

Scaleable Prompt Pipelines For LLMs
In a previous post I wrote about the evolution of prompt engineering. Creating highly scaleable & enterprise grade LLM based applications demand a pipeline approach to prompts.


LLM Prompts yield better results when they have a contextual referencedefined within the prompt. As seen below, the prompt consists of four labels: instruction, context, question and answer.
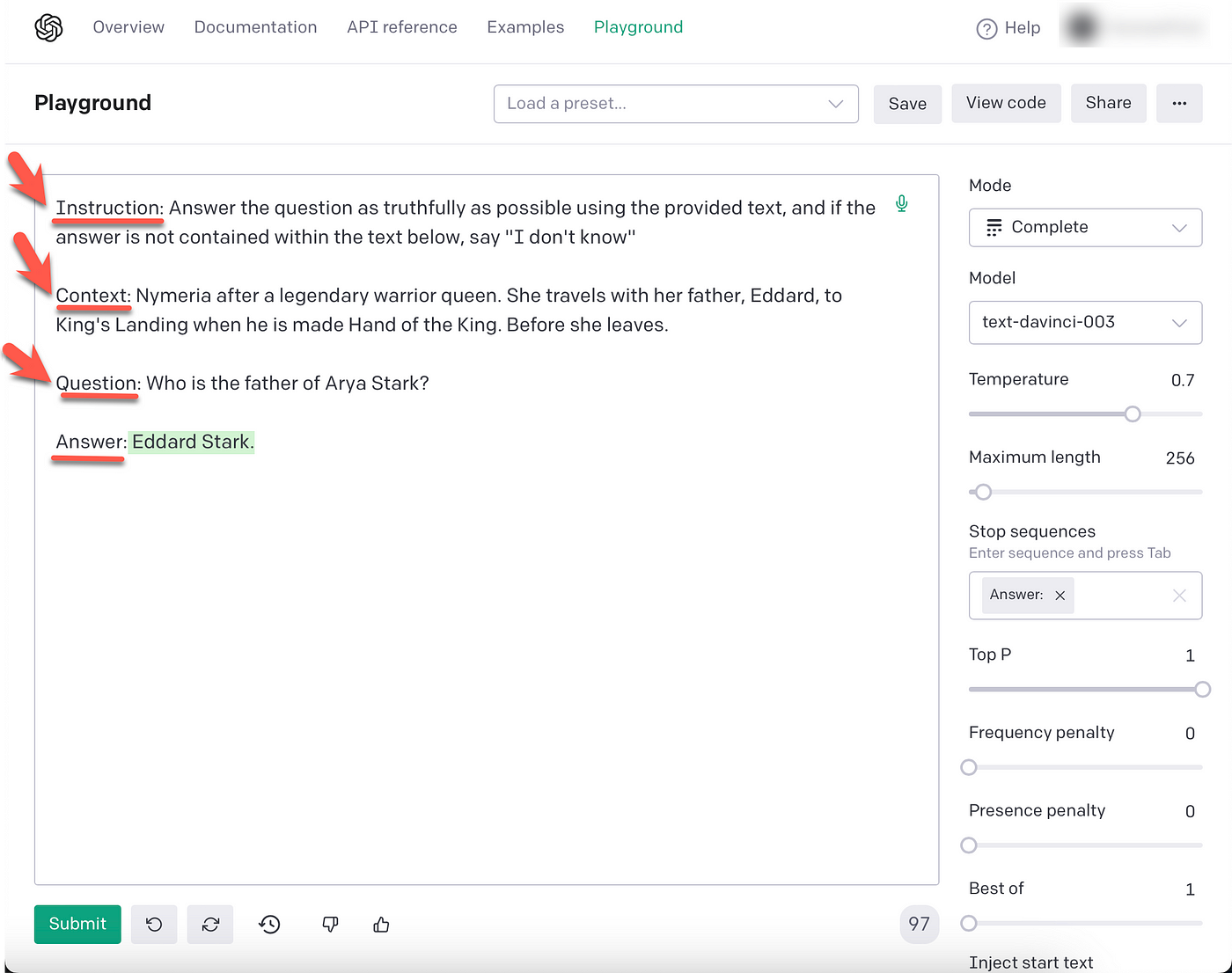
The question is the input from the user. The Context acts as a reference and contextual guide to the LLM on how to answer the question.
Composing a prompt manually and running it against a LLM is a straightforward process. However, compiling contextual prompts at scale will require automation of the prompt creation process.
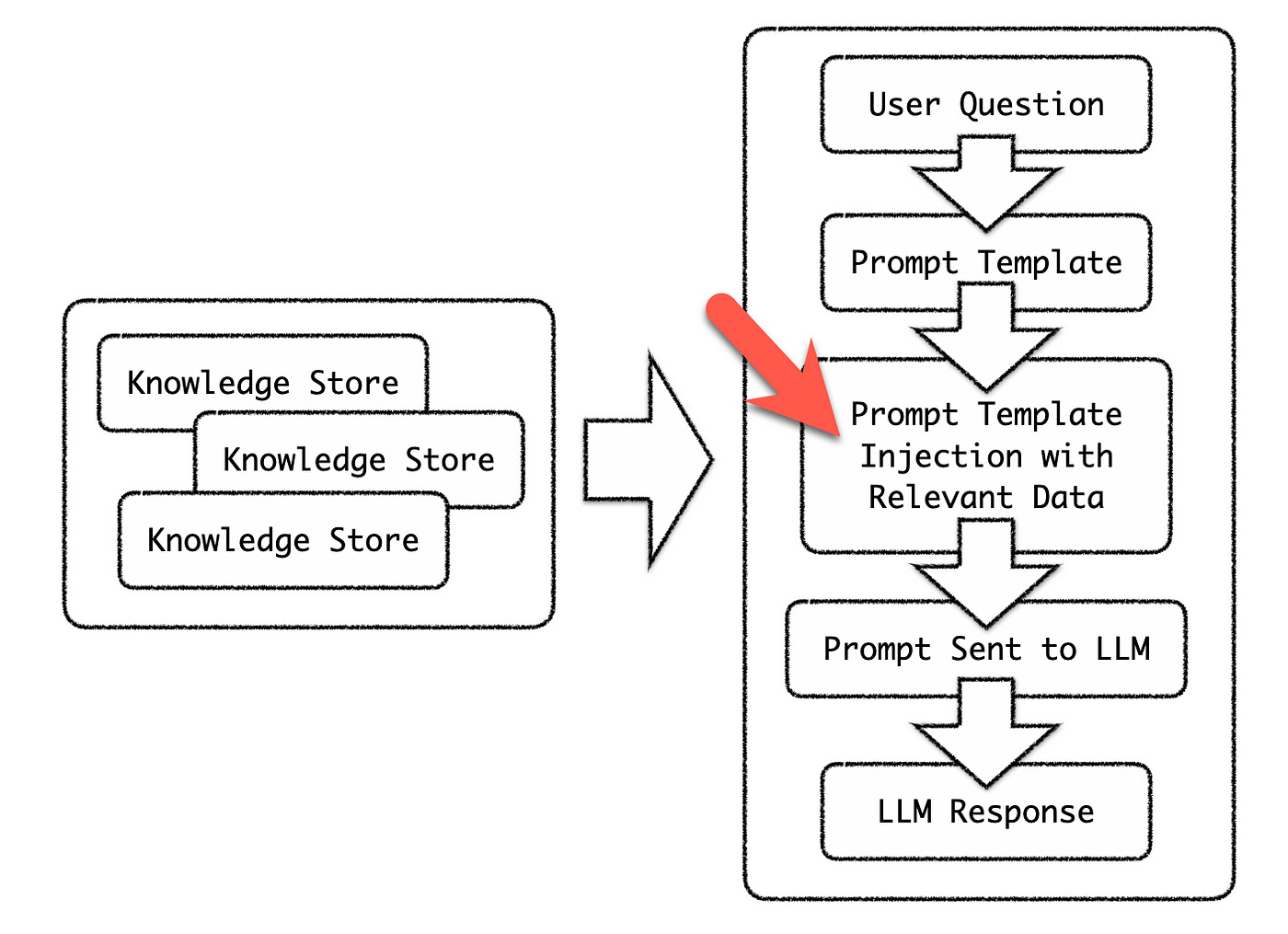
Considering the diagram below, the red arrow indicates the point where automation is required. Based on the question of the user, a semantic search needs to be performed, and the relevant piece of text needs to be retrieved from the Knowledge Store. Again, this text snippet will act as the contextual reference for the prompt.
The example below showing how a prompt pipeline can be created for contextual prompts is from Haystack.
The documents are stored in a Document Store, from where the question answering system retrieve the answers to user questions. For this example, Elasticsearch is used. Elasticsearch runs separately from Haystack.
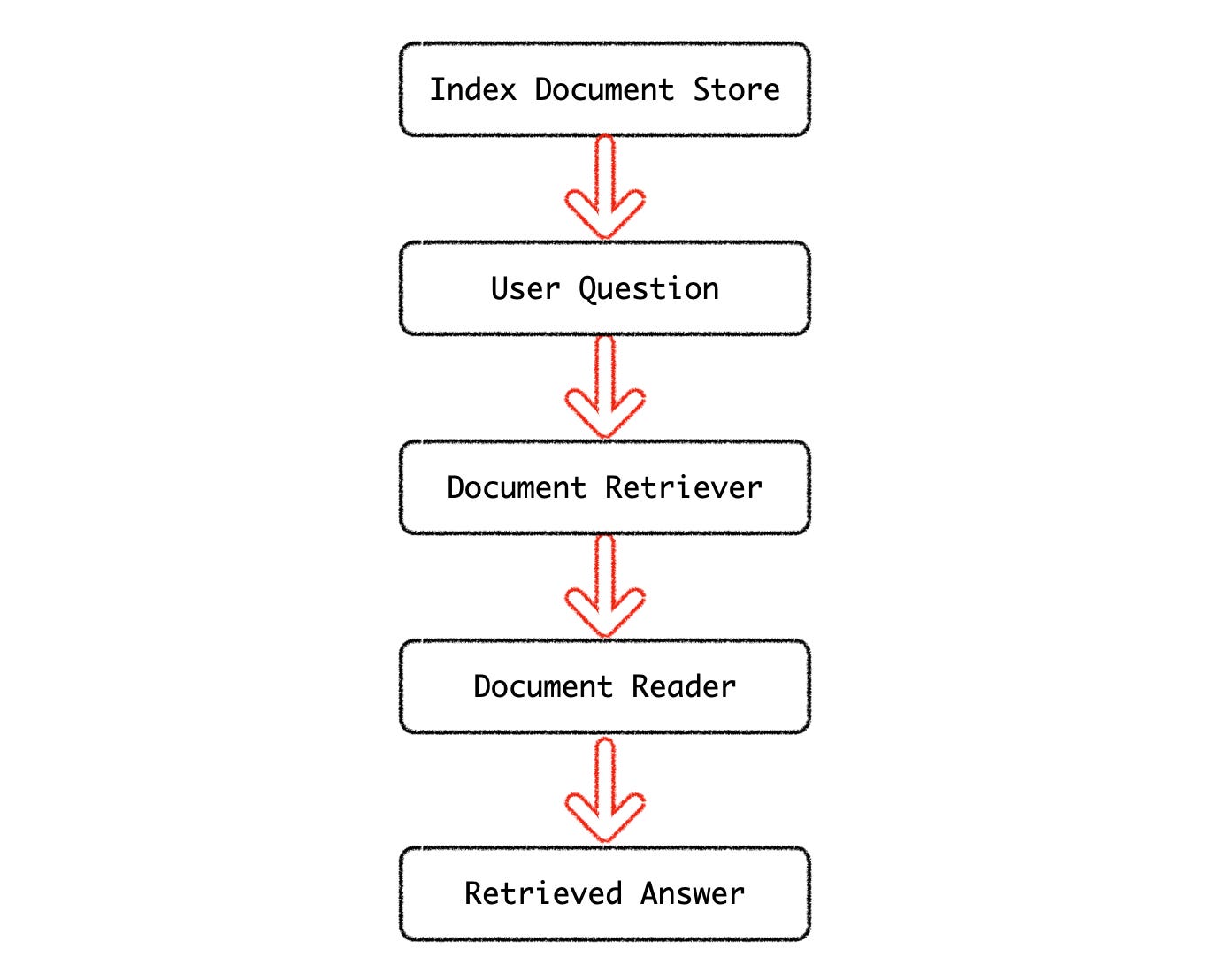
Next in the pipeline is the Document Retriever. The retriever sifts through all the Documents and returns only those that are relevant to the question.
The Retriever performs document retrieval by sweeping through a DocumentStore and returning a set of candidate Documents that are relevant to the query. (BM25Retriever) ~ Haystack
The Document Reader scans the text received from the Retriever and extracts the top answers. For this demo the RoBERTa question answering model is used.
The Retrieved answer can then be submitted to a LLM as the context of the engineered prompt.
Below you can see the instruction section of the prompt, which is static for this use-case. The context was retrieved via the process described above. The user question is inserted into the prompt and the stop sequence defined for the prompt is “Answer:”.
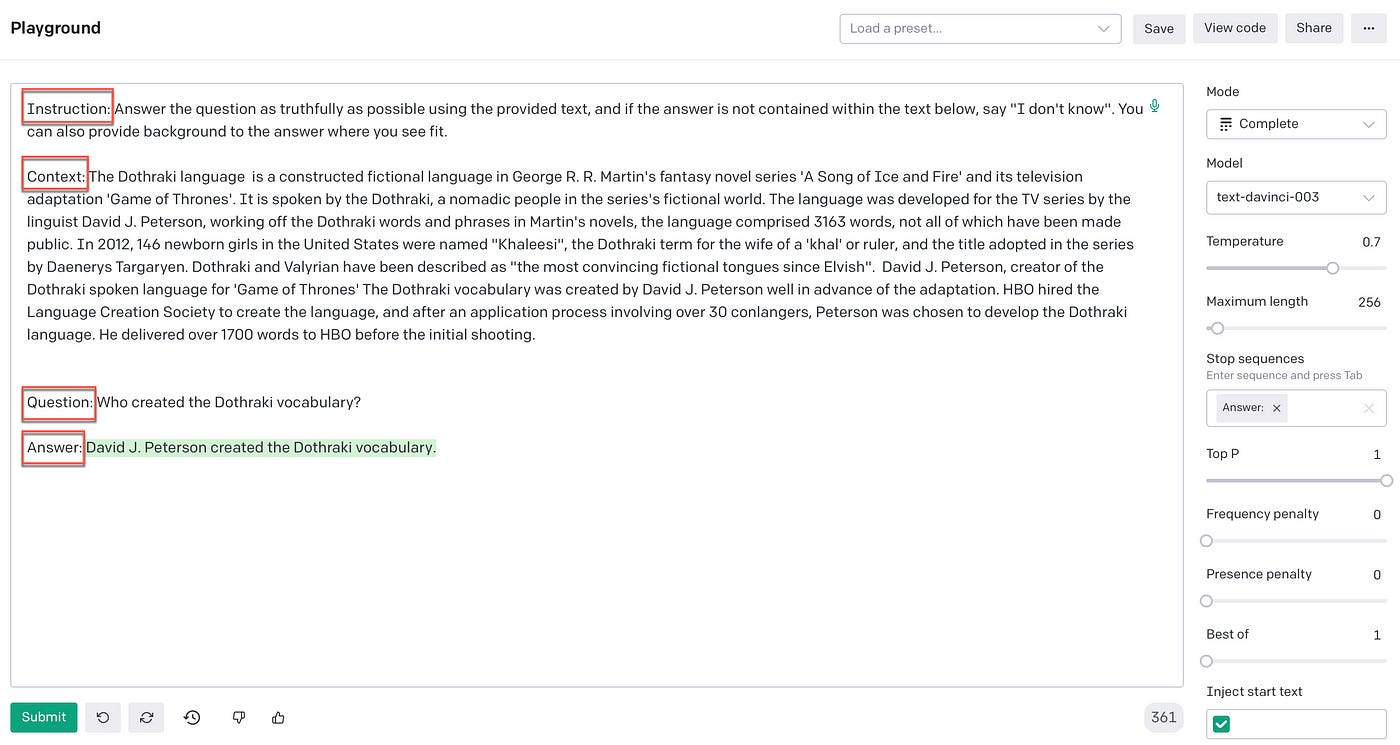
The LLM, in this case text-davinci-003 formulates an answer based on the context provided within the prompt.
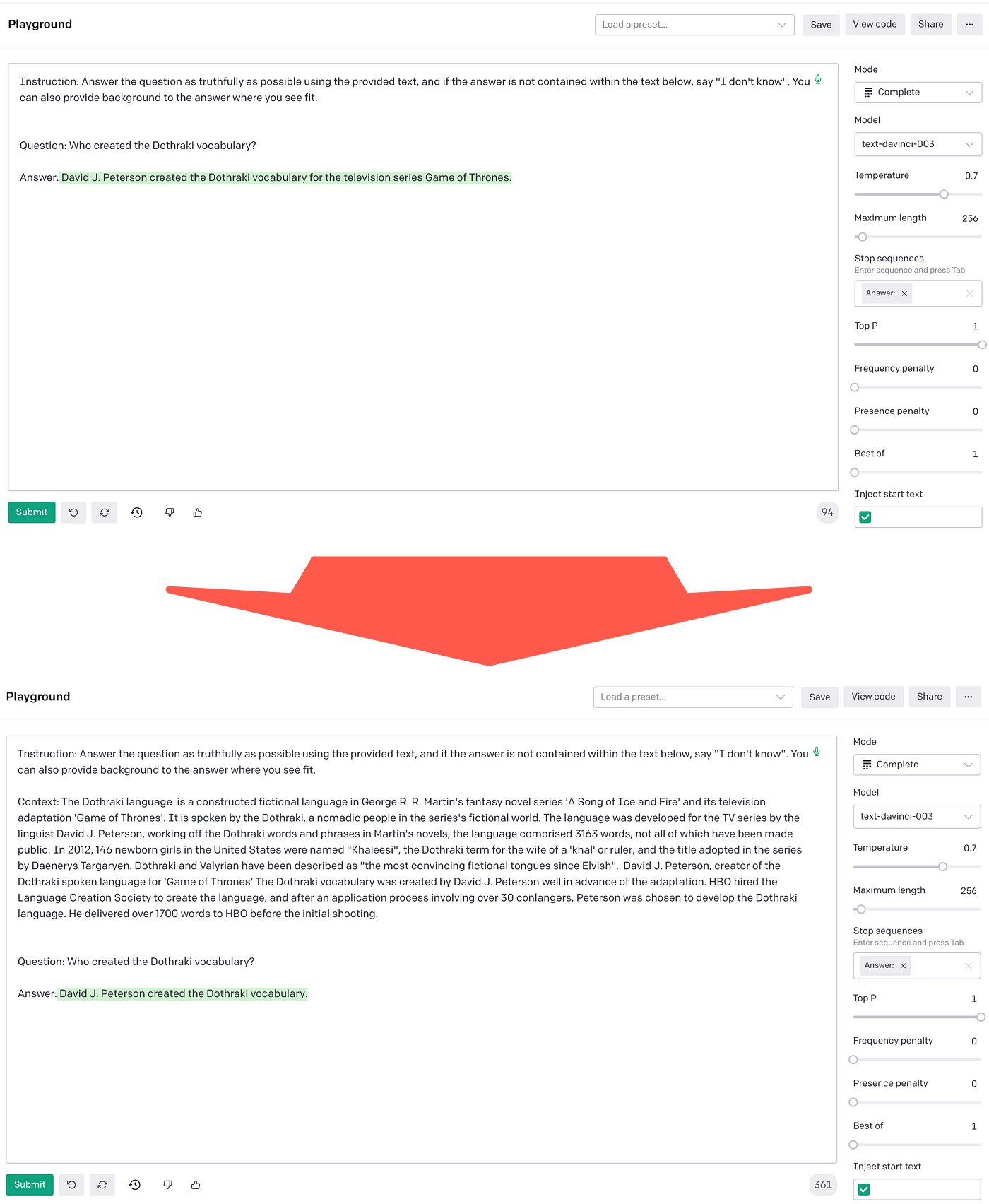
The Haystack example made use of Game Of Thrones as the domain which is a general broad domain. And the likelihood of OpenAI’s LLMs answering this question correctly is fairly good. As can be seen in the image below, the top prompt has no context, while the bottom prompt have the context injected.
It is interesting to see how the context influences the LLM output.
However, for a more narrow private domain, for instance specific company knowledge and QnA, context will be essential.
In Conclusion
The last mile of AI implementations has been in the spotlight of late. The challenge is that companies are not realising business value and cost savings via AI as anticipated.
The solution to this problem lies at a few fronts:
In the case of Conversational UI/AI, business intents should not be used as a reference, but rather customer intents. Hence the conversation customers want to have. To determine customer intent, a bottom-up, data centric approach to Conversational AI design is required.
LLM models require accurate data. This data is essential for few-shot or one-shot training via prompt injection.
The next level is fine-tuning LLMs for domain and company specific implementations. Again astute data curation, and conversion of unstructured data into structured LLM training data is crucial.

⭐️ Please follow me on LinkedIn for updates on Conversational AI ⭐️

I’m currently the Chief Evangelist @ HumanFirst. I explore and write about all things at the intersection of AI and language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces and more.
