Prompt Editing Based On User Feedback
One failure identified in the use of Large Language Models (LLMs) is the LLM misunderstanding user intent. For improved user intent detection two elements are required; disambiguation and context.

In order to solicit highly accurate and granular responses from the LLM based on user input, two elements are important; context and disambiguation.
Disambiguation is an exceptional tool to establish context and store context for future use.
Context
Large Language Models are able to learn in-context via a number of examples which acts as demonstrations, also referred to as few-shot learning.
With human language in general and LLMs in specific, it is of utmost importance to establish context. When a few-shot learning approach is followed via Prompt Engineering, for LLMs, an input specific contextual reference can be established via an avenue like Retrieval Augmented Generation (RAG)
A practical approach to establish context is to create different context classes based on the UI domain, these classes or classifications are also known as intents.
One challenge both NLU & LLMs share is the establishment of user intent & context.
Chatbot disambiguation is an important step to offload functionality to the user, and allow the user to disambiguate their input based on a set of applicable options.
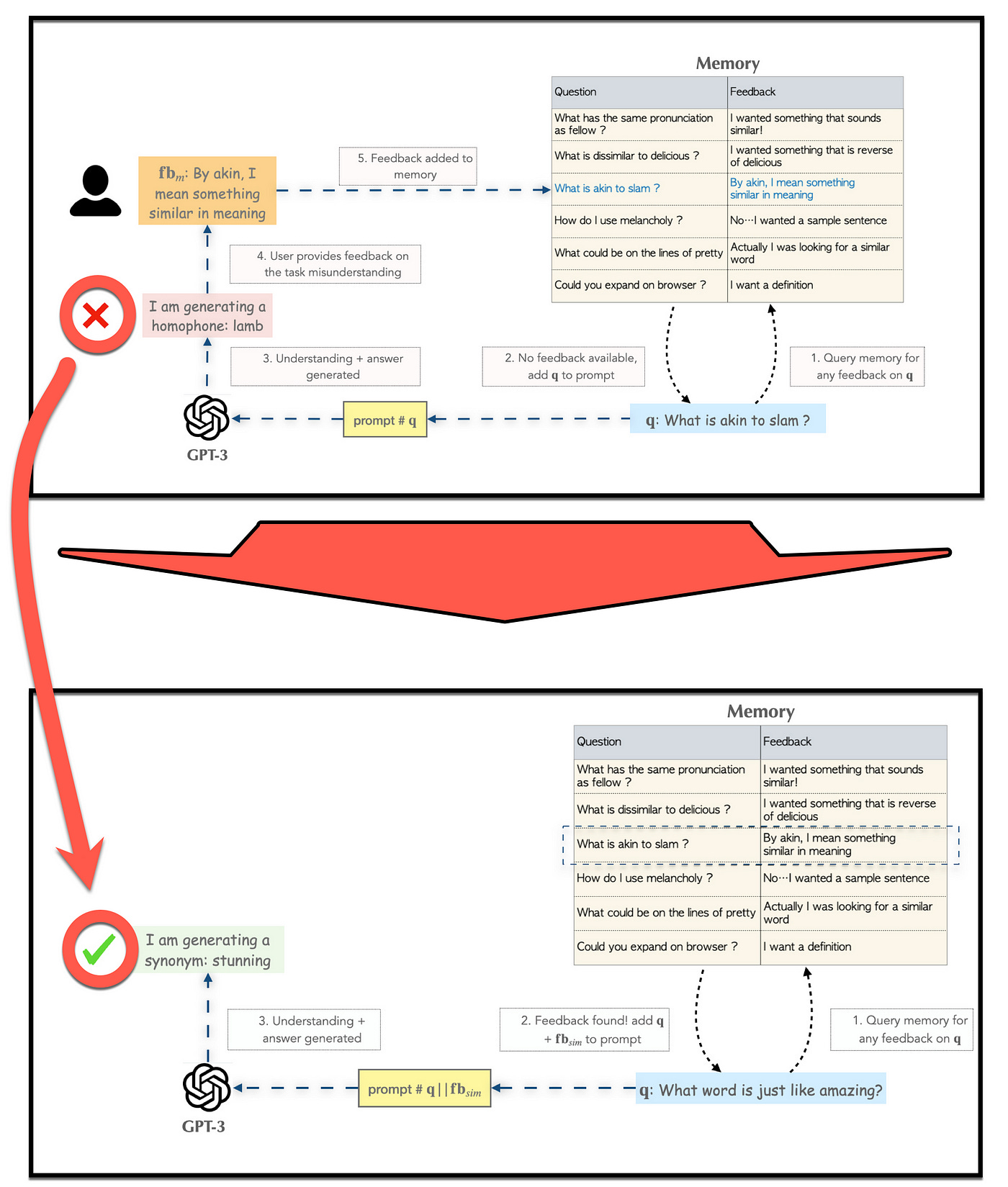
The goal of this study is to allow users to correct such errors directly through interaction, and without retraining, by injecting the knowledge required to correct the model’s misunderstanding.
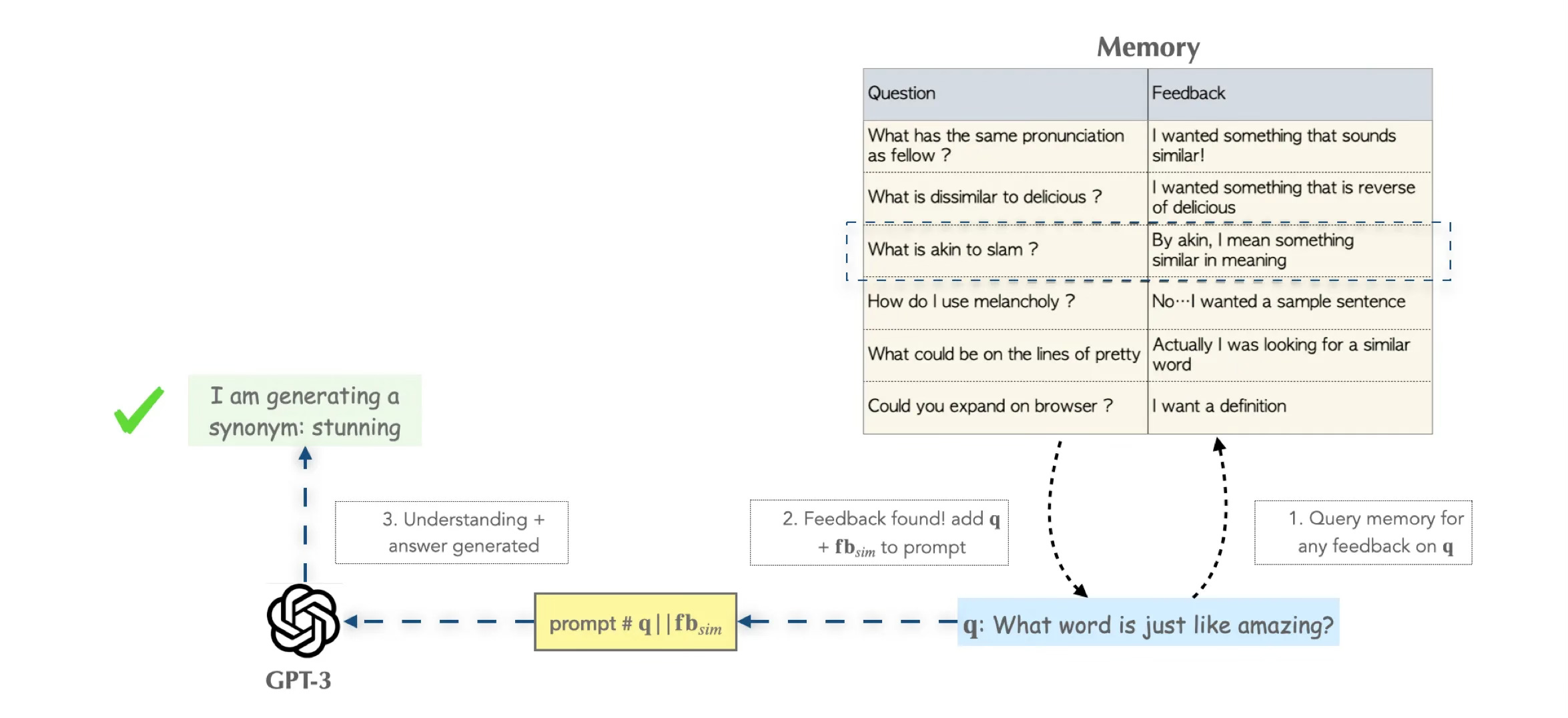
The proposed solution checks if the model has made a similar mistake previously by querying the memory.
A few-shot prompting approach is followed by adding user feedback to the prompt. This approach was tested by making use of GPT-3 with few-shot prompting; with the prompt consisting of a prefix containing a few input/output “training” examples of the task.
Our work can be seen as a form of retrieval-augmented QA. — Source
The study also states that LLMs can perform a task based on directinstruction rather than examples. This phenomenon of direct instruction to the LLM as apposed to giving the LLM examples to emulate has emerged in recent prompt engineering studies.
Our work extends this by adding an adaptive component when those instructions are misinterpreted. While it may not be possible for a user to provide meaningful feedback on the output itself, giving feedback on the understanding of the instruction is more feasible.
The study also defines two categories of understanding; Task Instruction Understanding and Task Nuanced Understanding.
As seen below:

The second point “task nuanced understanding” has been addressed to some degree by the introduction of sub-intents and nested intents in NLU.
In Closing
The paper calls their user input based RAG implementation MemPrompt; which allows users to interact and improve a model without fine-tuning.
A key differentiator of this approach is to not just answer queries, but also understand the user intent and providing an avenue for feedback for th user.
The best avenue of feedback would be real-time in the applicable dialog turn and hence by implication the same channel.
The research shows that deployed systems with fixed large-language models can still be improved by interacting with end-users and storing their responses, potentially improving LLM performance and broadening their utility.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.