

Prompt-RAG: Vector Embedding Free Retrieval-Augmented Generation
Prompt-RAG certainly has limitations, but in selected instances, Prompt-RAG will serve well as an alternative to the conventional vector embedding RAG methods.


Introduction
Prompt-RAG is a RAG-like, vector database / embeddings free approach to optimise Large language Models (LLMs) for domain specific implementations.
RAG requires data to be chunked and vector embeddings in order to perform semantic search and retrieval. While Prompt-RAG does not require chunking or vector embeddings.
RAG Overview
Retrieval-Augmented Generation (RAG) combines generative features with information retrieval.
RAG is strategically designed to overcome the inherent limitations of generative models. This integration combines the resilience of a large language model (LLM) with up-to-date and contextual information.
The result is LLM responses with natural and human-like qualities while being current, precise, and contextually aligned with the given query.
In the traditional operation of RAG, the initial step involves the conversion of input queries into vector embeddings. These embeddings are then employed to retrieve pertinent data from a vectorised database.
Subsequently, the generative component of RAG utilises the retrieved external data to generate responses that are contextually informed.
Consequently, both the embedding and generative models play pivotal roles in determining the effectiveness of RAG, directly influencing the retrieval process.
Prompt-RAG
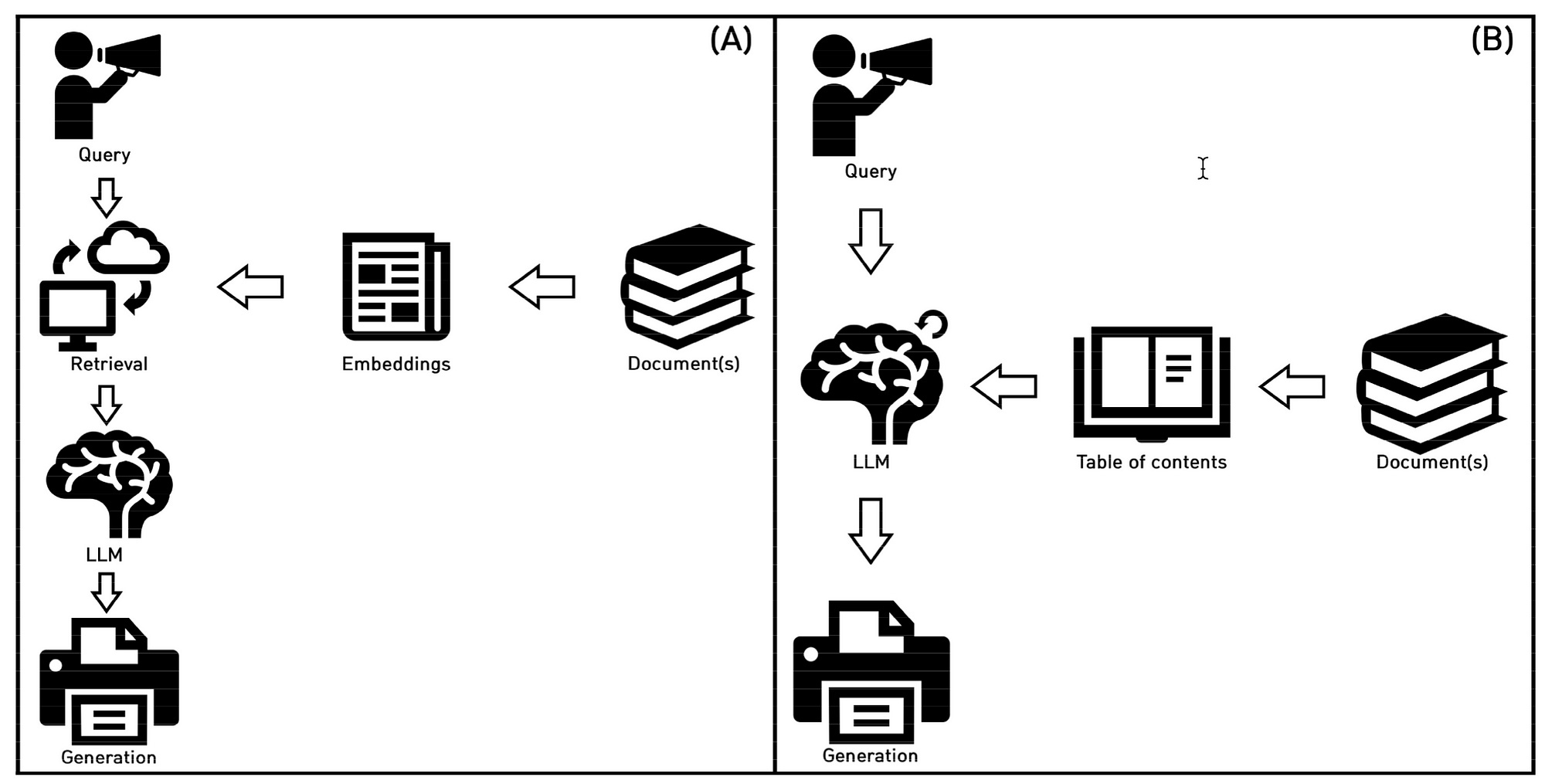
The image below shows the comparative workflows of the two RAG approaches. With (A) on the left illustrating RAG as we know it, and (B)describing the Prompt-RAG approach.
(A) is the traditional and well-established approach to vector embedding-based RAG.
(B) shows the process of Prompt-RAG; the LLM directly accesses the table of contents for creating a contextual reference, followed by generating a response with it.
Prompt-RAG Steps
Prompt-RAG consists of three steps:
Preprocessing,
Heading Selection, and
Retrieval-Augmented Generation.
Preprocessing
The first step is to create a Table of Contents (ToC) from the documents. The document or selection of the documents are related to the specific domain Prompt-RAG will be addressing.
The ideal scenario is where a ToC is already prepared, created by the author of the document. The ToC can also be manually created, or a LLM can be used to create the ToC in cases where the document structure is well defined.
The LLM context-window size plays a big part on how large the ToC and retrieved document sections will be. Token size can be reduced by formatting the document by removing elements like headers, footers, page numbers, etc.
Heading Selection
The prompt contains the user query and a ToC which is passed to the LLM.
The LLM is instructed to select the headings from the ToC which is most contextually relevant to the query.
It can happen that multiple headings are selected which can also be narrowed by summarising the text.
The number of selected headings can be set in the prompt in advance depending on the budget and the context window size of the generative model for answer generation.
An important element is for the prompt to be optimised for accurate ToC retrieval and token use efficiency.
RAG
Here portions of the document under the selected headings are retrieved and injected into the prompt as an in-context reference at inference.
The size of reference text injected into the prompt must be smaller than the context window size of the LLM.
Here again a LLM can be leveraged to summarise, truncate or somehow prune the “chunk” to suit the requirement of context window size and cost (token usage).
Sequence & Prompt Templates
The prompt to select the heading:
Current context: {history}
Question: {question}
Table of Contents: {index}
Each heading (or line) in the table of contents above represents a fraction
in a document. Select the five headings that help the best to find out the
information for the question. List the headings in the order of importance
and in the format of
'1. ---
2. ---
---
5. ---'.
Don't say anything other than the format.
If the question is about greetings or casual talks, just say
'Disregard the reference.'.”Upon selecting one or more headings, the corresponding book sections are fetched and concatenated.
The model generates an answer with the prompt below which also contains a directive to refrain from hallucinating when no relevant context is found in the reference data.
In cases where the selected headings are absent due to the query being a greeting or casual conversation, an alternative prompt without a reference section is passed to a GPT-3.5-turbo-based model, in order to reduce token usage and save on expenses.
The prompts for answer generation are shown below:
You are a chatbot based on a book called {Book Name}.
Here is a record of previous conversations:
{history}
Reference: {context}
Question: {question}
Use the reference to answer the question.
The reference above is only fractions of '<>'.
Be informative, gentle, and formal.
If you can't answer the question with the reference, just say like
'I couldn't find the right answer this time'.
Answer in {Language of Choice}:Below the prompt template without selected headings for casual queries.
You are a chatbot based on a book called {Book Name}.
Here is a record of previous conversation for your smooth chats.:
{history}
Question: {question}
Answer the question.
Be informative, gentle, and formal.
Answer in {Language of Choice}:”In Conclusion
I would say that the contribution of Prompt-RAG study is substantial, even if Prompt-RAG is not used in a standalone capacity. There are scenarios where Prompt-RAG can be used as a sub-set of a larger implementation.
There is always this tension between optimising and leveraging prompt engineering via creative means. As apposed to building a more complex framework of data management around an application. As implementations grow in usage and complexity, the latter are normally taken.
Having said this, Prompt-RAG does necessitate an application framework to manage the flow of data, vet input and output. And perform a level of data manipulation.
Traditional RAG disadvantages:
Optimising document chunk size and managing overlaps can be a challenge.
Updating chunks and embeddings as data changes to maintain relevance.
Not optimised for minority language implementations
Additional cost of running embeddings
Cumbersome for smaller implementations
Technically more demanding
Traditional RAG advantages compared to Prompt-RAG:
Scales well
More Data Centric Approach
Bulk Data Discovery and data development will remain important for enterprise implementations.
Semantic clustering is an important aspect of data discovery in general, and a good first-step into implementing RAG.
Prompt-RAG Advantages:
Well suited for smaller, less technical implementations and minority languages.
Ideal for a very niche requirement and implementation
In the case of a chatbot, certain intents can be routed to a Prompt-RAG implementation
Simplification
Can serve as a first foray into full RAG implementations
Non-gradient approach
Inspectability and Observability
A data discovery & data design tool aimed at optimising Prompt-RAG can add significant value.
Prompt-RAG Disadvantages:
Data design is still required.
Context window size is an impediment.
Token usage and cost will be higher; this needs to be compared to embedding model token cost.
Scaling and introducing complexity will demand a technical framework.
Dependant on LLM inference latency and token usage cost.
Content Structure needs to be created. The study largely focusses on documents which already has a Table of Contents.

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.