Static Graph Data vs. Dynamic Graph Library
Graph (Flows) Representations is something very familiar to Conversational Designers & Chatbot Builders. In recent times this has been superseded by dynamic and unsupervised Reasoning and Action seque

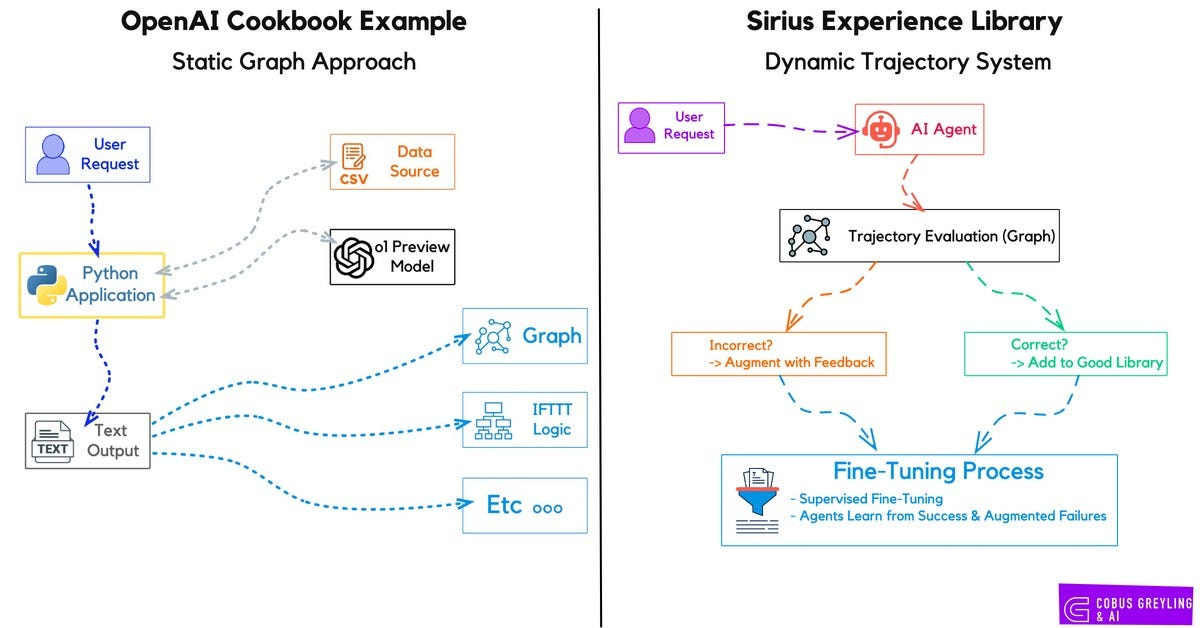
I want to draw an interesting parallel between recent research from OpenAI (top left) and a research paper I read recently (top right).
The experience library in the SiriuS paper share conceptual similarities with the idea of structured reasoning flows, like those explored in OpenAI’s work with this notebook, where training documents were converted into graph (flows) data and procedural representations.
Reuse the how of problem-solving
In OpenAI’s case, the notebook refers to efforts like their research on representing complex processes — such as procedure or task workflows — as graphs, where nodes represent steps, decisions, or states, and edges capture the logical or sequential dependencies between them.
This structured approach allows an AI to not just memorise outcomes but understand and navigate the procedural “flow” of reasoning, much like following a recipe from ingredients to a finished dish.
In the SiriuS framework, the experience library similarly preserves the “flow of reasoning” by storing trajectories — sequences of steps that led to successful task resolutions.
More on SiriuS
While the paper doesn’t explicitly mention converting these trajectories into graph data, the concept aligns: each trajectory could theoretically be represented as a graph, with nodes as individual reasoning steps (for example, a hypothesis, a deduction, or a negotiation move) and edges as the transitions or dependencies linking them.
The library’s emphasis on retaining high-quality trajectories mirrors the OpenAI notebook goal of distilling procedural knowledge into a reusable format, enabling the system to revisit and replicate effective paths rather than relying on unstructured, brute-force generation.
The Difference
Where the two approaches diverge is in their application and dynamism.
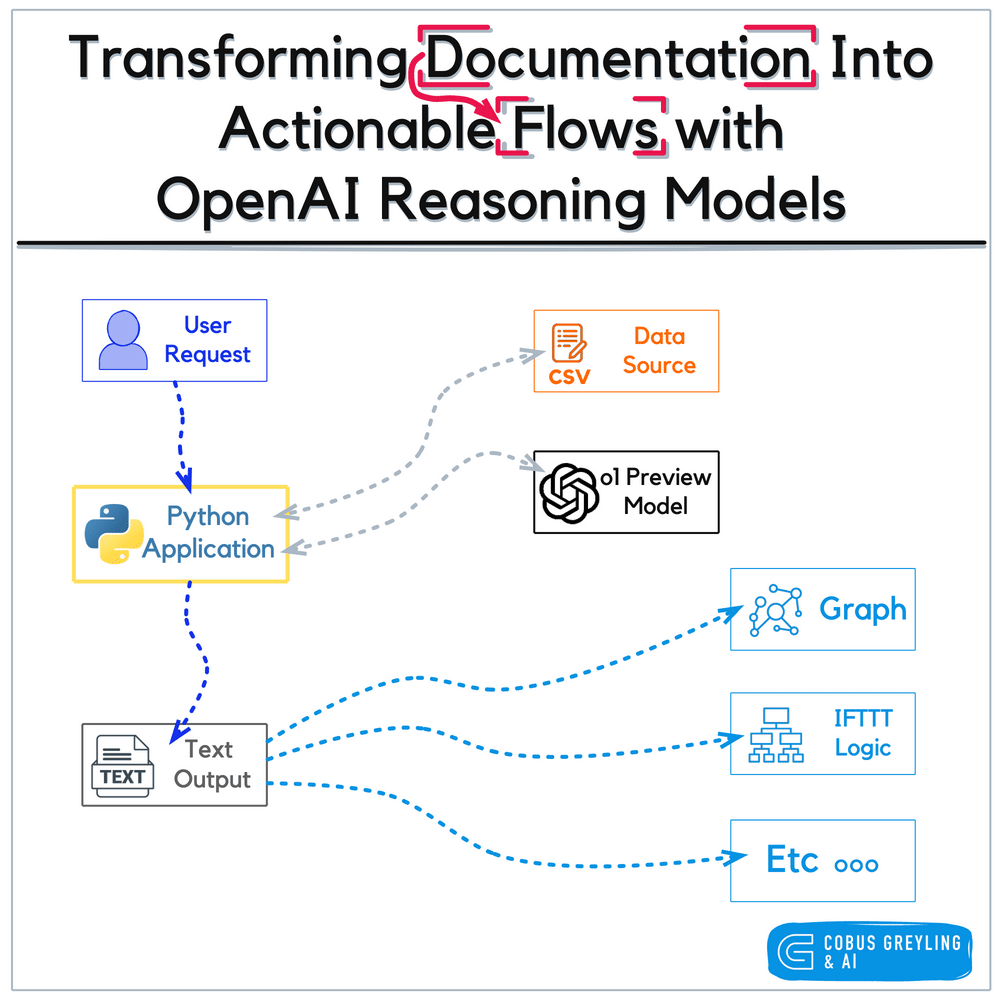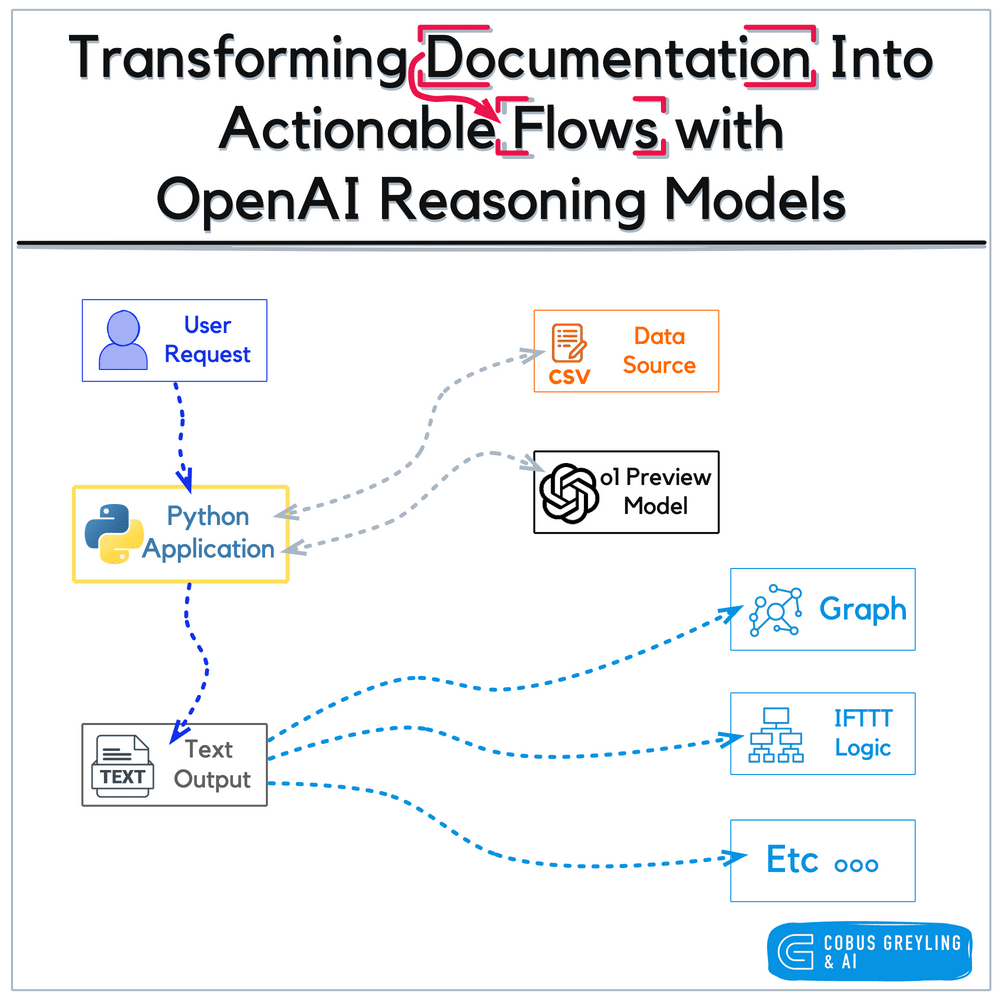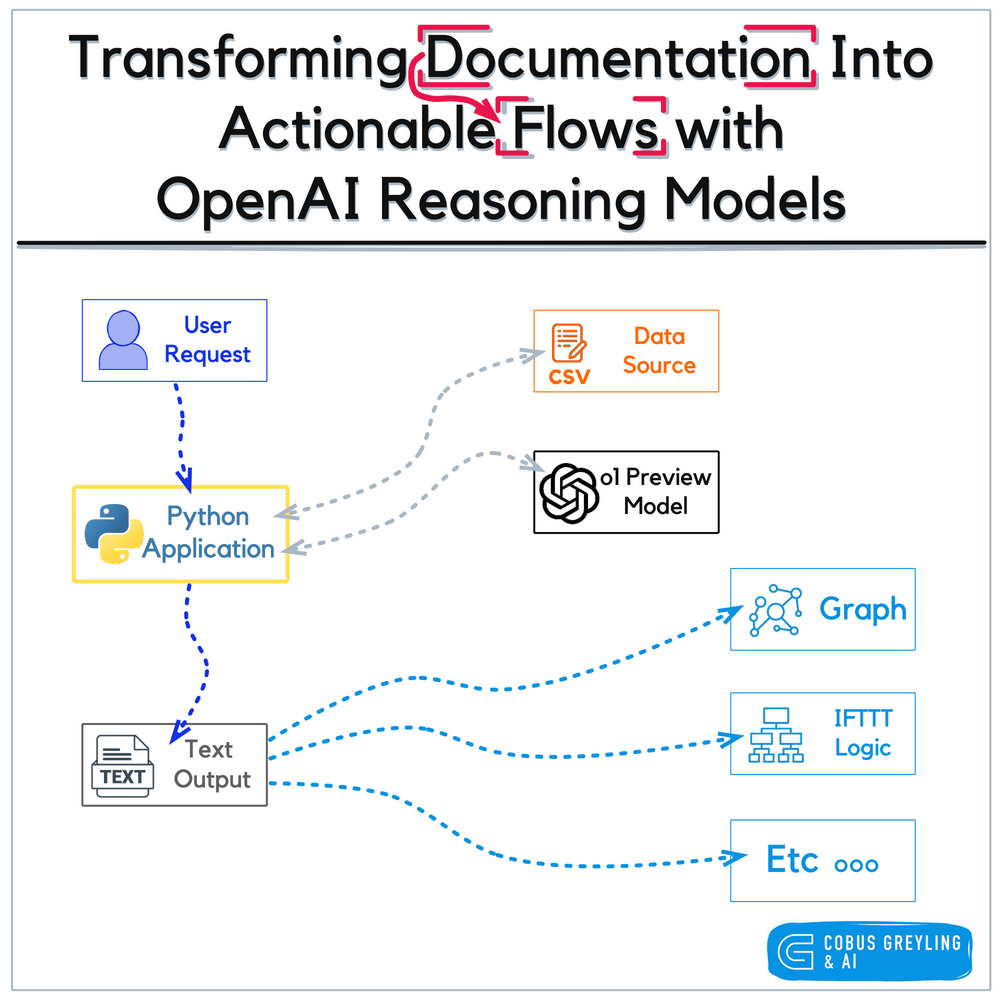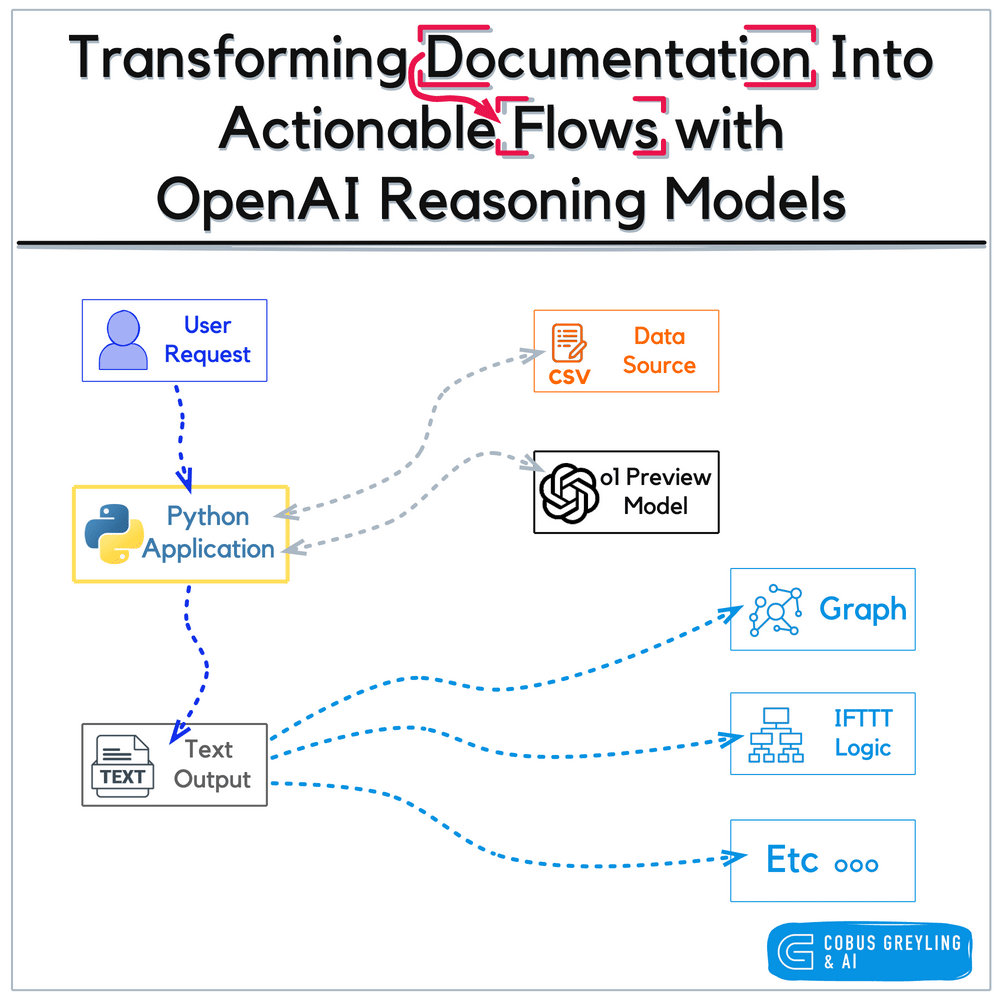
OpenAI’s notebook approach to graph serves as a static or semi-static training artefact, transforming human-authored documents into a graph structure for human guidance and task automation in a RPA fashion.
In contrast, the SiriuS experience library is a live, self-updating resource, built and refined in real-time as agents tackle tasks, incorporating both successes and corrected failures through augmentation.
This adaptability makes it more akin to a self-evolving playbook than a fixed graph “path”, though both share the core idea of leveraging structured reasoning to enhance AI performance.
Inspectability
The resemblance also highlights a broader trend in AI research: moving beyond opaque, end-to-end models toward systems that can explicitly encode and reuse the how of problem-solving.
By saving the reasoning flow — whether as graphs in OpenAI’s case or trajectories in SiriuS — researchers aim to make AI more interpretable, efficient, and capable of bootstrapping its own improvement.
Building An Experience Library
Its significance lies in the development of an “experience library,” a repository of high-quality reasoning trajectories that retain successful reasoning steps, providing a robust training set to improve agent performance.
The figure below illustrates this framework, depicting how the experience library is constructed and utilised alongside a library augmentation process that refines unsuccessful trajectories, further enriching the system’s learning resources.
According to the study, this approach results in notable performance boosts, ranging from 2.86% to 21.88% in tasks like reasoning and biomedical QA, as well as improved agent negotiation in competitive settings.
Overall, SiriuS represents a step forward in creating self-improving AI systems, reducing dependency on manual tuning and enhancing adaptability across complex tasks.

Finally
OpenAI’s graph approach is a stepping stone, but it’s too tethered to human oversight — someone’s got to write the docs, someone’s got to update them.
SiriuS sidesteps that bottleneck, letting agents bootstrap their own process.
Sure, it’s not perfect — building a library that doesn’t bloat or drift off-course is a challenge — but the potential to ditch fragile prompts and manual tuning is worth it.
Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. From Language Models, AI Agents to Agentic Applications, Development Frameworks & Data-Centric Productivity Tools, I share insights and ideas on how these technologies are shaping the future.