Speculative RAG By Google Research
This study shows how to enhance Retrieval Augmented Generation (RAG) through Drafting


Why RAG
Emergent Capabilities
Up until recently, LLMs were found to possess emergent capabilities, which are unexpected functionalities that arise during interactions with users or tasks.
Examples of these capabilities include:
Problem-Solving: LLMs can provide insightful solutions to tasks they weren’t explicitly trained on, leveraging their language understanding and reasoning abilities.
Adaptation to User Inputs: LLMs can tailor their responses based on specific user inputs or contexts, showing a degree of personalisation in their interactions.
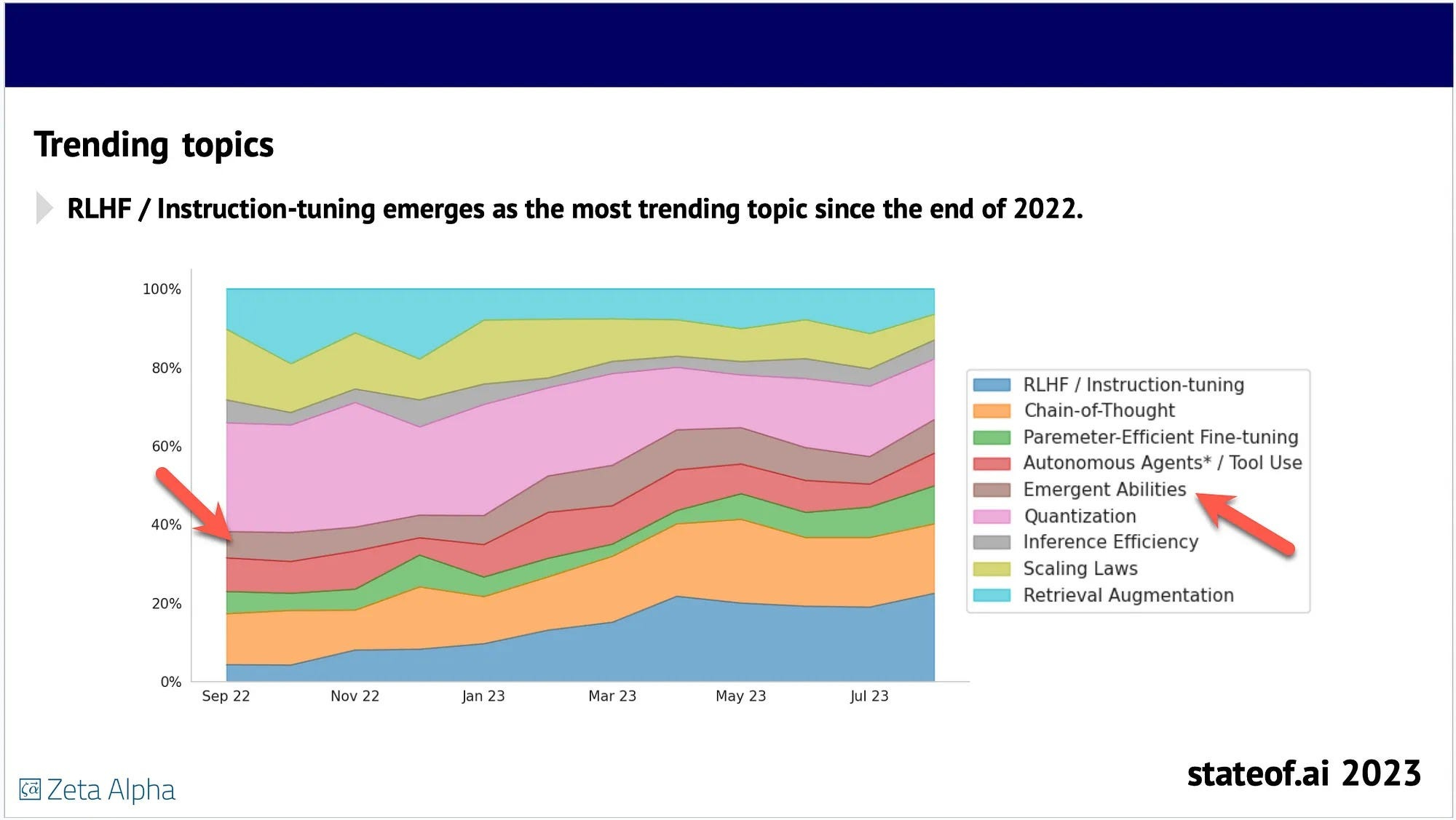
Contextual understanding allows LLMs to generate responses that are relevant and appropriate to the given context, even if it’s not explicitly stated in the prompt.
The phenomenon of emergent capabilities led organisations to explore unknown LLM functionalities. However, a recent study disproved the concept, revealing that what appeared to be emergent abilities was actually the LLMs’ strong response to provided context.

Instruction & Contextual Reference
LLMs respond well to instructions at inference and excel when a prompt includes contextual reference data. Numerous studies have empirically proven that LLMs prioritise contextual knowledge supplied at inference over data the model has been fine-tuned on.
In-Context Learning
In-context learning is the ability of a model to adapt and refine its responses based on the specific context provided by the user or task.
This process enables the model to generate more relevant and coherent outputs by considering the context in which it is operating.
Hallucination
Providing an LLM with a contextual reference at inference and hence implementing in-context learning, hallucination is mitigated.
Retrieval augmented generation (RAG) combines the generative abilities of large language models (LLMs) with external knowledge sources to provide more accurate and up-to-date responses.
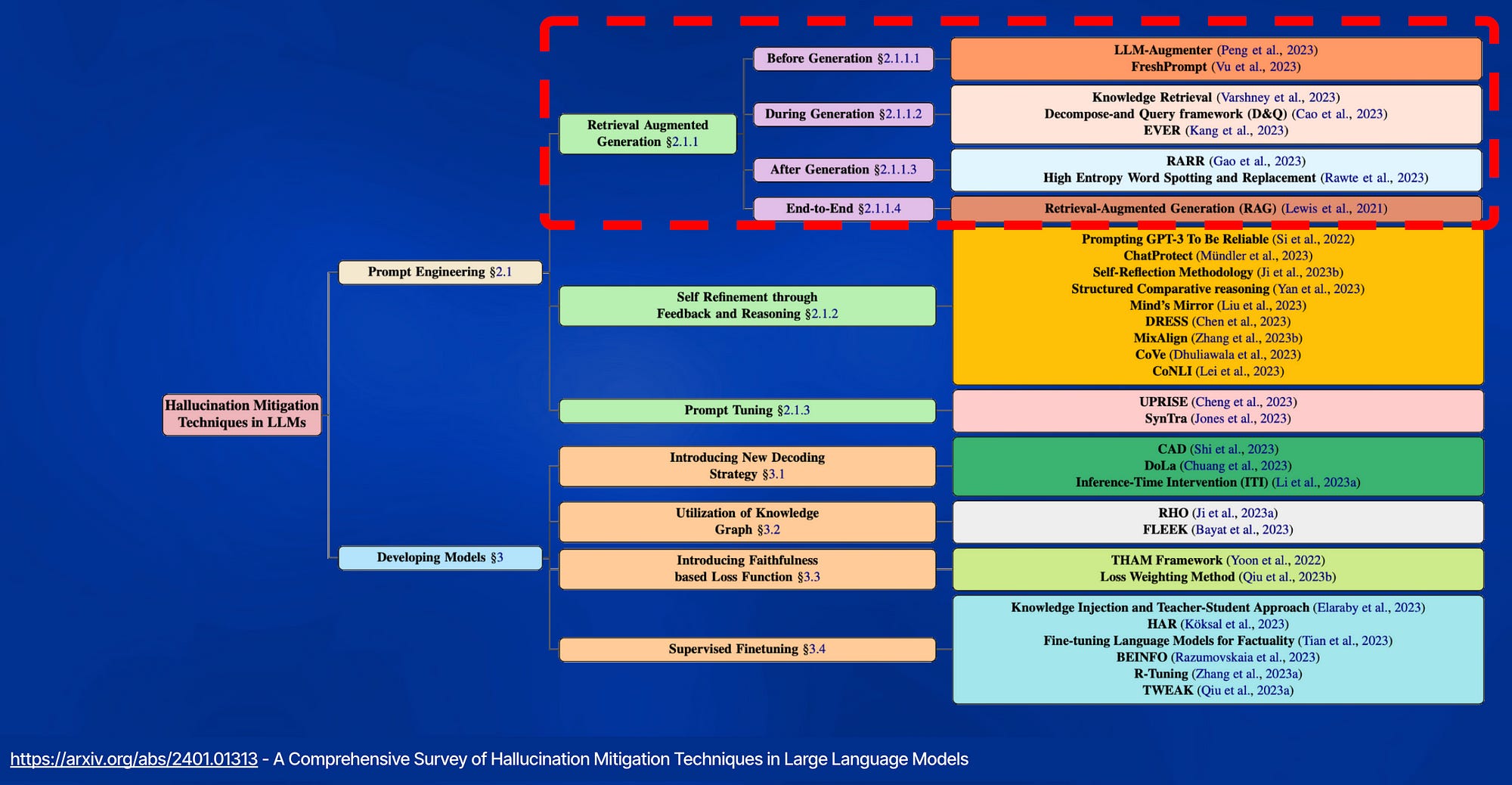
Recent RAG advancements focus on improving retrieval outcomes through iterative LLM refinement or self-critique capabilities acquired through additional instruction tuning of LLMs.
Speculative RAG
The image below shows different approaches to RAG, including:
Standard RAG,
Self-Reflective RAG &
Corrective RAG.
Standard RAG: According to Google, Standard RAG incorporates all documents into the prompt, increasing input length and slowing inference. In principle this is correct, but there are variations where summarisation is used, reranking is employed, and user feedback is requested.
There are also in-depth studies on chunking strategies and how to optimise the segmenting of context within relevant chunks.
Self-Reflective RAG requires specialised instruction-tuning of the general-purpose language model (LM) to generate specific tags for self-reflection.
Corrective RAG uses an external retrieval evaluator to refine document quality. This evaluator focusses solely on contextual information without enhancing reasoning capabilities.
Speculative RAG leverages a larger generalist LM to efficiently verify multiple RAG drafts produced in parallel by a smaller, specialised LM.
Each draft is generated from a distinct subset of retrieved documents, providing diverse perspectives on the evidence while minimising the number of input tokens per draft.
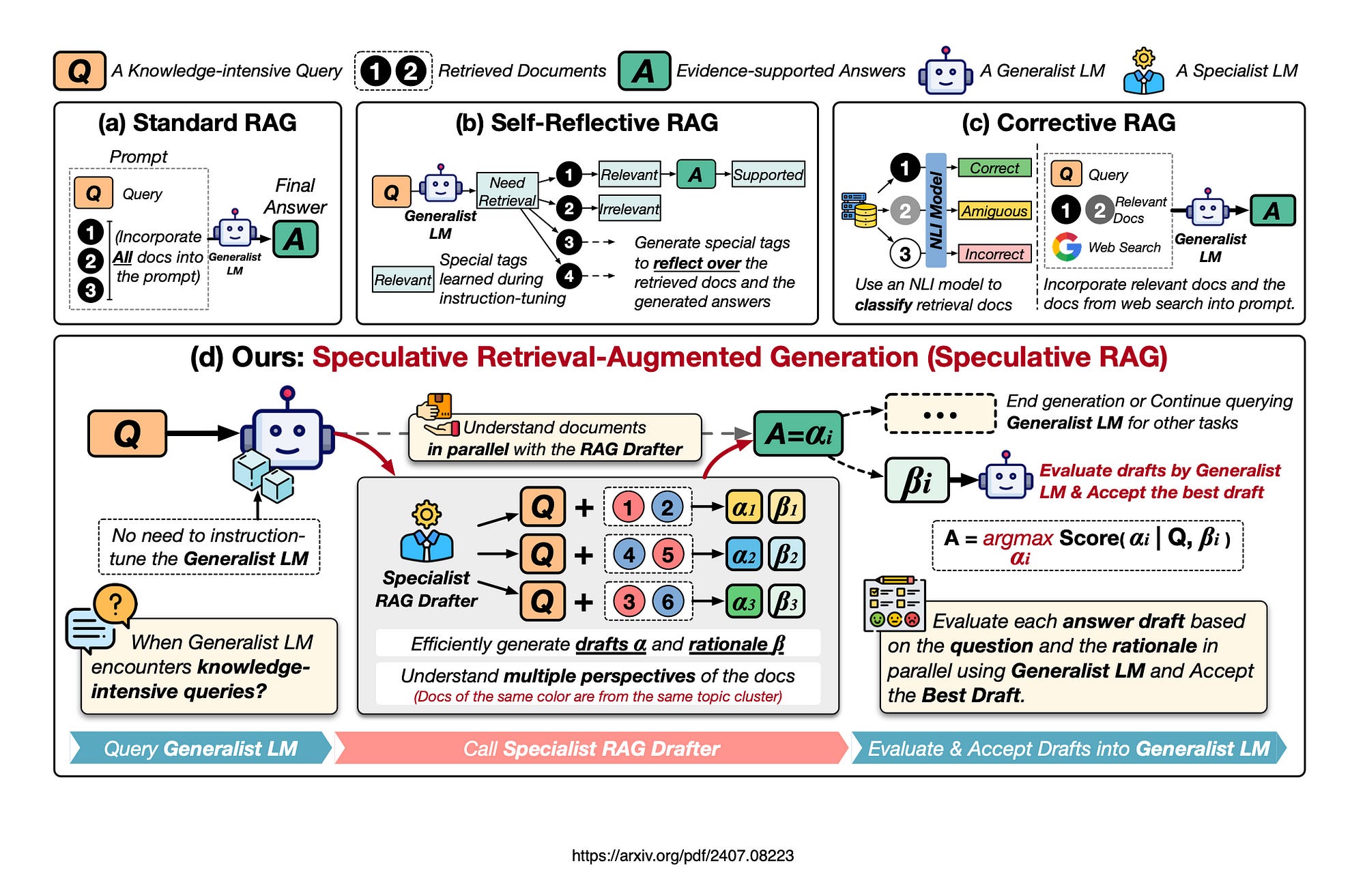
Speculative RAG is a framework that uses a larger generalist language model to efficiently verify multiple RAG drafts produced in parallel by a smaller, specialised distilled language model.
Each draft is based on a distinct subset of retrieved documents, providing diverse perspectives and reducing input token counts per draft.
According to the research, this method enhances comprehension and mitigates position bias over long contexts. By delegating drafting to the smaller model and having the larger model perform a single verification pass, Speculative RAG accelerates the RAG process.
Experiments show that Speculative RAG achieves state-of-the-art performance with reduced latency.
Improving accuracy by up to 12.97% and reducing latency by 51% compared to traditional RAG systems.
The How
This new RAG framework uses a smaller specialist RAG drafter to generate high-quality draft answers.
Each draft comes from a distinct subset of retrieved documents, offering diverse perspectives and reducing input token counts per draft.
The generalist LM works with the RAG drafter without needing additional tuning.
It verifies and integrates the most promising draft into the final answer, enhancing comprehension of each subset and mitigating the lost-in-the-middle phenomenon.
Google believes this method significantly accelerates RAG by having the smaller specialist LM handle drafting, while the larger generalist LM performs a single, unbiased verification pass over the drafts in parallel.
Extensive experiments on four free-form question-answering and closed-set generation benchmarks demonstrate the superior effectiveness and efficiency of this method.
Key Considerations
This study is a good example of how Small Language Models are being used on a larger framework which employs model orchestration.
SLMs are leveraged for their reasoning capabilities, for which they have been specifically created.
SLMs are ideal in this scenario, as they are not required to be knowledge intensive in nature for this implementation. Relevant and contextual knowledge is injected at inference.
The aim of this framework is to optimise token count and hence safe cost.
Reducing latency by 51% compared to conventional RAG systems.
Enhances accuracy by up to 12.97%.
Avoid fine-tuning of models.
Multiple RAG drafts are produced in parallel by smaller, specialised Language Models.
This smaller, specialised RAG model, excels at reasoning over retrieved documents and can rapidly produce accurate responses. This reminds of SLMs Orca-2 and Phi-3 which were trained to have exceptional reasoning capabilities.
The best results were achieved with the RAG drafter being the Mistral 7B SLM.
And the verifier Mixtral 8x7B.
I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.