In Short
Using RAFT, when presented with a question and a batch of retrieved documents, the framework instructs the model to disregard those documents that do not contribute to answering the question. These disregarded documents are referred to as distractor documents.
In recent studies there have been efforts to reduce the noise introduced at inference. This is where information is retrieved which is not relevant to the current context.
Added to this, optimising the size of the context injected is also important in terms of token usage costs, timeout and payload overheads.
RAFT also incorporates a chain-of thought approach which leads me to the next point. RAG implementations are starting to go beyond merely context injection, and is starting to incorporate prompting approaches.
Extensive focus is given to the format of training data, each data point contains a question (Q), a set of documents (Dk), and a corresponding Chain-of-thought style answer.
Domain Specific Implementations
When it comes to adapting LLMs to specific domains, the two candidates are:
Leveraging in-context learning through RAG, or
Supervised fine-tuning.
RAG allows the model to refer to documents while answering questions, but it misses out on learning from the fixed domain setting and prior access to test documents.
On the other hand, supervised fine-tuning allows learning broader patterns from documents, better aligning with end tasks and user preferences.
However, current fine-tuning approaches either don’t utilise documents during testing or overlook imperfections in retrieval during training.
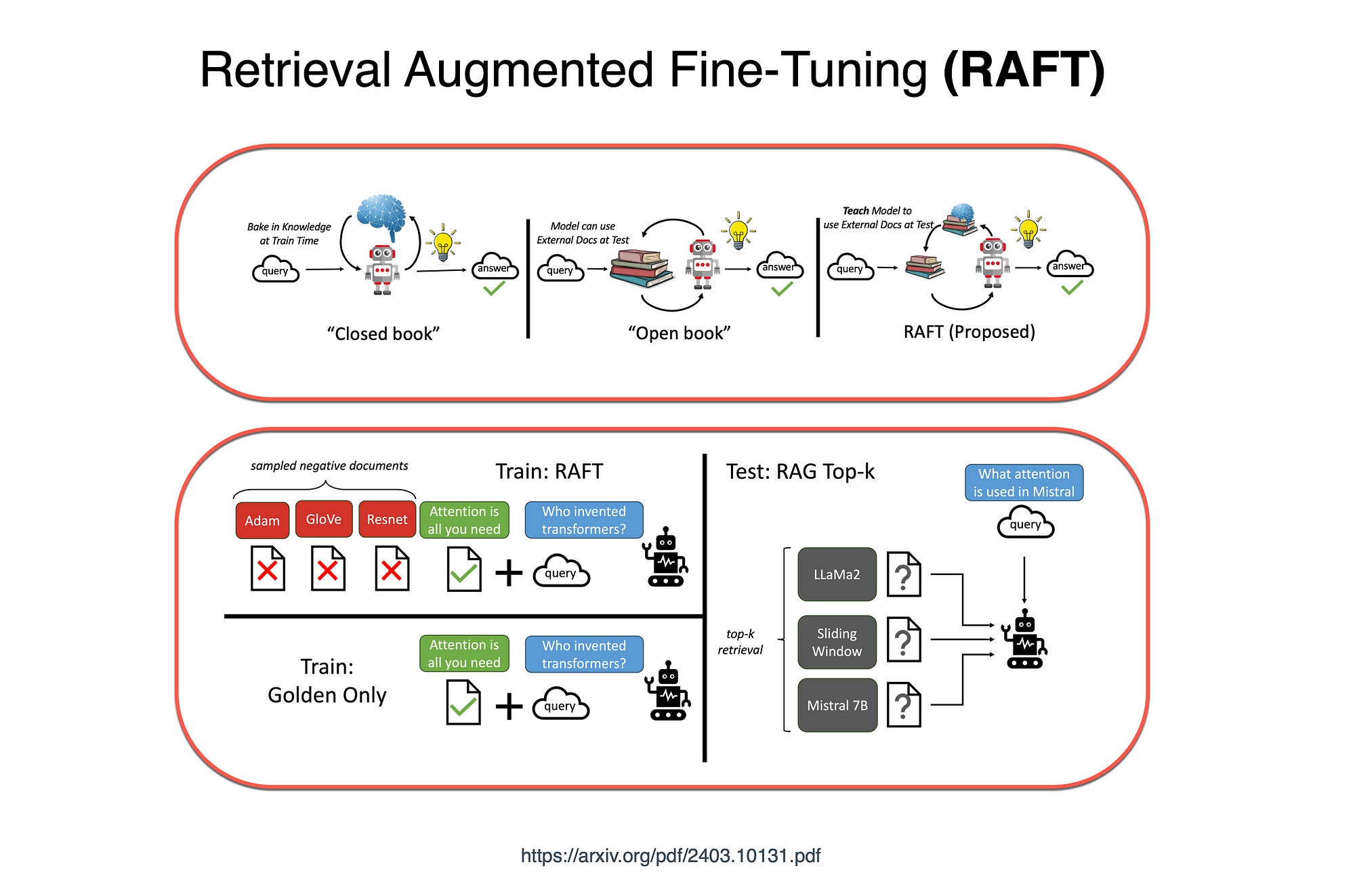
Hence RAFT endeavours to combine fine-tuning with RAG. With RAFT, with supervision, the best results can be collected for fine-tuning.
Data Centric
RAFT focusses on preparing data…
In RAFT, the preparation of the training data is performed in such a way that each data point contains a question (Q), a set of documents (Dk), and a corresponding Chain-of-though style answer.
This paper examines the following question — How to adapt pre-trained LLMs for Retrieval Augmented Generation (RAG) in specialised domains?

Considering the image above, fine-tuning approaches can be likened to studying for a test by either memorising input documents or practicing questions without referring back to the material.
On the other hand, in-context retrieval methods miss out on learning from the fixed domain, similar to taking an open-book exam without any prior study.
RAFT combines fine-tuning with question-answer pairs while referring to documents in a simulated imperfect retrieval scenario. This method effectively prepares the model for open-book exams.
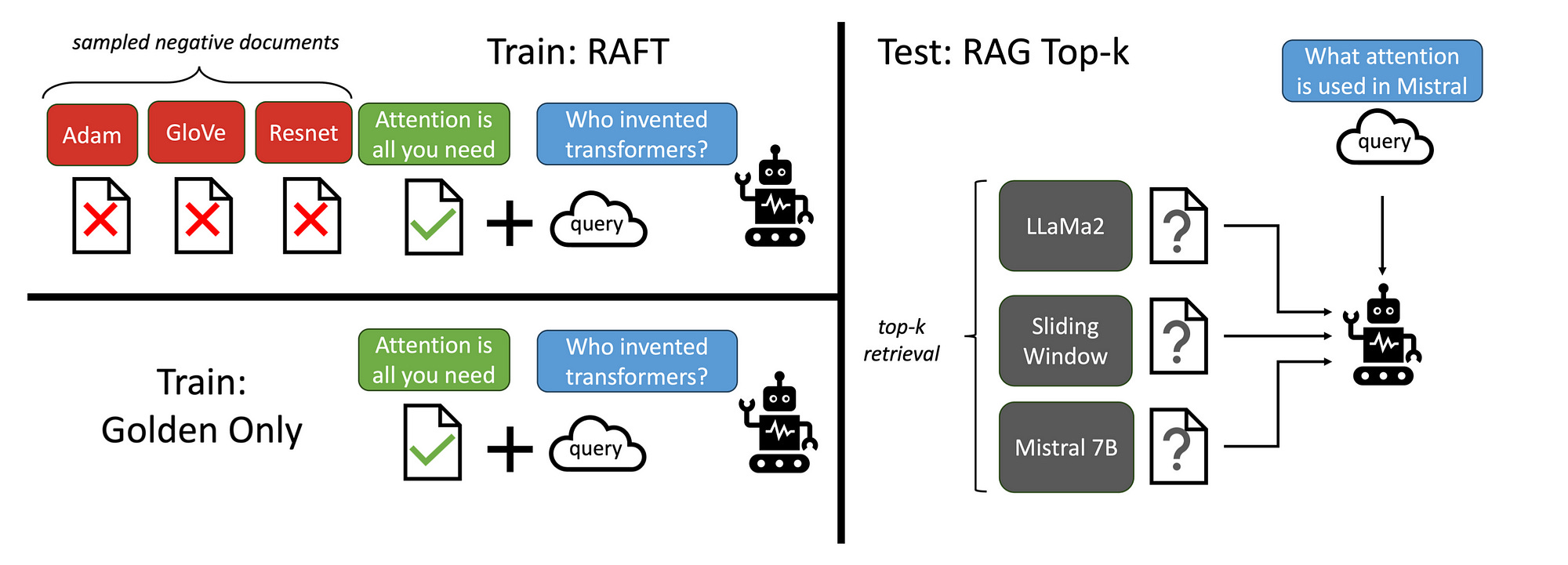
Again considering the image above, the RAFT method is an approach to adapting LLMs for reading solutions from a collection of positive and negative documents.
This stands in contrast to the standard RAG setup, where models are trained using retriever outputs, encompassing both memorisation and reading.
In Conclusion
The study finds that smaller, fine-tuned models are capable of performing comparably well in domain-specific question-answering tasks, in contrast to their generic LLM counterparts.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.