Small Language Models for Agentic Systems
A recent report compiled a comprehensive survey on leveraging small language models (SLMs) for agentic workflows…

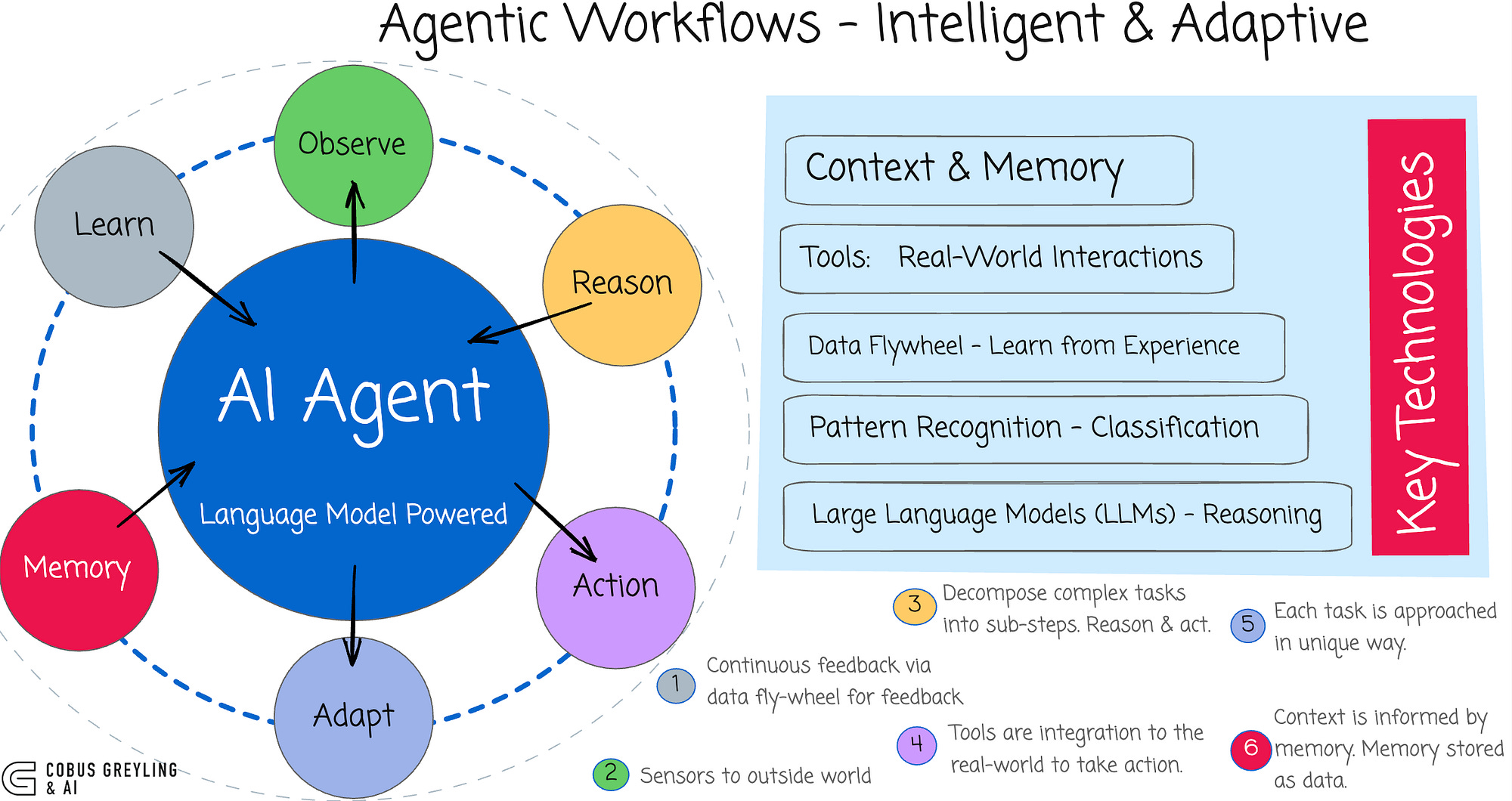
…highlighting SLMs efficiency in tool use, structured outputs and deployment strategies…while positioning them as defaults with LLMs acting as fallbacks.
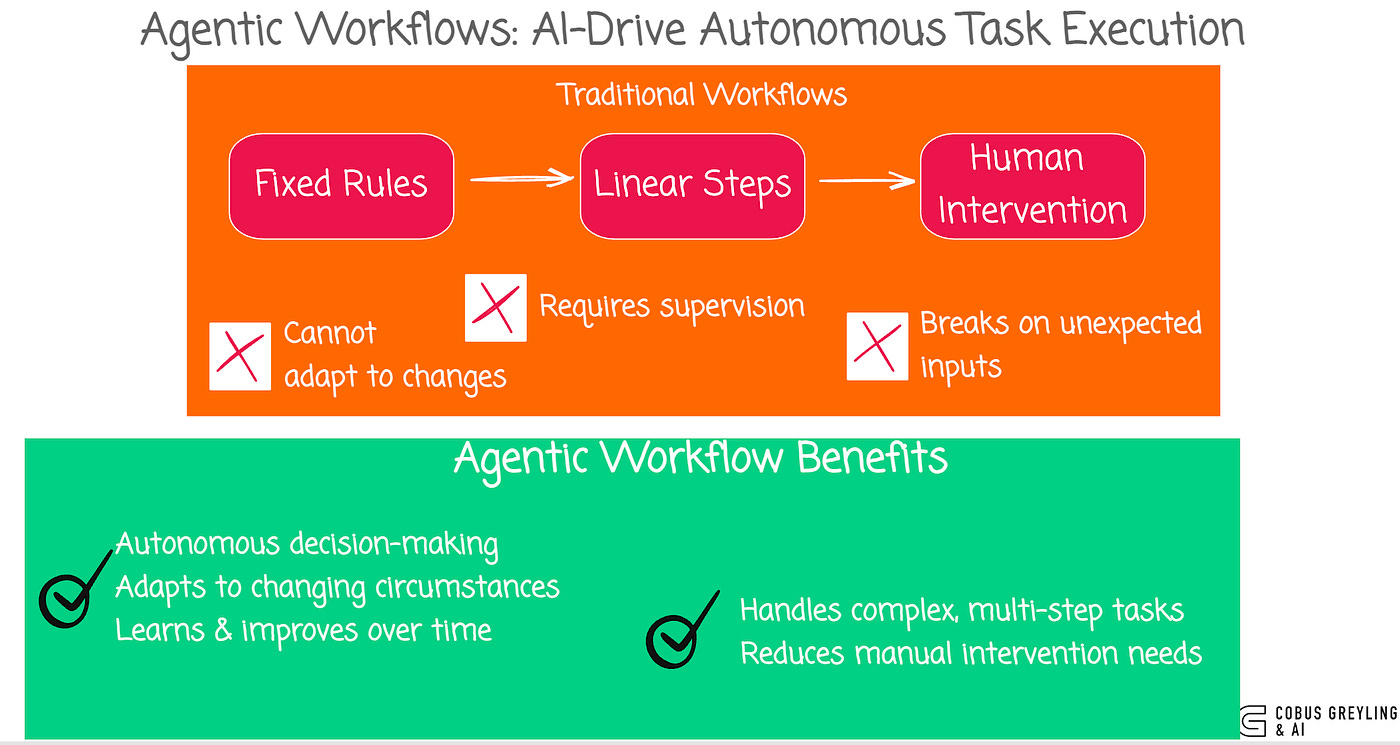
The Front-door Router / Classifier at the centre of most agentic workflows receives incoming requests and routes them based on intent, cost, latency, uncertainty and task type, acting as the main traffic controller.
Agentic workflows favour small language models (SLMs) for routine tasks via a Capability Registry (defined in the study) by tagging SLMs by strengths:
Classification (intent detection)
Extraction,
tool use,
coding, etc…
While escalating complex cases to large language models (LLMs).
The future of agentic systems isn’t bigger models. It’s smarter orchestration.
Imagine a receiving agent gets a user request. The very first model that touches it is a 3B–8B parameter SLM, this little model does almost everything:
- Decides which tools to call
- Extracts entities
- Produces strict JSON or YAML that conforms to a predefined schema
- Orchestrates multi-step plans
LLMs are used for fallback…this is where the Large Language Model finally wakes up.
Escalation triggers are explicit.
The LLM is handed a tightly constrained prompt with the full conversation history, the SLM’s failed attempts, and clear instructions.
Once the LLM produces a corrected output, it still goes through the exact same validators. If it passes, all good. If not, loop again or hit human-in-the-loop.
For anything genuinely dangerous — payments, PII transformation, deleting production data — the system does not proceed automatically.
There are two modes…
Two-stage verification
SLM proposes → second SLM or LLM adjudicates
On-call human queue
uncertainty or policy-risk score too high → alert a human, who approves, denies, or edits
Every human intervention becomes a golden counterfactual trace that gets logged.
The model literally learns from the times a human had to save it.
Everything is logged obsessively, prompt, output, latency, cost, validation errors, escalation rate, uncertainty scores.
That telemetry becomes the training data for the next round of adapters.
Over weeks the SLMs improve at the exact tasks your product actually performs — because it’s only ever trained on your product.
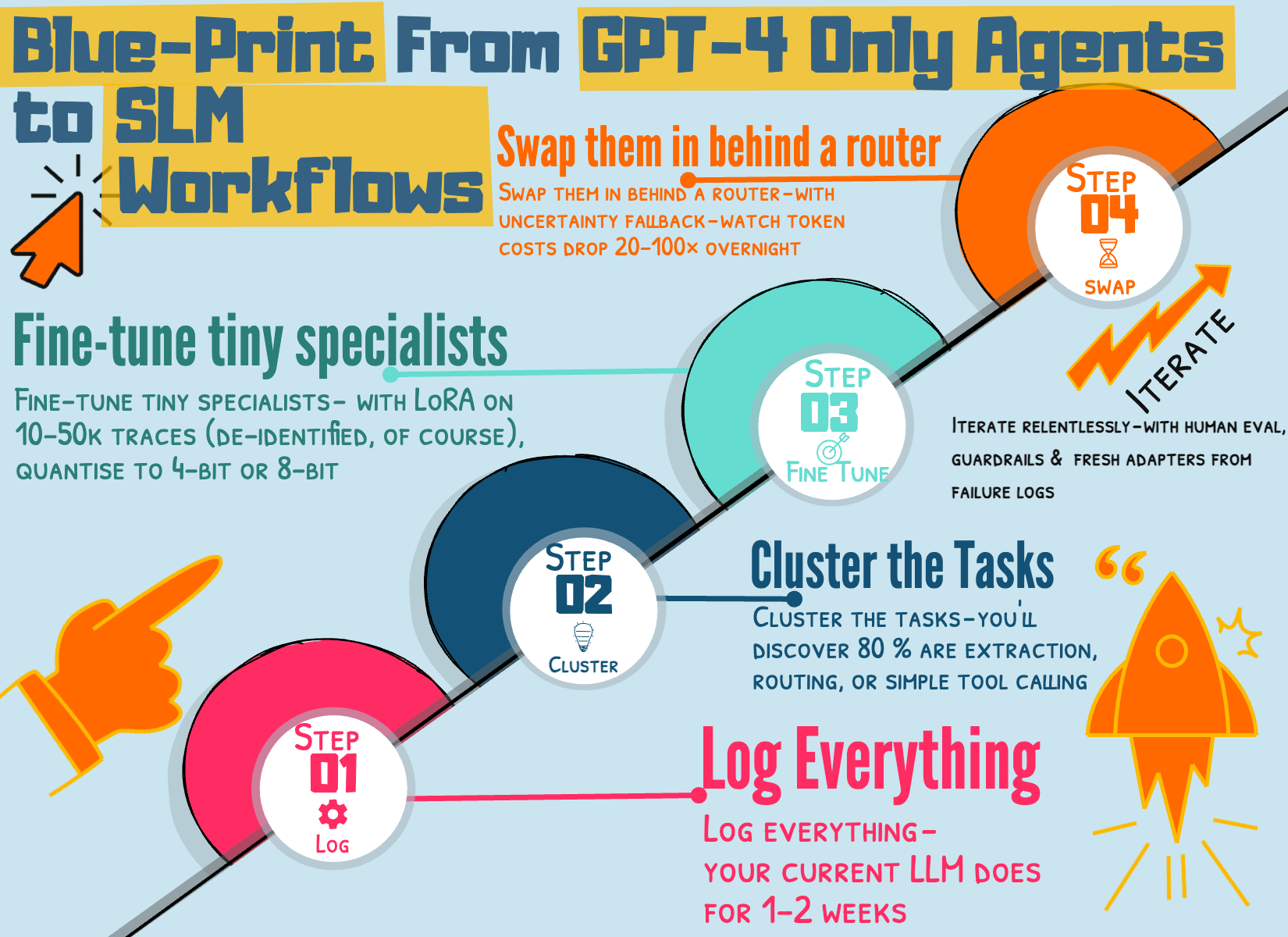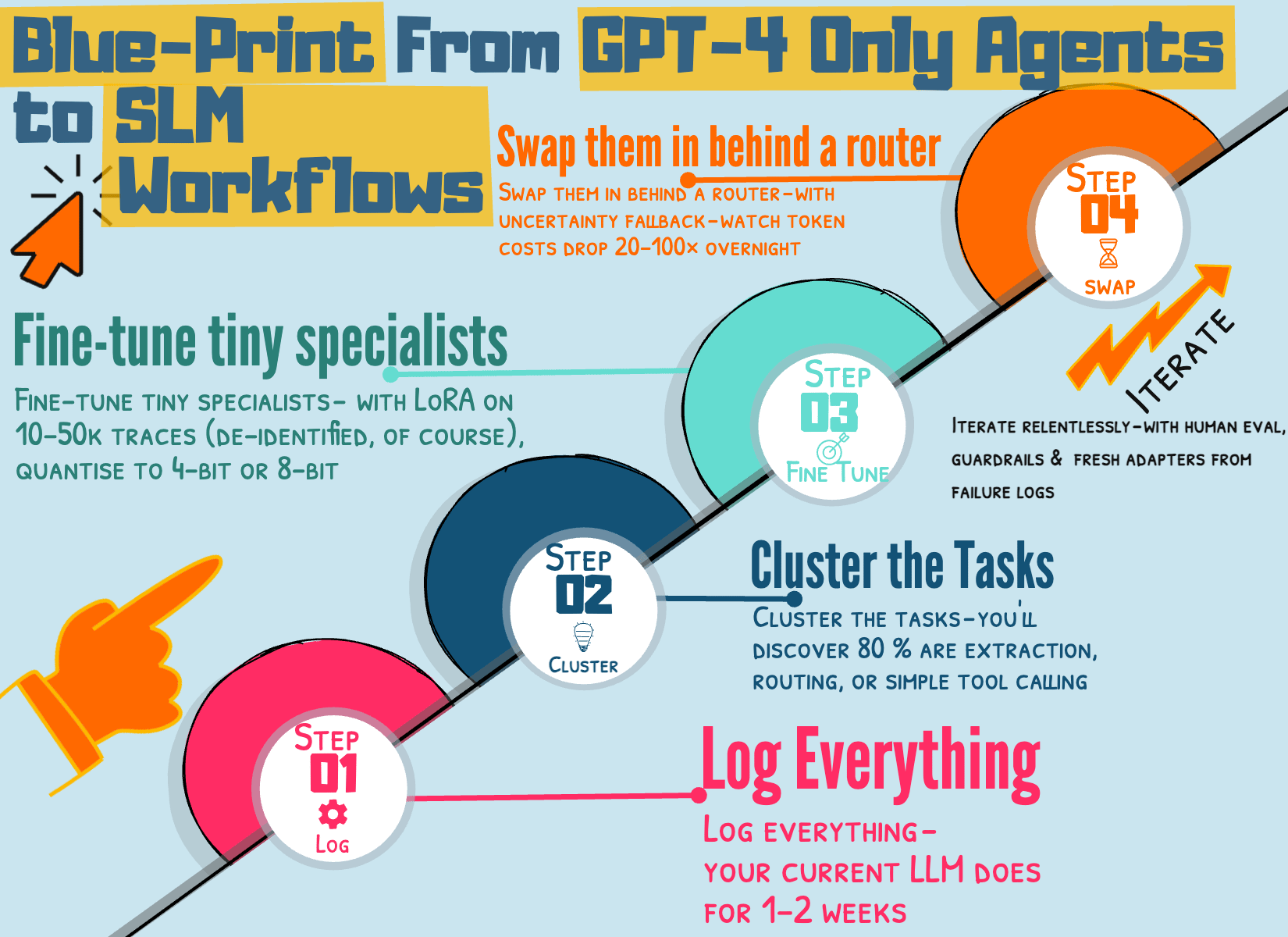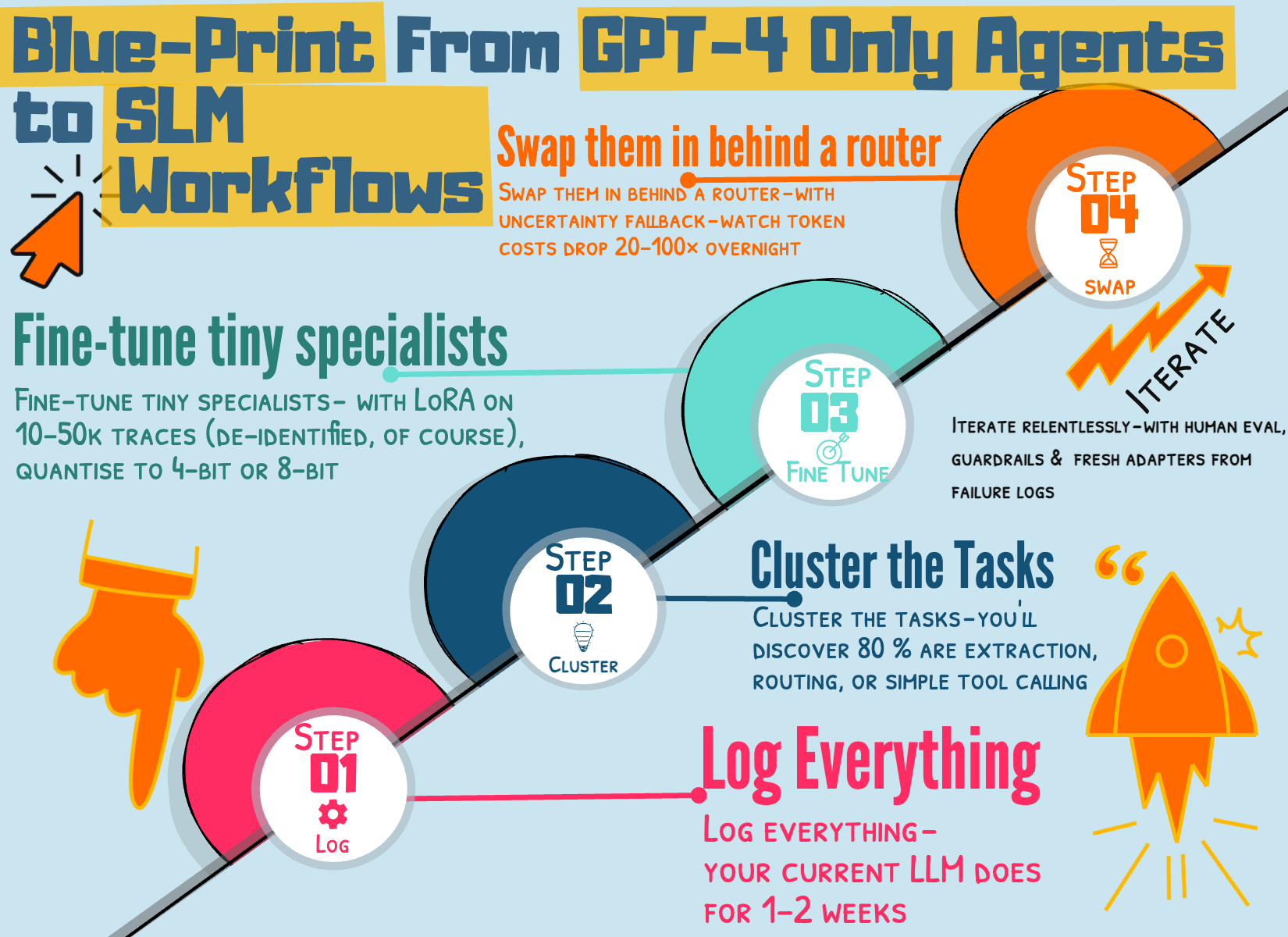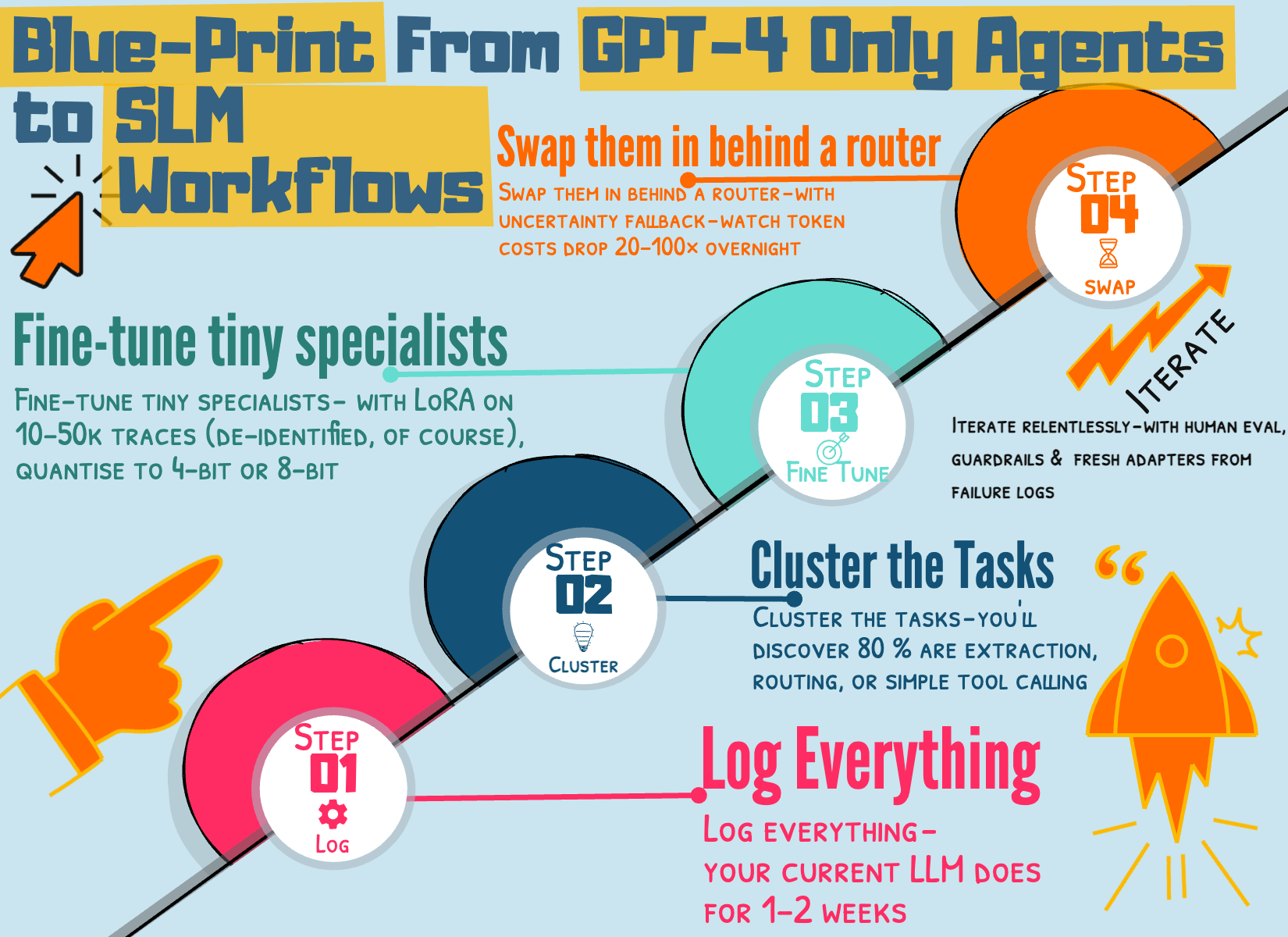
Five-step blueprint with multiple teams moving from GPT-4-only agents to SLM-default:
Log everything — your current LLM does for 1–2 weeks
Cluster the tasks — you’ll discover 80 % are extraction, routing, or simple tool calling
Fine-tune tiny specialists — with LoRA on 10–50k traces (de-identified, of course), quantise to 4-bit or 8-bit
Swap them in behind a router — with uncertainty fallback — watch token costs drop 20–100× overnight
Iterate relentlessly — with human eval, guardrails, and fresh adapters from failure logs
The study found…
50–100× lower token costs
Sub-300 ms latencies for routine requests
Escalation rates settling under 5 % after a few adapter refresh cycles
Dramatically tighter security posture

Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. Language Models, AI Agents, Agentic Apps, Dev Frameworks & Data-Driven Tools shaping tomorrow.
