

Small Language Model (SLM) Efficiency, Performance & Potential
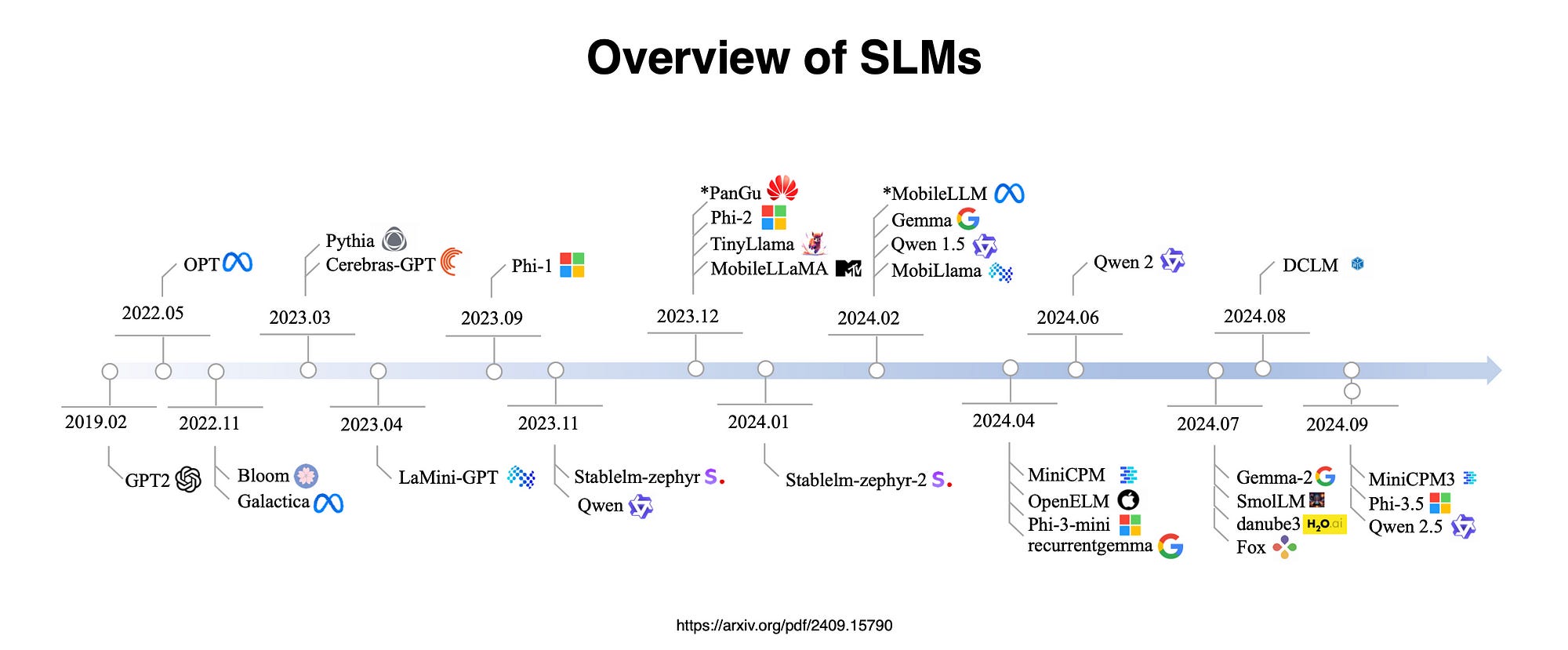
Focusing on models with 100 million to 5 billion parameters, researchers surveyed 59 cutting-edge open-source models, examining innovations in architecture, training datasets & algorithms.

Introduction
They also evaluated model abilities in areas like common-sense reasoning, in-context learning, math & coding.
To assess model performance on devices, researchers benchmarked latency and memory usage during inference.
The term “small” is inherently subjective and relative & its meaning may evolve over time as device memory continues to expand, allowing for larger “small language models” in the future.
The study established 5 billion parameters as the upper limit for small language models (SLMs). As of September 2024, 7 billion parameter large language models (LLMs) are predominantly deployed in the cloud.
On Device Small Language Models
Small Language Models (SLMs) are designed for resource-efficient deployment on devices like desktops, smartphones, and wearables.
The goal is to make advanced machine intelligence accessible and affordable for everyone, much like the universal nature of human cognition.
Small Language Models (SLMs) are already widely integrated into commercial devices. For example, the latest Google and Samsung smartphones feature built-in Large Language Model (LLM) services, like Gemini Nano, which allow third-party apps to access LLM capabilities through prompts and modular integrations.
Similarly, the newest iOS on iPhones and iPads includes an on-device foundation model that is tightly integrated with the operating system, enhancing both performance and privacy. This widespread adoption showcases the potential of SLMs in everyday technology.
By enabling AI capabilities on personal devices, SLMs aim to democratise access to powerful technologies, allowing people to use intelligent systems anytime and anywhere without relying on cloud-based resources.
Key Findings
This research on 𝗦𝗺𝗮𝗹𝗹 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹𝘀 (𝗦𝗟𝗠𝘀) found a number of key insights regarding SLMs:
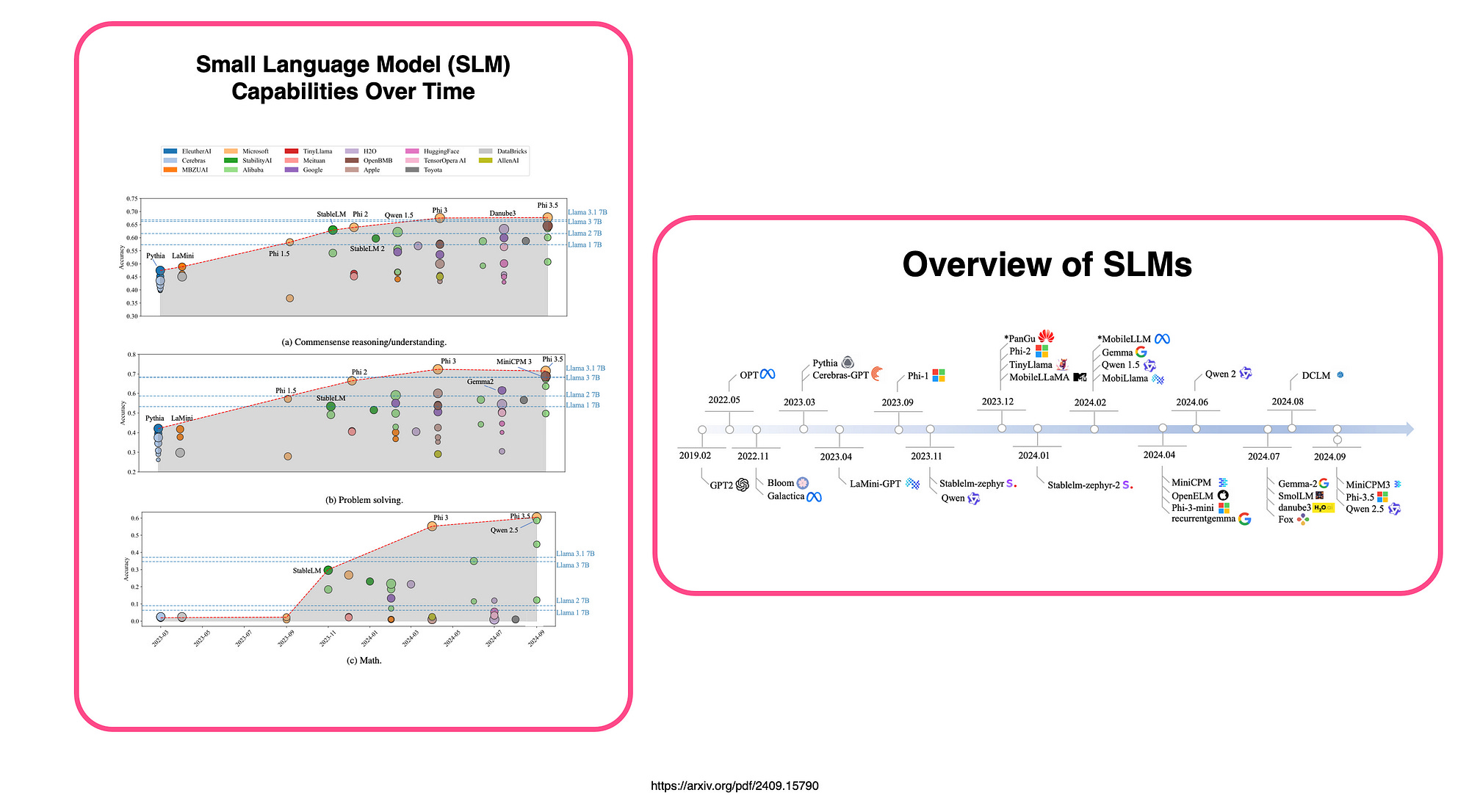
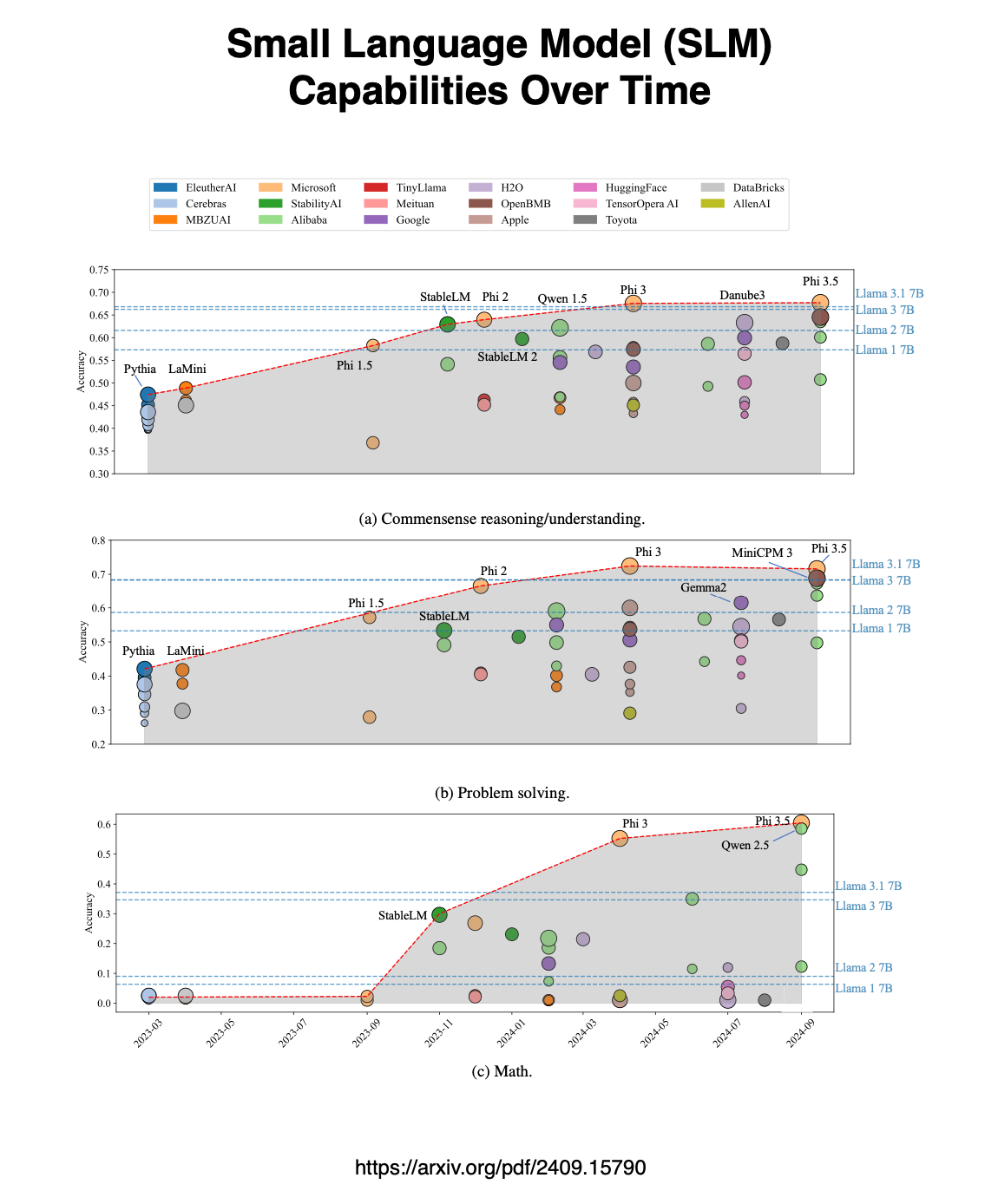
From 2022 to 2024, SLMs showed notable performance gains across language tasks, surpassing the LLaMA-7B series, indicating strong potential for solving tasks on devices.
The Phi family, especially 𝗣𝗵𝗶-𝟯-𝗺𝗶𝗻𝗶, achieved leading accuracy by September 2024, partly due to data engineering and tuning techniques.
While larger models generally perform better, smaller models like Qwen-21.5B excel in specific tasks.
SLMs trained on open-source data are improving but still lag behind closed-source models in complex reasoning tasks, especially those involving logic and math.
Most SLMs possess some level of in-context learning, but its effectiveness varies by task. While nearly all models benefit greatly from in-context learning in tasks.
Model architecture significantly affects latency alongside model size.
The architecture of a model, including factors like layers and vocabulary size, can impact its speed and memory use. For example, Qwen1.5–0.5B has more parameters than Qwen2–0.5B but runs faster on certain hardware, showing that performance depends on the device.
The definition of “small” for language models is subjective and can change over time as device memory increases, allowing larger models to be considered “small” in the future.
Currently, a size limit of 5 billion parameters is set for small language models, as by September 2024, 7 billion parameter models are still primarily deployed in the cloud.
This distinction reflects the evolving capabilities of hardware and the practical deployment limits at the time.
Data quality is essential for the performance of Small Language Models (SLMs) and has gained increasing attention in recent research.
Generally, the quality of data is more important than the quantity of data or the specific model architecture.
In Conclusion
If you’re a regular reader of my articles, you’ve likely noticed my growing fascination with the creative methods used to craft training data, particularly for building and pre-training Small Language Models (SLMs).
What stands out to me in this research is the emphasis on data quality over quantity or model architecture. This brings us to the concept of data design, where training data is thoughtfully structured with an underlying topology.
Some intriguing approaches in this area include Prompt Erasure, Partial Answer Masking (PAM), and Tiny Stories.
Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. From Language Models, AI Agents to Agentic Applications, Development Frameworks & Data-Centric Productivity Tools, I share insights and ideas on how these technologies are shaping the future.