Real-World Agentic Applications
There’s been a lot of speculation about the future of AI Agents & agentic applications, much of it vague or overly optimistic.

After doing my own research and prototyping, I’ve found one way to avoid falling into the trap of false forecasts: focus on the technology we have now.
Look at how it’s evolving, the directions it’s pulling us, and build projections from that. It’s not about dreaming up distant possibilities but understanding the path that’s already being paved, with all its limits and quiet promises.
Introduction
The basic architecture of AI Agents is well-established. These agents break down complex tasks into smaller sub-tasks, creating an ad-hoc chain of actions.
At each step, the agent follows a process of “thought, action, and observation” to address or complete the sub-tasks. This iterative cycle continues until the final conclusion or answer is reached.
This dynamic and flexible approach allows AI agents to handle intricate challenges by systematically tackling each component of a task.
Application Environments
AI Agents or Agentic Applications need to operate within an environment, which can be digital spaces like mobile operating systems (for example Apple’s Ferret-UI or Microsoft’s OmniParser) or the web (WebVoyager).
These are the same environments users already engage with, positioning AI Agents as an extension of the user within these digital realms.
By existing within familiar platforms, agents can seamlessly integrate into users’ workflows, enhancing their ability to interact with and navigate these environments.
AI Agent Existence
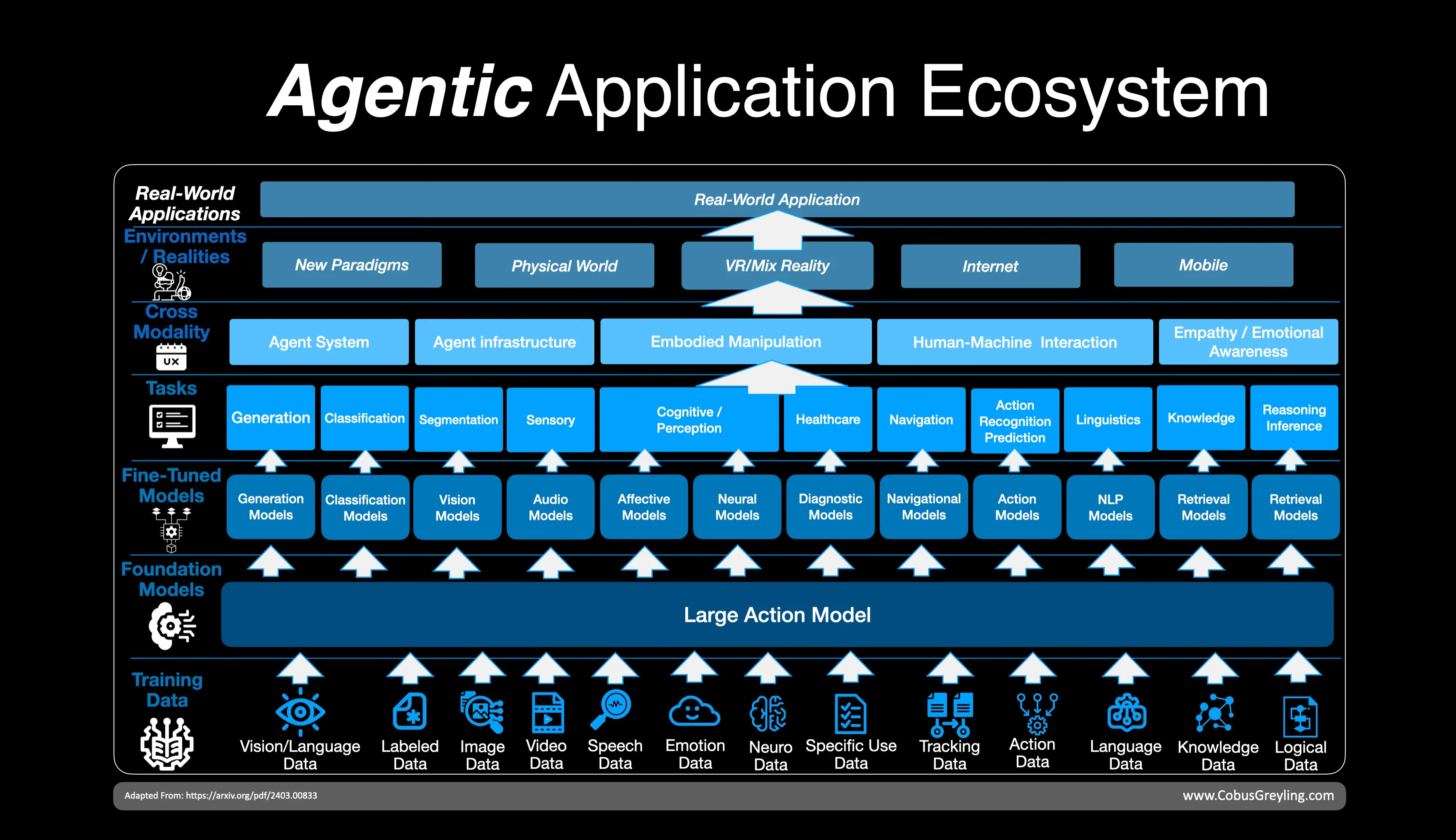
Recently, Microsoft published research aimed at establishing a foundational view of AI Agents from the ground up.
Training Data
Their proposed architecture begins with training data and highlights how data sources have evolved. This shift moves beyond simple data chunking, adopting more advanced techniques like data topologies and graph-based approaches.
By structuring data this way, Microsoft is positioning AI agents to better understand and process complex relationships within datasets, enhancing their ability to navigate and perform tasks more effectively.
Fine-tuning a large language model with a small amount of training data for a specific use case is often referred to as few-shot fine-tuning or domain-specific fine-tuning.
This process allows the model to adapt its performance to a niche or specialised task without requiring extensive new data, while preserving the general knowledge learned during its initial training. It’s an efficient way to tailor large models for specific applications with minimal additional data.
Foundation Model
A foundation model serves as the core backbone for AI agents, providing the necessary infrastructure for various tasks. Models like GPT-4o mini can be integrated into vision-enabled AI agents, such as WebVoyager, enabling these agents to process and interact with visual data alongside language tasks.
By combining the foundational capabilities of large models with domain-specific functionality, these agents can effectively navigate and perform complex tasks in diverse environments, both online and in digital systems.

Fine-Tuned Models
Model orchestration is gaining attention, with recent studies exploring how Small Language Models (SLMs) are assisting Large Language Models (LLMs) in completing tasks.
A key focus has been on using LLMs to generate bespoke, highly granular fine-tuning data, which can then be employed to train SLMs.
This approach not only enhances the efficiency of task handling but also optimises resource usage by leveraging the strengths of both model types, offering a more scalable and tailored solution for specific applications.
Environmental Realities
Environmental Realities refer to the cognitive abilities and the environments in which AI agents operate.
Currently, these agents exist primarily as digital entities, functioning within virtual environments without physical embodiment.
However, this limitation is likely to change in the near future, as advancements in robotics, sensors, and AI may enable agents to interact with the physical world, potentially bridging the gap between digital and real-world environments, allowing for more dynamic and embodied AI systems.
AI Agent Architecture
The basic AI architecture, as outlined in the study, emphasises the importance of the environment in which the agent operates. For an agent to function effectively within this environment, it requires cognitive components.
The transition from Large Language Models (LLMs) to models that integrate vision adds this cognitive layer, enabling AI agents to better perceive and interact with their surroundings.
This fusion of vision and language expands the agent’s ability to understand and process information, bridging the gap between digital tasks and more complex, real-world scenarios.

Finally
The matrix below outlines the dual actions and environments within which AI agents operate.
It splits the agent’s capabilities across virtual & physical environments and between manipulation & intent actions.
In virtual environments, AI agents decompose tasks, reason, and navigate, such as selecting tools to complete tasks.
In physical environments, they assist in real-world contexts, handling tasks like manufacturing.
For intent action, agents detect user intentions through inputs like text or gestures, whether in digital or physical spaces, while personal assistants with physical autonomy extend these abilities to real-world interactions, emphasising empathy and advanced navigation capabilities.

Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. From Language Models, AI Agents to Agentic Applications, Development Frameworks & Data-Centric Productivity Tools, I share insights and ideas on how these technologies are shaping the future.