

RAG Survey & Available Research
A Survey on Retrieval-Augmented Text Generation for Large Language Models


Recap On RAG
Retrieval-Augmented Generation (RAG) combines retrieval methods with In-Context Learning (ICL) & Natural Language Generation (NLG) to overcome the static knowledge limitations of large language models (LLMs) by integrating dynamic external information.
This approach primarily targets the text domain and offers a cost-effective solution to mitigate the generation of plausible but incorrect responses by LLMs, thus improving their accuracy and reliability through the use of real-world data.
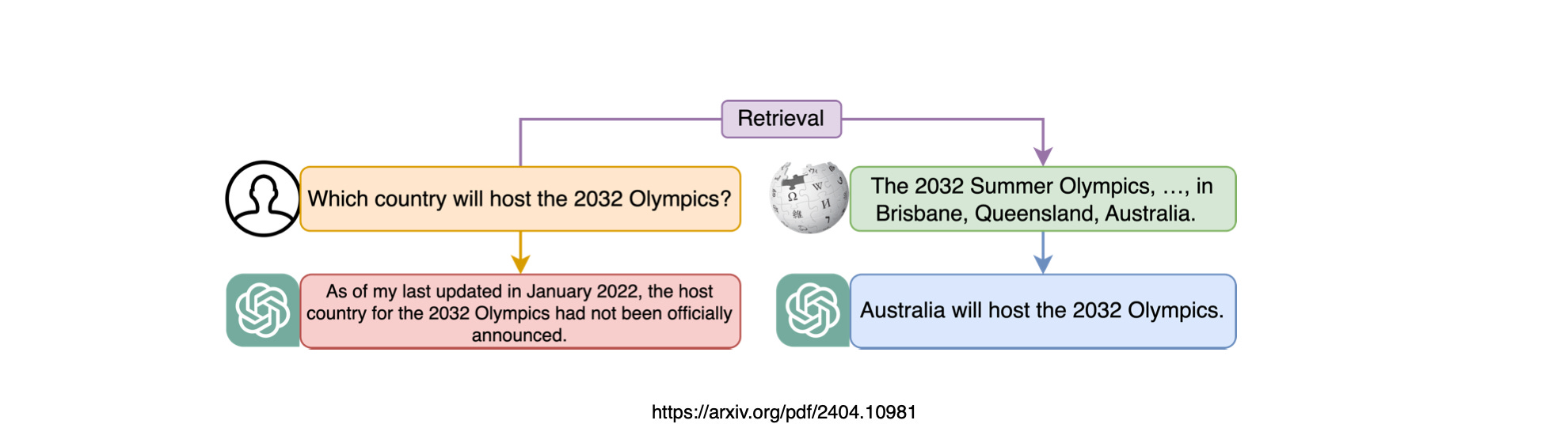
𝗥𝗔𝗚 𝗶𝘀 𝗰𝗮𝘁𝗲𝗴𝗼𝗿𝗶𝘀𝗲𝗱 𝗶𝗻𝘁𝗼 𝗳𝗼𝘂𝗿 𝗸𝗲𝘆 𝘀𝘁𝗮𝗴𝗲𝘀:
𝗣𝗿𝗲-𝗿𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹,
𝗥𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹,
𝗣𝗼𝘀𝘁-𝗿𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹, &
𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻.
It also introduces evaluation methods for RAG, addressing the challenges faced and suggesting future research directions. By offering a structured framework and categorisation, the study aims to consolidate existing research on RAG, clarify its technological foundations, and emphasise its potential to expand the adaptability and applications of LLMs.
The paper highlights how RAG can dynamically integrate up-to-date information to enhance the performance of LLMs, making them more reliable and effective in generating accurate responses, thereby broadening their practical uses in various domains.
The image below shows a basic RAG workflow, but also the sub-components liked to the four RAG steps.

The image below contains a list of all the existing research for each of RAG components.

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.