Self-Refine Is An Iterative Refinement Loop For LLMs
The Self-Refinement methodology mimic humans in a three step process where initial outputs from an LLM is refined via a sequence of iterative feedback.

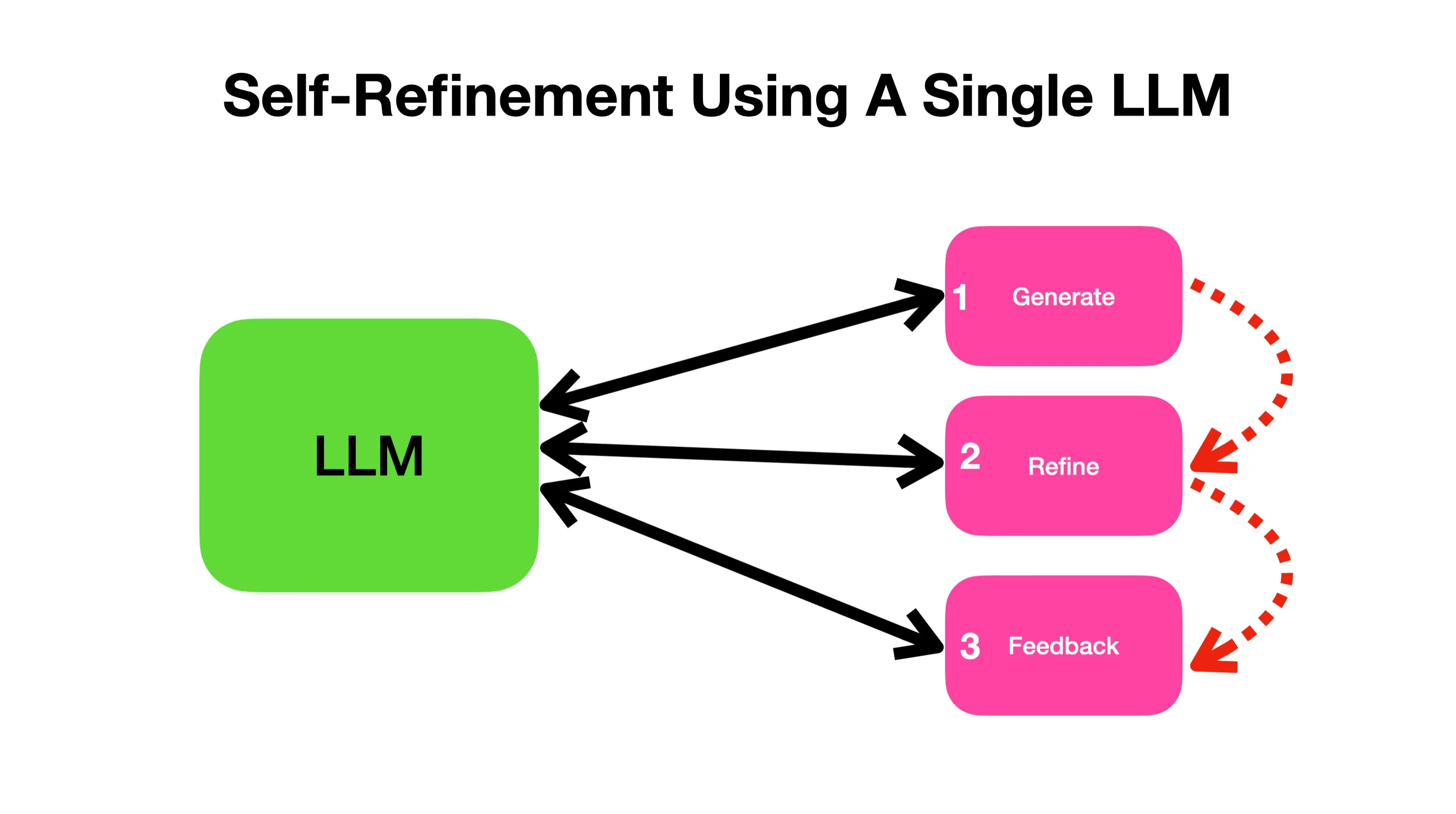
The biggest advantage of this approach is that it does not require any supervised training data, additional training or reinforcement learning.
A single LLM is used for generation, refinement and feedback.
Self-Refinement was tested across seven diverse tasks (in the footer of this article are three notebooks you can tryout) for dialog response generation, math reasoning, etc.
The basic principle of the Self-Refine approach is, that when we as humans revisit something we generated, we often find ways of improving it. Consider writing an email; if we save the first version in the draft folder, and re-read the email a few hours later, we as humans intuitively find ways on how to improve the writing.
Or when a programmer churns out a piece of code, and subsequently reflect on their code, the programmer will invariably find ways to optimise and improve it.
Can we just generate multiple outputs instead of refining? — No
The Self-Refine study demonstrates how an LLM can provide iterative self-refinement without additional training, yielding higher-quality outputs on a wide range of tasks.

In the image above you see the initial output in the left, the same LLM is used to generate the feedback and yet again the same LLM for refinement.
Does SELF-REFINE work as well with weaker models?
- No.
It is an advantage of self-improvement that only a single LLM is leveraged, however this also introduces an important consideration. And that is the fact that this approach is heavily dependant on the LLM it uses as a base. The study found that improvements are in keeping with the size of the LLM size. GPT-4 & Self-Refine works better than GPT-3.5 & Self-Refine.
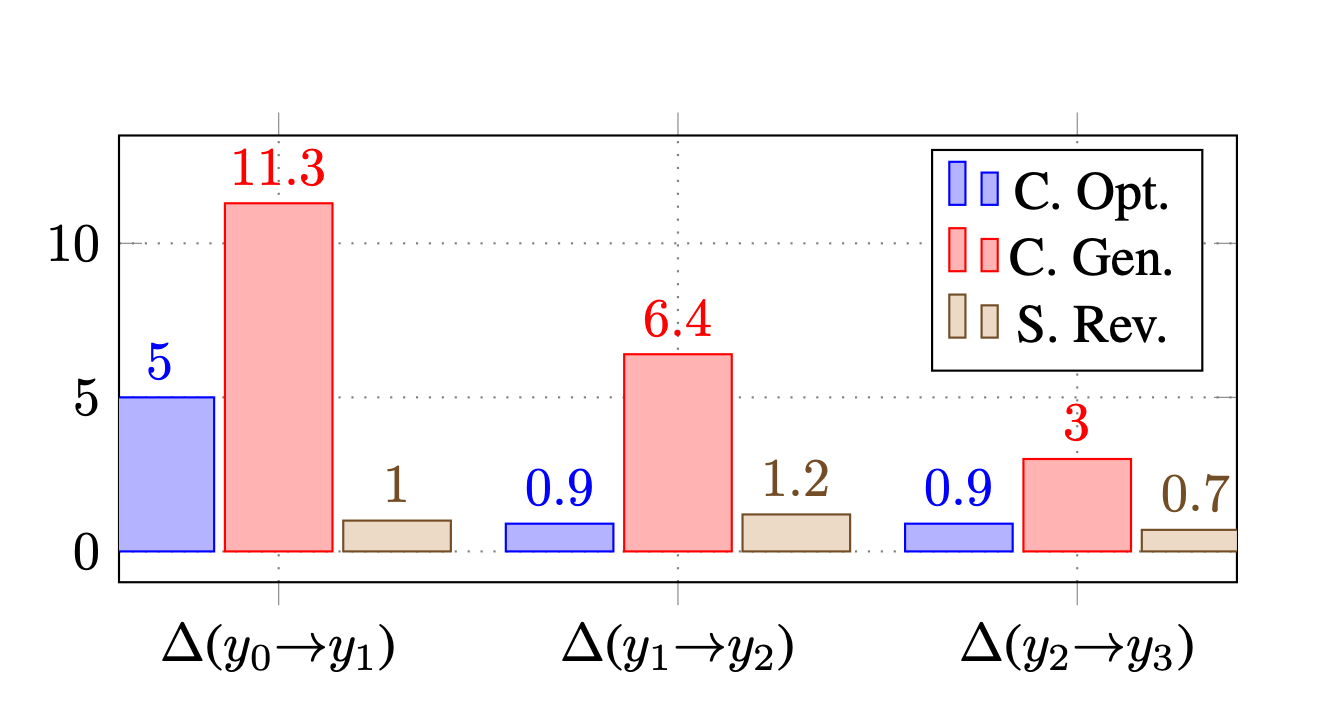
Considering the image above, on average, the quality of the output improves as the number of iterations increase.
The quality of the output improves as the number of iterations increase.
For instance, for a code optimisation task, the initial output (y0) has a score of 22.0, which improves to 28.8 after three iterations (y3).
Similarly, in the Sentiment Reversal task, the initial output has a score of 33.9, which increases to 36.8 after three iterations.
These findings do bring to mind that a balance will have to be found in terms of quality/improvement and iterations. Multiple iterations introduce considerations like latency, cost and rate limits.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.