RAT — Retrieval Augmented Thoughts
Synergising RAG With Sophisticated Long-Horizon Reasoning


Introduction
Let me first start with a few general observations…
There is a tension between achieving efficiency within Generative AI applications, and accuracy in generated responses.
Efficiency in GenApp speaks to the application being responsive without any lag or time-outs. There should also not be too many components and checks in the application’s execution path.
Accuracy speaks to alignment between the output from the Generative AI App and the user’s expectation.
Accuracy is often achieved by GenApp architectures by employing multiple LLM interactions and inference passes. Add to this, comparing different responses and selecting the best response.
Obviously when introducing these measures to achieve a high level of accuracy, this comes at the detriment of efficiency.
Hence a balance needs to be struck between efficiency and accuracy.

RAT — Two Step Approach
Retrieval Augmented Thoughts (RAT) is a simple yet effective prompting strategy that combines Chain-of-Thought (CoT) prompting and retrieval augmented generation (RAG) to address long-horizon reasoning and generation tasks.
Hence the zero-shot chain-of-thoughts (CoT) generation produced by LLMs is combined with RAG. With the thoughts as queries, and causally revising the thoughts & generating the response progressively.
RAT is a zero-shot prompting approach, and has demonstrated significant advantages over:
vanilla CoT prompting,
RAG, and
Other baselines
on challenging code generation, mathematics reasoning, embodied task planning, and creative writing tasks.
The results indicate that combining RAT with these LLMs elicits strong ad- vantages over vanilla CoT prompting and RAG approaches. ~ Source
Step One
Firstly, the initial zero-shot CoT prompt produced by LLMs along with the original task prompt are used as queries to retrieve the information that could help revise the possibly flawed CoT.
Step Two
Secondly, instead of retrieving and revising with the full CoT and producing the final response at once, a progressive approach, where LLMs produce the response step-by-step following the CoT (a series of sub-tasks).
Only the current thought step is be revised based on the information retrieved with task prompt, the current and the past CoTs.
This strategy is analogous to the human reasoning process:
Utilise outside knowledge to adjust step-by-step thinking during complex long-horizon problem-solving. ~ Source
Long-Horizon Manipulation
Long-horizon manipulation tasks require joint reasoning over a sequence of discrete actions and their associated continuous control parameters.
Hence the challenge of using zero-shot CoT prompting and long-horizon generation tasks. These generation tasks require multi-step and context-aware reasoning.
Factually valid intermediate thoughts could be critical to the successful completion of these tasks.
Considering the image below, the Pipeline of Retrieval Augmented Thoughts (RAT) is shown. Given a task prompt (showed as I in the figure), RAT starts from initial step-by-step thoughts (𝑇 , 𝑇 , · · · , 𝑇 ) produced by an LLM in zero-shot .
Some thought steps (such as 𝑇1 in the figure) may be flawed due to hallucination.
On the other hand, iterative revision of each thought step is possible using RAG from an external knowledge base.

Considering the image below, the image illustrates how different LLM reasoning methods are used for creative generation tasks.
Red text indicates errors or illusions in the text generated by LLM, while green text represents correct generation.
Methods without RAG often generate incorrect information with hallucination, classical RAG is highly related to retrieved content with a loose structure, and RAT-generated texts perform best in terms of accuracy and completeness.
The quantitative performance comparison for different LLM reasoning methods on complex embodied planning, mathematical reasoning, code generation, and creative generation tasks. RAT outperforms all the baselines on all tasks.

In Closing
Recently I have been doing quite a bit of writing on Agentic RAG; I believe it was LlamaIndex who coined this phrase. The notion of Agentic RAG is combining LLM-based Autonomous Agents with RAG.
Hence an Agentic RAG Agent has access to multiple lower-order sub-agents, which can also be referred to as RAG sub-tools.
This Study which conceptualises the concept of RAT (Retrieval Augmented Thought) feels like it aligns with the Agentic RAG approach.
Hence there is this convergence of different approaches to designing and building Generative Apps.
Just as complexity grew around prompts, complexity is growing around RAG. Considering the image below, we evolved from static prompts to templating, all along the point of autonomous agents with a prompt at its core.
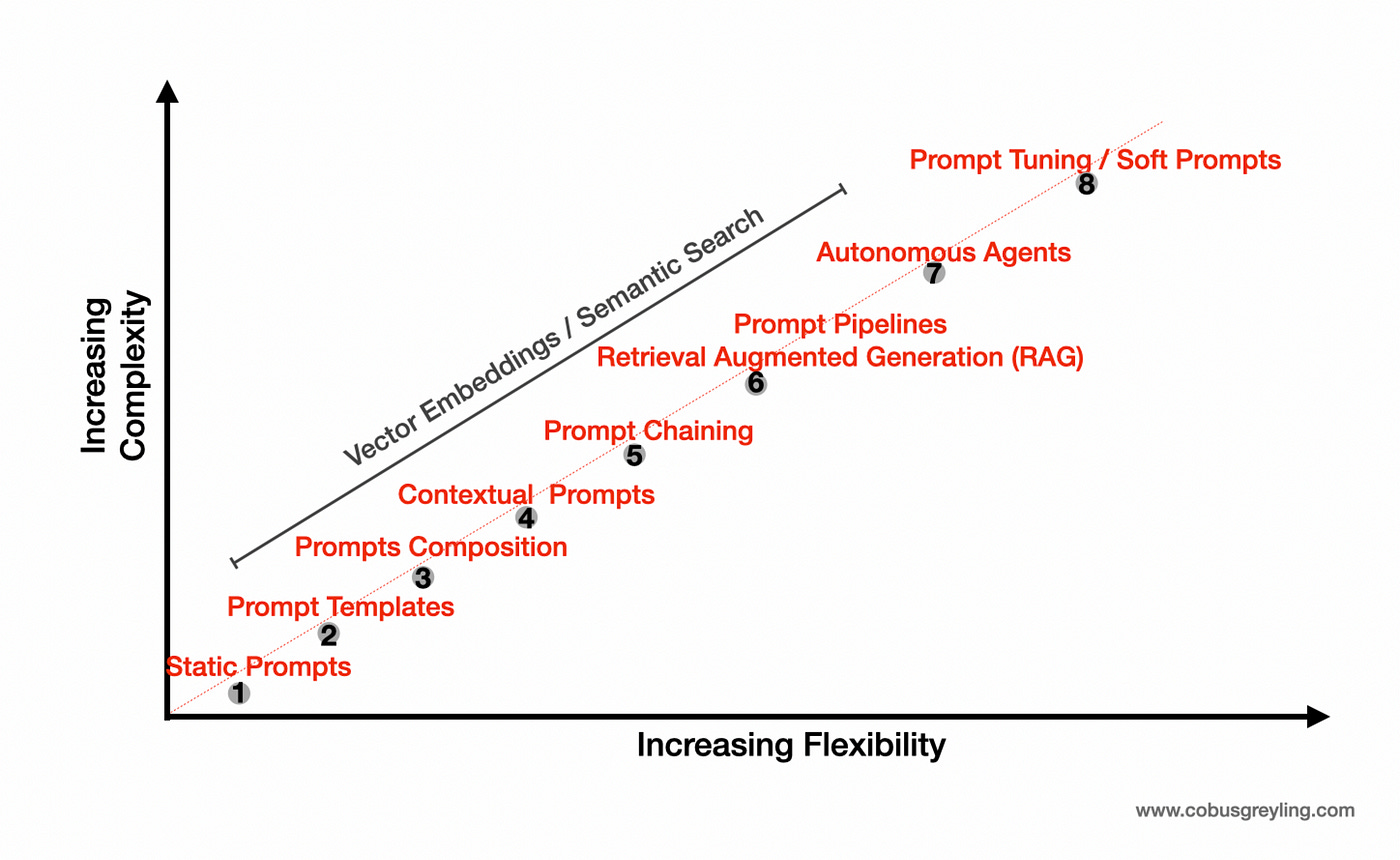
The same is happening to RAG, where innovation is taking place around core RAG implementations. This innovation obviously adds structure and complexity to RAG implementations.
And as I have mentioned, Agentic RAG will become a de facto standard.

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.