Prompt Engineering, OpenAI & Modes
How can prompt engineering be used to stop LLM hallucination and what defines a good LLM prompt? How are OpenAI’s modes changing this?


Prompts and prompt engineering are integral to successful Large Language Model (LLM) implementations. The beauty of LLMs are the variations in response, creating a sense of liveness…. However, these variations can become too big and turn into false and inaccurate data. This phenomenon is often referred to as hallucination.
Prompts can be improved via:
Supervision & Observability
Accurate Prompt Compilation
Prompt Structure
Supervision & Observability
Stephen Broadhurst presented a very good talk recently at the European Chatbot Summit on supervision and observability from a LLM perspective. You can read more about the basic principles here.
Accurate Prompt Compilation
For a LLM based, real-time conversational interface (chatbot/voicebot), a few-shot approach can be followed to give the LLM just enough context and guidance to respond accurate within the current dialog context.
The challenge is constituting/compiling the prompt accurately in real-time from often disparate data sources, for submission to a LLM.
You can read more about the architecture for such an implementation here.
Prompt Structure
Prompt structure and compilation is of utmost importance. You can read more about basic prompt engineering principles here.
Text Generation Is A Meta Capability Of Large Language Models & Prompt Engineering Is Key To Unlocking It. You cannot talk directly to a Generative Model, it is not a chatbot. You cannot explicitly request a generative model to do something. But rather you need a vision of what you want to achieve and mimic the initiation of that vision. The process of mimicking is referred to as prompt design, prompt engineering or casting.
Prompts need to hold context and be contextually accurate. A good basic structure is shown below:

A Python example of how such a prompt will look like for an OpenAI implementation:
prompt = """Answer the question as truthfully as possible using the provided text, and if the answer is not contained within the text below, say "I don't know"
Context:
The men's high jump event at the 2020 Summer Olympics took place between 30 July and 1 August 2021 at the Olympic Stadium.
33 athletes from 24 nations competed; the total possible number depended on how many nations would use universality places
to enter athletes in addition to the 32 qualifying through mark or ranking (no universality places were used in 2021).
Italian athlete Gianmarco Tamberi along with Qatari athlete Mutaz Essa Barshim emerged as joint winners of the event following
a tie between both of them as they cleared 2.37m. Both Tamberi and Barshim agreed to share the gold medal in a rare instance
where the athletes of different nations had agreed to share the same medal in the history of Olympics.
Barshim in particular was heard to ask a competition official "Can we have two golds?" in response to being offered a
'jump off'. Maksim Nedasekau of Belarus took bronze. The medals were the first ever in the men's high jump for Italy and
Belarus, the first gold in the men's high jump for Italy and Qatar, and the third consecutive medal in the men's high jump
for Qatar (all by Barshim). Barshim became only the second man to earn three medals in high jump, joining Patrik Sjöberg
of Sweden (1984 to 1992).
Q: Who won the 2020 Summer Olympics men's high jump?
A:"""
openai.Completion.create(
prompt=prompt,
temperature=0,
max_tokens=300,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
model=COMPLETIONS_MODEL
)["choices"][0]["text"].strip(" \n")Other variations on prompt structure are:
Based on the context provided:
Relevant facts:
{Add relevant facts and context here}
Conditions:
{Place any relevant conditions here}
Answer:or
Based on the context provided:
Relevant facts:
{Add relevant facts and context here}
Reasoning:
{Add reasoning and conditiosn here}
Answer:Structures like these instructs the LLM on relevant context and facts, reasoning to use and if any conditions apply.
OpenAI is also enforcing template structure via their playground, consider the Python code below for the OpenAI Edit Mode:
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
response = openai.Edit.create(
model="text-davinci-edit-001",
input="We is going to the market.",
instruction="Fix the grammar.",
temperature=0.7,
top_p=1
)In the code (above) you will see the prompt structure being enforced for model, input and instruction.
Here are three playground views, below you seen the OpenAI Chat Mode template:

The OpenAI Insert Mode or template:

And lastly the Edit Mode:

Safety
OpenAI is on a quest to improve safety, quality and consistency when it comes to LLM results.
Safety is being addressed via ChatML, especially considering prompt injection attacks.
This approach is adding structure to prompts, this not only negates prompt injection attacks, as mentioned earlier.
But, adding good structure to prompts (prompt engineering), hallucinationcan be largely negated.
Below you see the format shown earlier, but this time the OpenAI ChatML structure is imposed in it:
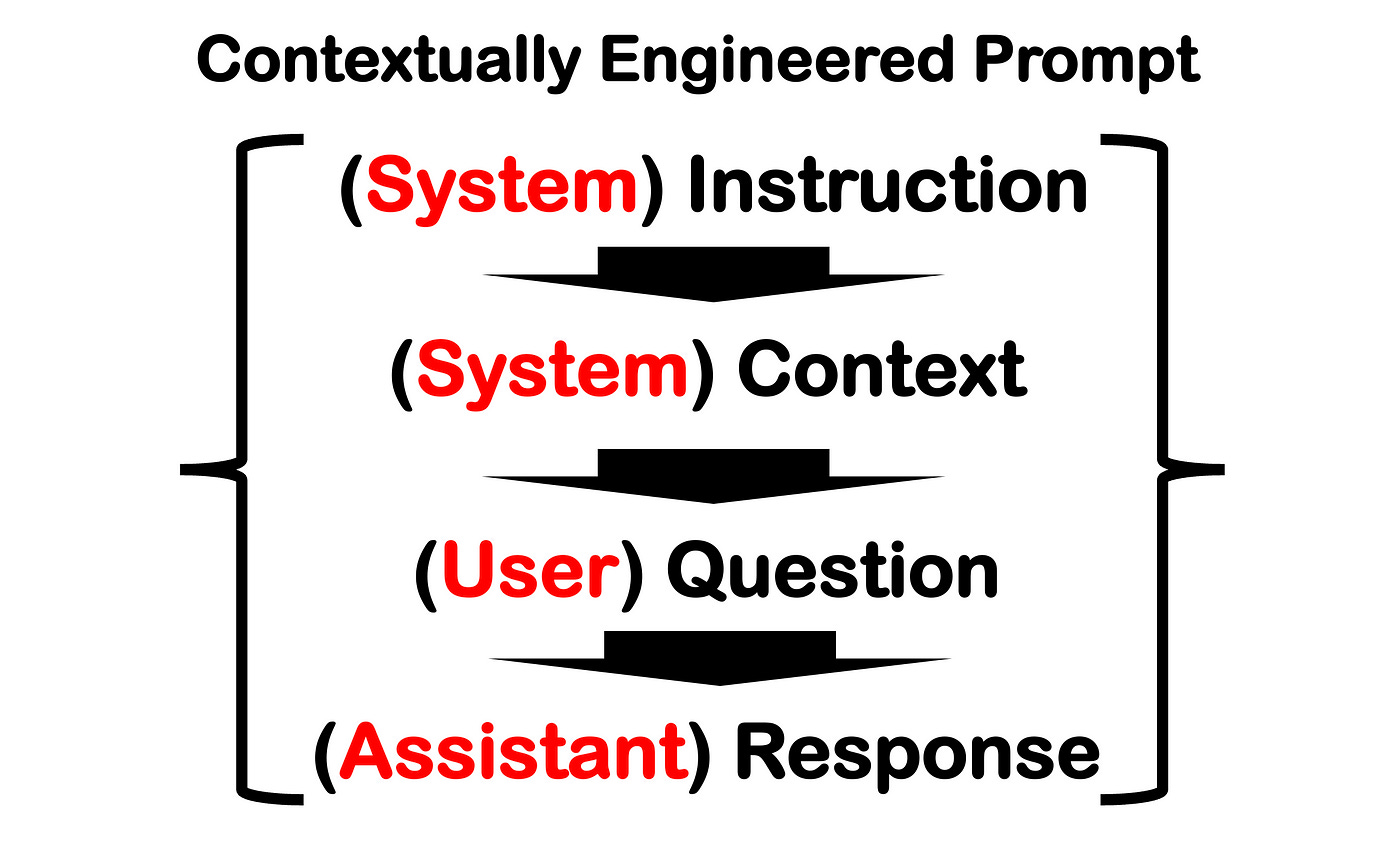
And below how the chat mode or template will look in Python code:
[{"role": "system",
"content" : "You are ChatGPT, a large language model trained by OpenAI. Answer as concisely as possible.\nKnowledge cutoff: 2021-09-01\nCurrent date: 2023-03-02"},
{"role": "user",
"content" : "How are you?"},
{"role": "assistant",
"content" : "I am doing well"},
{"role": "user",
"content" : "What is the mission of the company OpenAI?"}]
⭐️ Please follow me on LinkedIn for updates on Conversational AI ⭐️
I’m currently the Chief Evangelist @ HumanFirst. I explore and write about all things at the intersection of AI and language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces and more.

