Teaching LLMs To Say, “I don’t know”
Instead of stating that it does not know, LLMs hallucinate. Hallucination can best be described as highly plausible, succinct & reasonable responses from a LLM, but which is factually incorrect.

Introduction
A few years back IBM Watson Assistant introduced functionality to define and detect user requests which falls outside of the chatbot’s domain. I believe this was one of the first forays into the realm of defining what the ambit of the chatbot was.
Chatbots in the early days were plagued by the problem of getting stuck on “Sorry, I can’t help you with that”. And subsequently encouraging the user to rephrase their input without any attempt from the chatbot to facilitate the progression of the conversation.
Fast Forward To LLMs
With Large Language Models (LLMs) we are on the other side of the spectrum, where the Conversational UI always responds with an answer and rarely says, I don’t know.
Compared to traditional chatbot architecture and performance, LLMs mesmerise us with their outstanding ability of fluency, coherence and ability to maintain context. But, LLMs are still likely to hallucinate unfaithful and nonfactual responses.
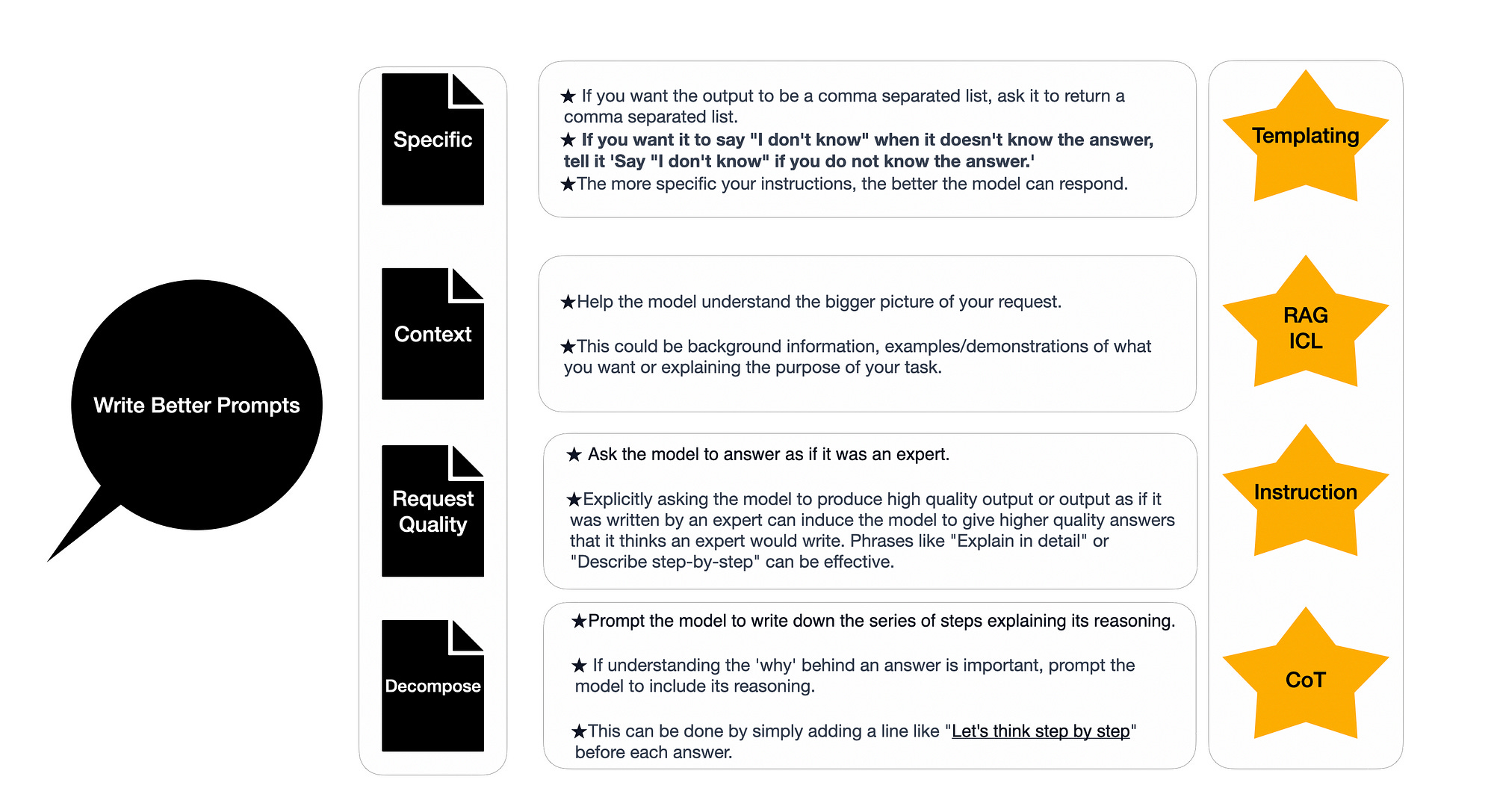
The image below lends some guidance on how LLMs can be guided via prompt engineering to yield better responses. Some prompting techniques require the introduction of complexity and structure to be implemented.
Model Cutoff Date
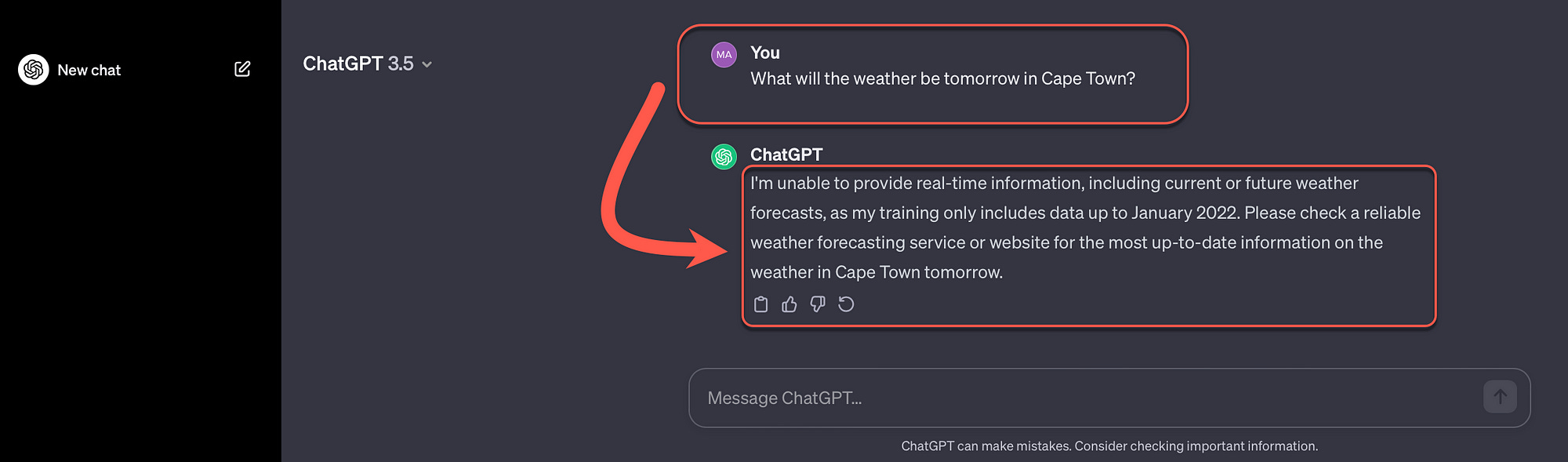
LLMs have a definite time-stamp and cut-off date for their models based on the data it was trained on. It has been proven that LLMs perform better when a query is related to data the LLM have seen during training. As apposed to data the model is seeing for the first time.
Consider the response below from ChatGPT where a question is asked about the weather which is highly contextual demanding recent information.
When models are trained to create the base model, a large volume of data (parametric knowledge) is embedded in the LLM.
Fine-tuning, involves knowledge which most probably does not form part of the parametric knowledge. Fine-tuned knowledge will most probably include company and industry specific information and are often supplemented with RAG, In-Context Learning (ICL).
Pre-training embeds a large volume of parametric knowledge, while fine-tuning may involve knowledge that is not necessarily in the parametric knowledge. Hence the study focusses on exploring the benefits of differentiating instruction tuning data based on parametric knowledge.
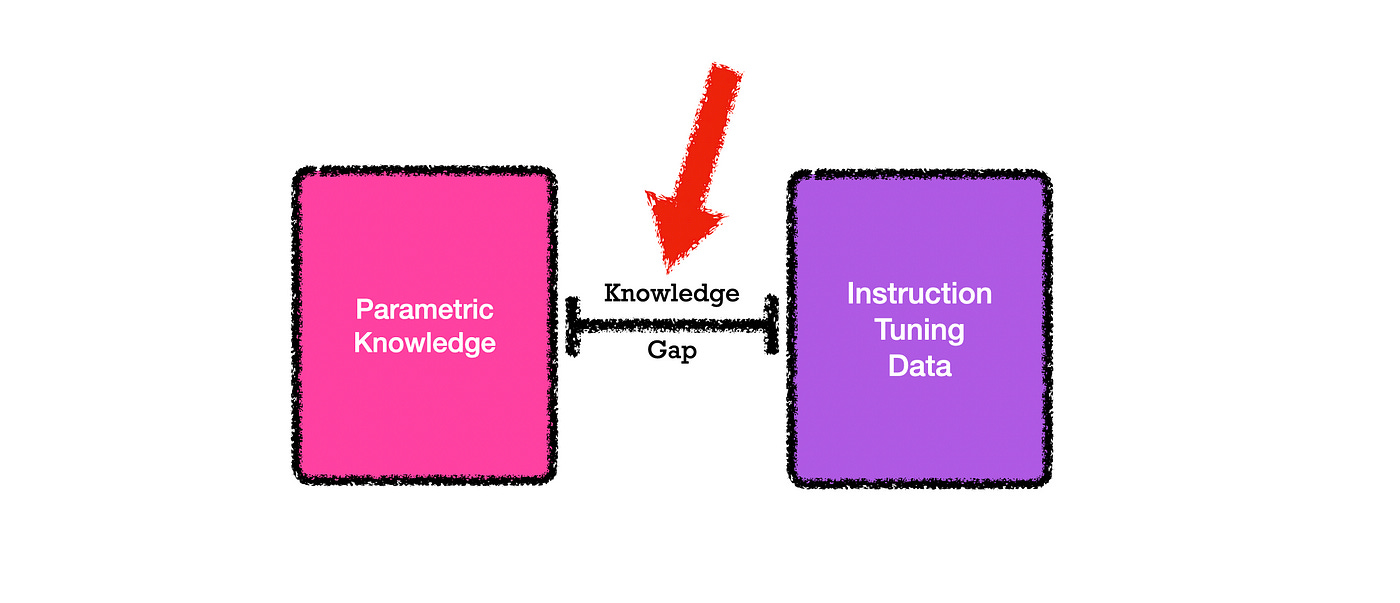
Back To The Study
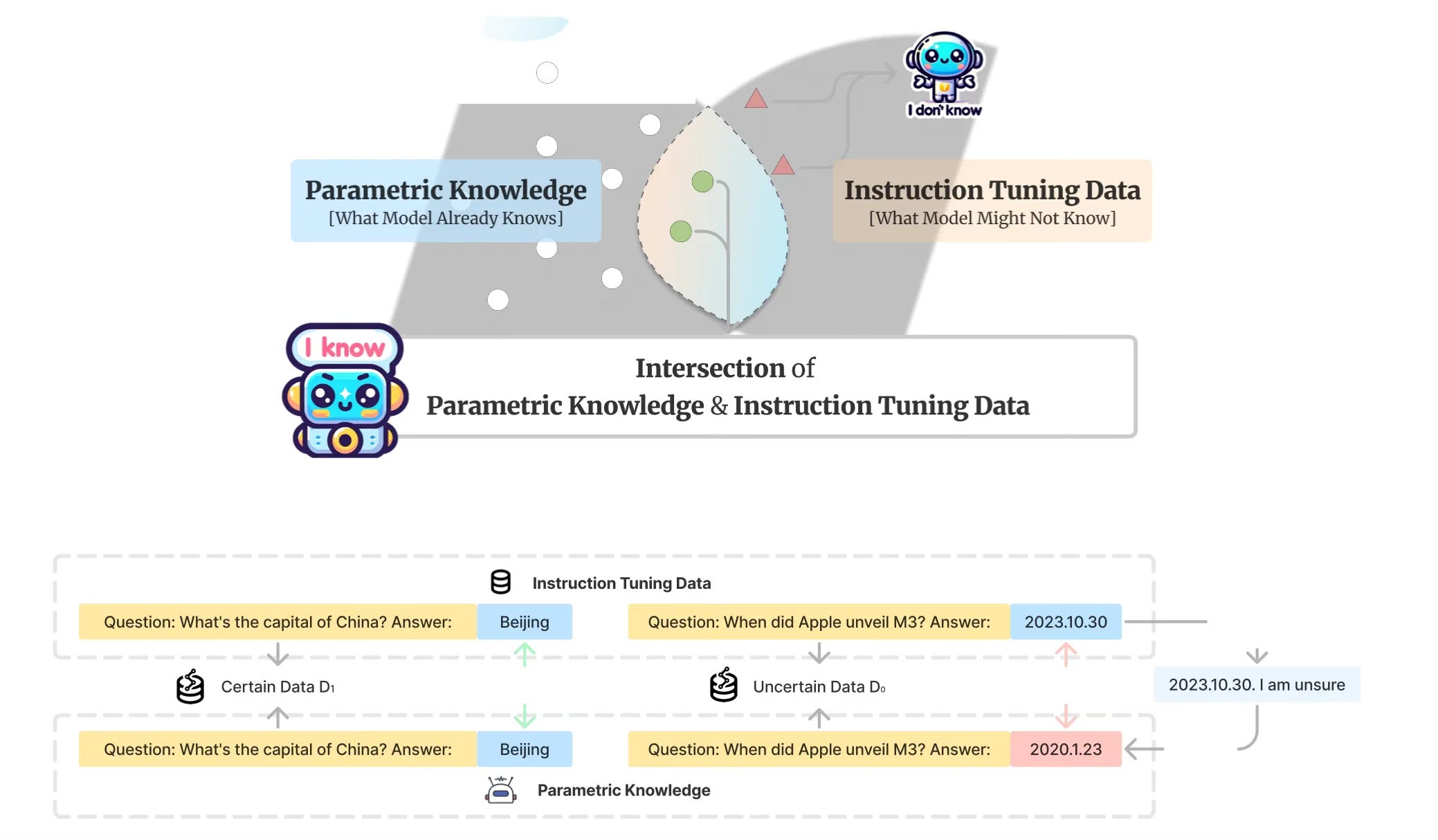
Considering the image below, the study looks at the gap between knowledge the model has and knowledge the model is not trained on.
Identifying and measuring the gap between existing knowledge and data submitted at inference can help the model to avoid hallucination and respond appropriately.
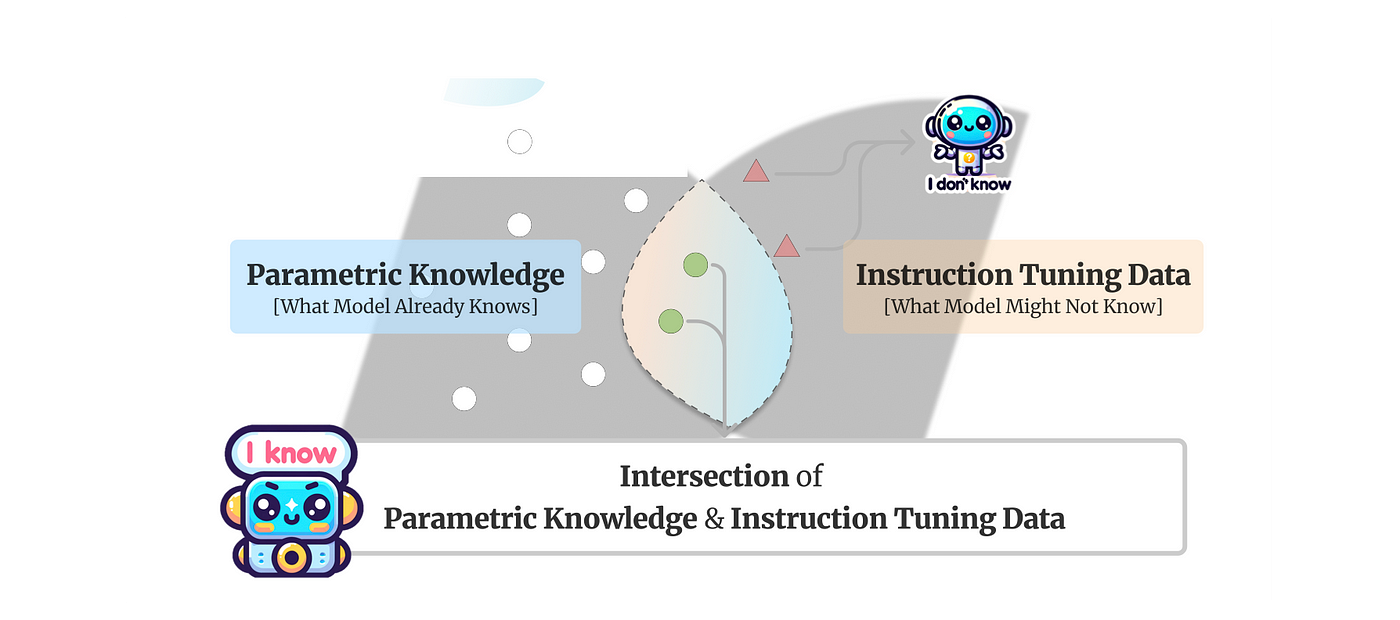
Training a model exclusively on correct answers inadvertently teaches the LLM to guess an answer rather than admit its ignorance.
The study states that if a model is not trained to articulate “I don’t know” as a response, it remains unequipped to do so when confronted with unknowns.
Models trained on the intersection of parametric knowledge and the instruction tuning data, leading to a model refusing to answer unknown questions.
The study introduces Refusal-Aware Instruction Tuning (R-Tuning).
R-Tuning aims to train the model with refusal-aware answering ability by recognising when they should claim knowledge, or plainly state the knowledge is not available.
R-Tuning has two steps:
Measure the knowledge gap between parametric knowledge and the instruction tuning data, and identify uncertain questions.
Construct the refusal-aware data by padding the uncertainty expression after the label words, and then fine-tune the model on the refusal-aware data.
Mitigating Hallucination
The study attributes hallucination to the significant gap between the knowledge of human-labeled instruction tuning datasets and the parametric knowledge of LLMs.
Even-though is approach might not be implemented in the detail described in the study, the way model hallucination is described and the basic principles defined are immensely useful.
Considering hallucination, current and popular approaches are:
Retrieval-Based Methods
Verification-Based Methods
In-Context Learning
Finally
This paper introduces a method called R-Tuning, aiming to enhance large language models in rejecting unfamiliar questions.
R-Tuning identifies discrepancies between instruction tuning data and the model’s knowledge, dividing the training data into certain and uncertain parts.
It then appends uncertainty expressions to create refusal-aware data.
Empirical results demonstrate R-Tuning’s superior performance over traditional instruction tuning in terms of AP score, striking a balance between precision and recall.
R-Tuning not only exhibits refusal proficiency on known data but also showcases generalisability to unfamiliar tasks, emphasizing refusal as a fundamental skill abstracted through multi-task learning, referred to as a meta-skill.
Further examination of perplexity and uncertainty in training datasets provides insight into the proposed method’s rationale.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.