwanted behaviours by using these outputs as “rejected” responses.
These processes enhance the model’s abilities in math, coding, reasoning, robustness, and safety, transforming it into an AI assistant that users can interact with efficiently and safely.
In Closing
NLU
Considering the use of NLU engines in chatbots, initially there were NLU providers, followed by a whole host of open-sourced NLU engines.
Subsequently all chatbot providers had their own NLU engine. NLUs could run locally on PCs and eventually lived off-line on the edge (ie Snips/Sonos).
Other changes included incremental training of NLU models, small amounts of training data were required for training and automated processes to augment training data.
Language Models
Language models are going through a very much parallel process. For instance, we are not using the knowledge intensive nature of LLMs and opting to leverage all the other elements (reasoning, NLG, dialog turn and context management, etc) via RAG.
Due to this fact, Small Language Models (SLMs) can also suffice. Now SLMs are not only propriety but rather open-sourced and freely available. SLMs can also run locally on PCs and handsets.
And as mentioned in the study by Microsoft, the context of each user within their phone will act as a type of RAG.
I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.