

Self-Reflective Retrieval-Augmented Generation (SELF-RAG)
The ideal is for Generative AI implementations to deliver factual, verified & quality responses. SELF-RAG was created in an attempt to solve for this.


Introduction
It is interesting to note, that RAG is following very much the same trajectory as prompt engineering. RAG started off as a simple yet effective concept which consists of prompt injection with contextual reference data.
The primary objective of RAG is to leverage ICL (In-Context Learning) capabilities of LLMs.
Complexity and efficiency are being introduced to RAG. Retrieval does not take place by default, and a process of triage takes place to determine if the LLM can fulfil the user request.
Efficiency and accuracy trade-off. There is always a balance to be found between efficiency and accuracy. Accuracy at the cost of efficiency negatively impacts user experience and practical use-cases. Efficiency at the cost of accuracy leads to a misleading and inaccurate solution.
Triaging user input to determine direct LLM inference or prompt injection via RAG requires a reference. In the case of SELF-RAG it is against a fine-tuned LLM making use of self-reflection.
The principle of RAG triage can be applied in various forms. The most important aspect is the reference against which the decision is made to directly infer the question from an LLM, or make use of RAG. And in the case where RAG is used; being able to assess the quality and correctness of the repsonse.
Generative AI based applications can also include a wider consideration for triage…where other options apart from direct inference or RAG are available. For instance, human-in-the-loop, web search, multi-LLM orchestration, etc.
More on SELF-RAG
The SELF-RAG framework trains a single arbitrary language model to adaptively retrieve passages on-demand.
To generate and reflect on retrieved passages and on own generations using special tokens, called reflection tokens.
Reflection Tokens
Reflection tokens are categorised into retrieval and critique tokens to indicate the need for retrieval and its generation quality respectively.
SELF-RAG uses reflection tokens to decide the need for retrieval and to self-evaluate generation quality.
Generating reflection tokens makes the LM controllable during the inference phase, enabling it to tailor its behaviour to diverse task requirements.
The study shows that SELF-RAG significantly outperforms LLMs and also standard RAG approaches.
Steps in SELF-RAG
The LLM generates text informed by retrieved passages.
Criticise the output by learning to generate special tokens.
These reflection tokens signal the need for retrieval or confirm the output’s relevance, support, or completeness.
In contrast, common RAG approaches retrieve passages indiscriminately, without ensuring complete support from cited sources.

Considering the image below…SELF-RAG learns to retrieve, critique and generate text passages to enhance overall generation quality, factuality, and verifiability.

Some Considerations
Additional Inference & Cost
SELF-RAG will introduce more overhead in terms of inference. Considering the image above, the self-reflective approach to RAG introduces more points of inference.
A first step of inference is performed, with three inference steps being performed in parallel. The three results are then compared and a winner is selected for RAG inference.
Out-of-Domain
Also as can be seen in the image above, out-of-domain queries are recognised as such, and the request is not serviced via retrieval, but sent directly to the LLM inference.
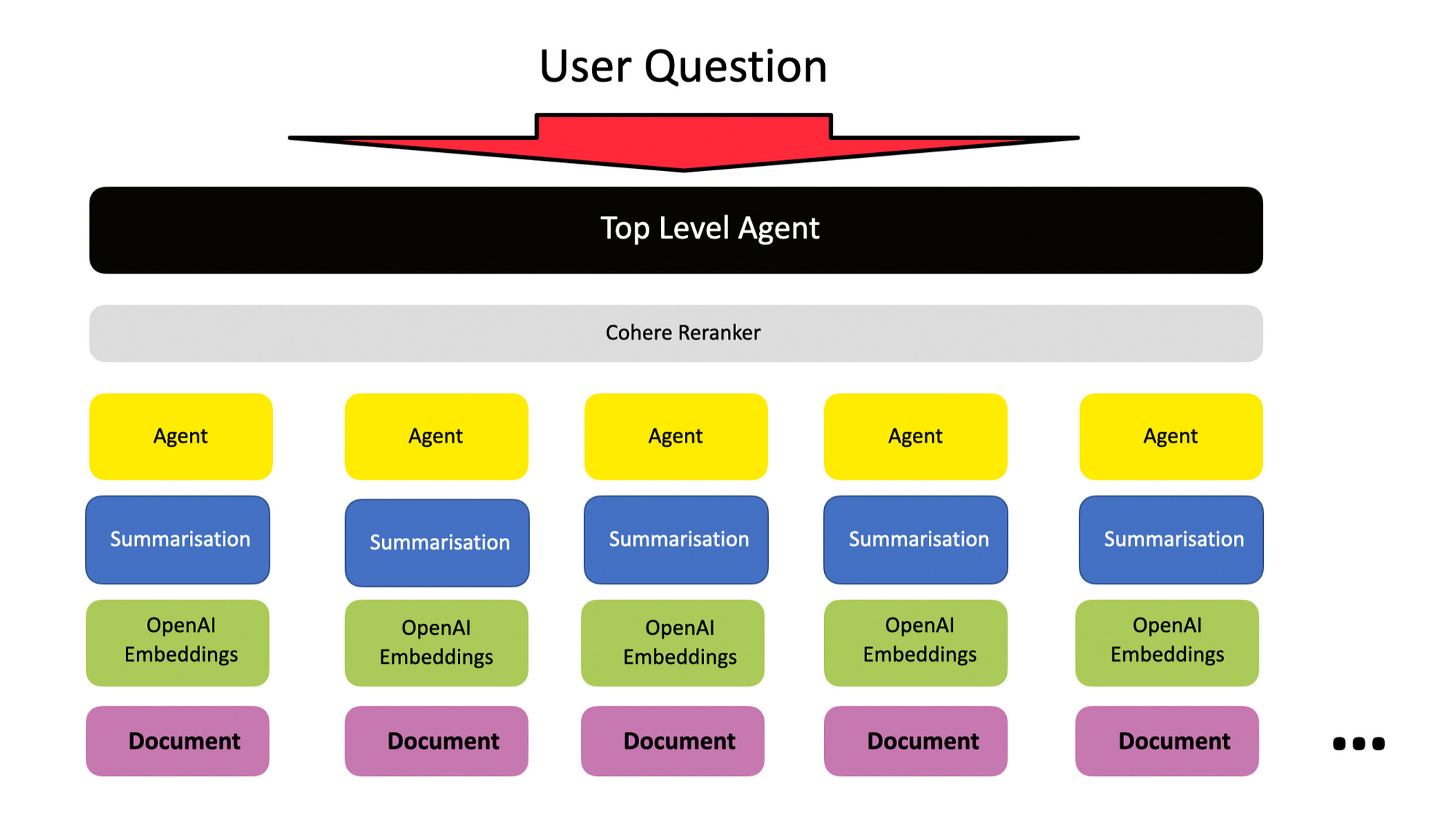
Agentic RAG
Considering the image blow, the question needs to be asked…
With the complexity being introduced to the RAG process, are we not reaching a point where an agent-based RAG approach will work best? An approach LlamaIndex refers to as Agentic RAG.
Intents
There has been studies where intent-based routing has been used to triage user input for the correct treatment with in a generative AI framework. Intents are merely pre-defined use-case classes.

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.
