RAG & Fine-Tuning

I’m currently the Chief Evangelist @ HumanFirst. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Build Frameworks, natural language data productivity suites & more.
Introduction
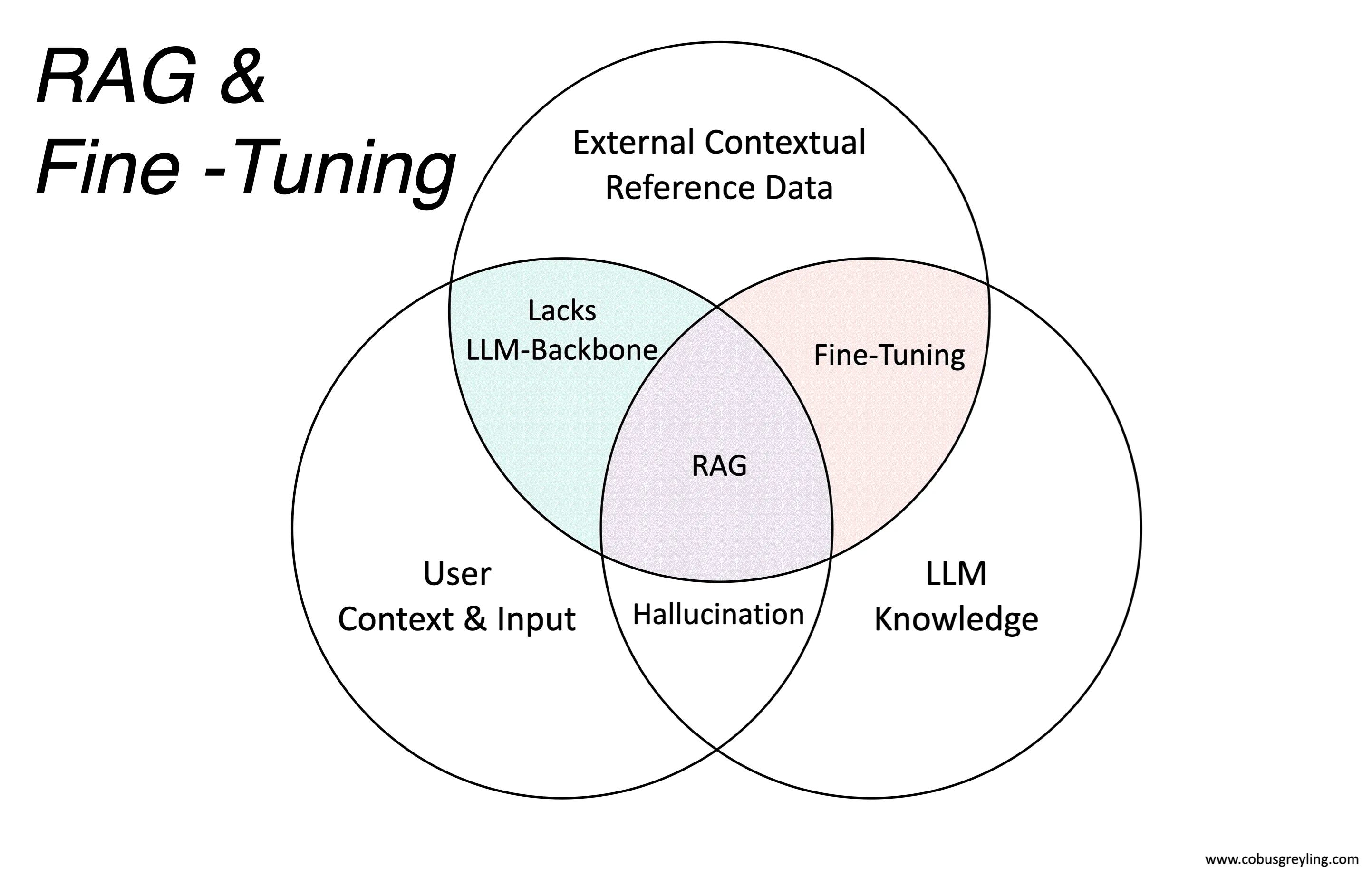
Starting from basics, considering the Venn Diagram above, there are three data sources in terms of LLM-based applications:
User Context & Input
External Contextual Reference Data
LLM Knowledge
The user input is underpinned by a certain contextual reference defined by place, time and an intent the user wants to fulfil. In a recent article I considered true ambiguity and the process of disambiguation. Together with user context and intent. Input can also be from other sources via API calls, like CRMs, previous conversations/interactions, etc.
External Contextual Reference Data is at the heart of RAG, where the right amount of contextual reference data is injected into the prompt at inference.
LLM Knowledge is the base of data the LLM is trained on, which has a definite time stamp in terms of recent events. It is important to note that LLMs are not immune to providing highly believable, plausible and succinct answers; which are factually incorrect.
Hallucination is when the LLM provides highly plausible, concise, and seemingly credible responses that are factually inaccurate.
When a contextual reference is added via RAG the chances of introducing hallucination or ambiguity is severely limited.
The LLM Backbone is the resilience the LLM provides in terms of general knowledge, reasoning, dialog management, natural language generation and context management.
Without the LLM backbone, a significant level of resilience is inevitably compromised.
Rag & Fine-Tuning
Fine-Tuning changes the models behaviour while RAG provides external contextual data to reference at inference.
Using RAG and Fine-Tuning in tandem is an ideal solution; however the allure of RAG is that it is not as opaque as fine-tuning, easier to implement and track via visual inspection of LLM input and output.
Fine-Tuning
The LLM is fine-tuned on relevant data; the fine-tuned model can work well for industry specific implementations like medical, legal, engineering, etc use-cases.
But this fine-tuned model is also frozen in time, and without any contextual reference for each specific input, will be generally more accurate, but not tuned for each and very specific user input.
Using fine-tuning and RAG in concert is the ideal scenario.
Advantages Of Fine-Tuning Includes:
Improved quality in responses as apposed to only relying on prompting.
The model can be trained on a wider and larger array of examples, as opposed to trying to fit everything into a single prompt.
Prompts will be shorter and hence there will be a saving on tokens.
Fine-tuning and accessing fine-tuned models can be an avenue to improve latency.
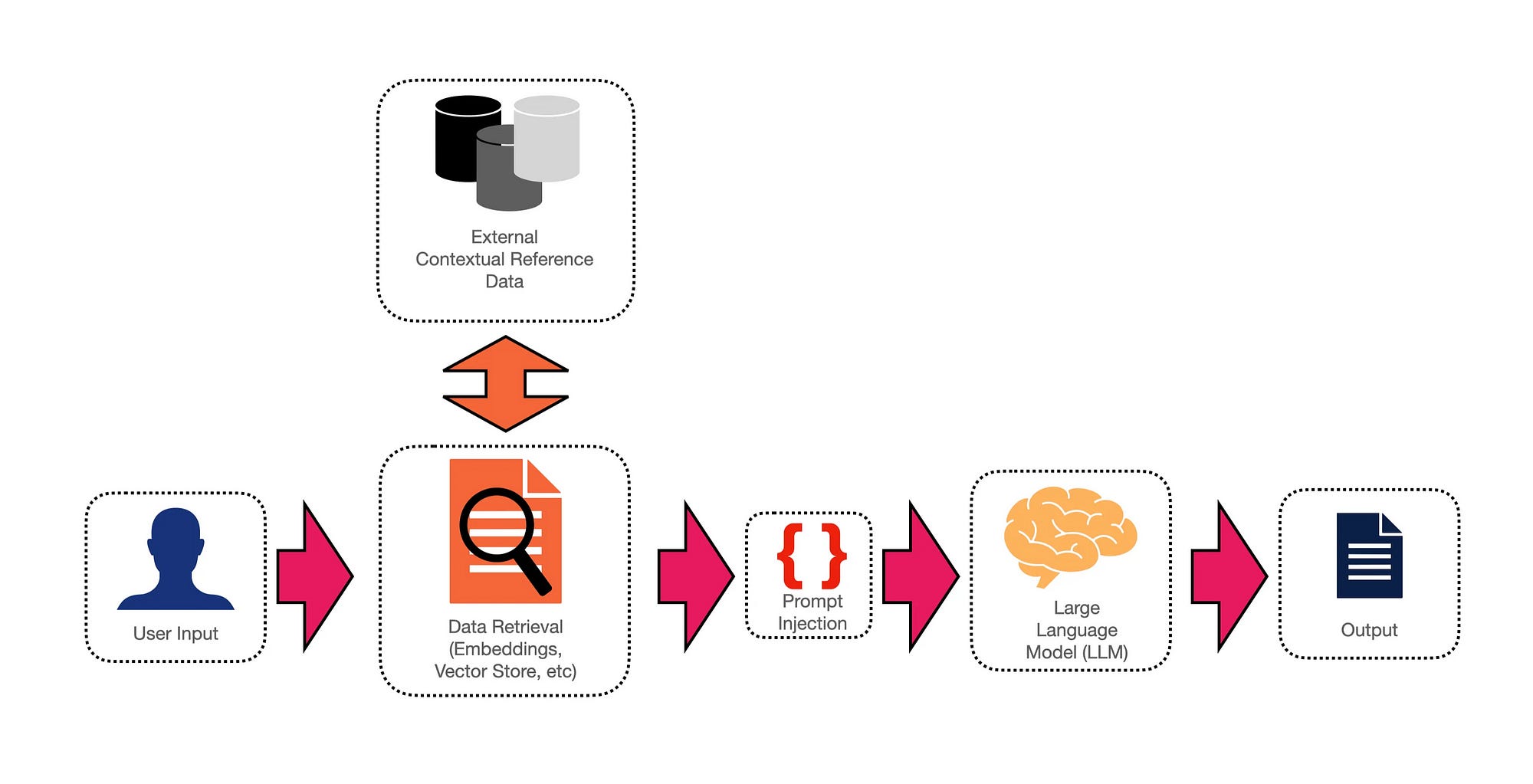
A short overview of RAG
Retrieval Augmented Generation (RAG) combines information retrieval and generative models.
By injecting the prompt with relevant and contextual supporting information, the LLM can generate telling and contextually accurate responses to user input.
Below is a complete workflow of how a RAG solution can be implemented. By making use of a vector store and semantic search, relevant and semantically accurate data can be retrieved. Read more about RAG here.