

Simplifying LLM Optimisation
How a Structured Framework Enhances Understanding and Decision-Making in Language Models and Conversational AI

Introduction
What I love about a two-by-two matrix is that it provides a clear, structured way to visualise and analyse complex relationships between two sets of variables or factors.
Considering Language Models & Conversational AI, by breaking down a problem into four distinct categories, it provides a simplified view to make it easier to grasp concepts. I came across these diagrams in the OpenAI & Ragas documentation.
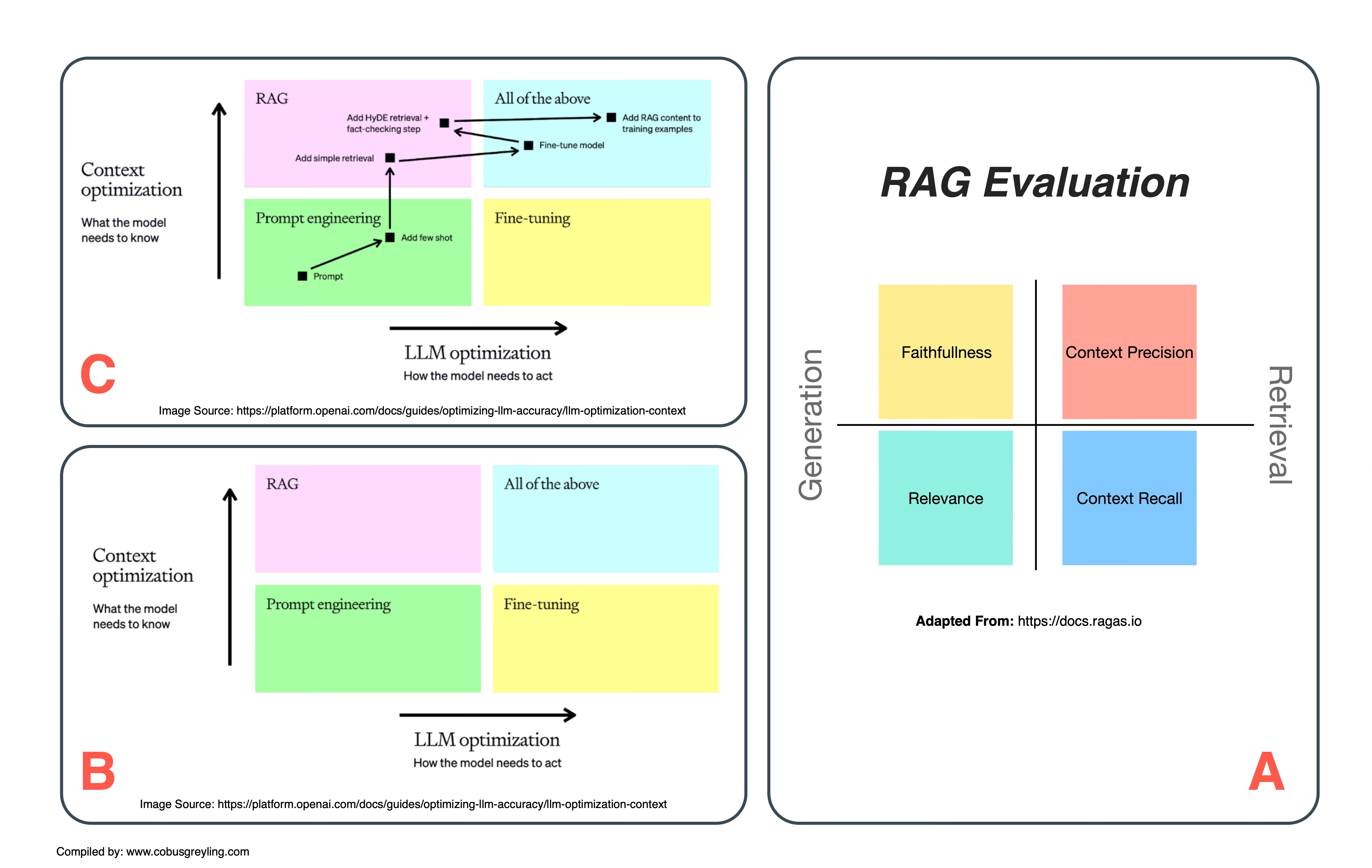
𝗥𝗮𝗴𝗮𝘀 (A)
Ragas is a framework designed for testing & evaluating RAG (Retrieval-Augmented Generation) implementations.
As illustrated in the image below, the RAG evaluation process is split into two main categories: Generation and Retrieval.
The Generation category is further assessed using two metrics: faithfulness and relevance.
On the other hand, Retrieval is evaluated based on Context Precision and Context Recall.
𝗥𝗔𝗚 𝘃𝘀 𝗙𝗶𝗻𝗲-𝗧𝘂𝗻𝗶𝗻𝗴 (B)
Many guides on optimisation present it as a straightforward linear process—starting with prompt engineering, moving on to retrieval-augmented generation, and then fine-tuning.
However, this linear approach often oversimplifies the reality. Consider these as distinct levers that address different aspects of optimization, and achieving the desired outcome requires knowing which lever to pull at the right time.
𝗦𝗲𝗿𝗶𝗲𝘀 𝗼𝗳 𝗢𝗽𝘁𝗶𝗺𝗶𝘀𝗮𝘁𝗶𝗼𝗻 𝗦𝘁𝗲𝗽𝘀 (C)
The typical LLM optimisation process begins with prompt engineering, where initial testing, learning, and evaluation establish a baseline.
After reviewing these baseline results and identifying the reasons for inaccuracies, you can adjust one of the following levers:
𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗢𝗽𝘁𝗶𝗺𝗶𝘀𝗮𝘁𝗶𝗼𝗻: Apply this when the model lacks contextual knowledge (due to gaps in its training data), when its knowledge is outdated, or when it requires understanding proprietary information. This approach enhances response accuracy.
𝗟𝗟𝗠 𝗢𝗽𝘁𝗶𝗺𝗶𝘀𝗮𝘁𝗶𝗼𝗻: Focus on this when the model produces inconsistent results, incorrect formatting, or an inappropriate tone/style, or when its reasoning lacks consistency. This approach improves the consistency of behaviour.
Any other insights?