

Teaching LLMs To Say “I don’t Know”
Rather than fabricating information when presented with unfamiliar inputs, models should rather recognise untrained knowledge.


Rather than fabricating information when presented with unfamiliar inputs, models should rather recognise untrained knowledge and express uncertainty or confine their responses within the limits of their knowledge.
Introduction
This study investigates how Large Language Models (LLMs) generate inaccurate responses when faced with unfamiliar concepts.
The research discovers that LLMs tend to default to hedged predictions for unfamiliar inputs, shaped by the way they were trained on unfamiliar examples.
By adjusting the supervision of these examples, LLMs can be influenced to provide more accurate responses, such as admitting uncertainty by saying “I don’t know”.
Building on these insights, the study introduces a reinforcement learning (RL) approach to reduce hallucinations in long-form text generation tasks, particularly addressing challenges related to reward model hallucinations.
The findings are confirmed through experiments in multiple-choice question answering, as well as tasks involving generating biographies and book/movie plots.
Large language models (LLMs) have a tendency to hallucinate — generating seemingly unpredictable responses that are often factually incorrect. ~ Source
In-Context Learning (ICL)
Large language models (LLMs) demonstrate remarkable abilities in in-context learning (ICL), wherein they leverage surrounding text acting as a contextual reference to comprehend and generate responses.
Through continuous exposure to diverse contexts, LLMs adeptly adapt their understanding, maintaining coherence and relevance within ongoing discourse. This adaptability allows them to provide nuanced and contextually appropriate responses, even in complex or evolving situations.
By incorporating information from previous interactions, LLMs enhance their contextual understanding, improving performance in tasks such as conversation, question answering, and text completion. This capability underscores the potential of LLMs to facilitate more natural and engaging interactions across various domains and applications.
Key Findings
LLMs have a tendency to hallucinate.
This behaviour is especially prominent when models are queried on concepts that are scarcely represented in the models pre-training corpora; hence unfamiliar queries.
Instead of hallucination, models should instead recognise the limits of their own knowledge, and express their uncertainty or confine their responses within the limits of their knowledge.
The goal is to teach models this behaviour, particularly for long-form generation tasks.
The study introduces a method to enhance the accuracy of long-form text generated by LLMs using reinforcement learning (RL) with cautious reward models.
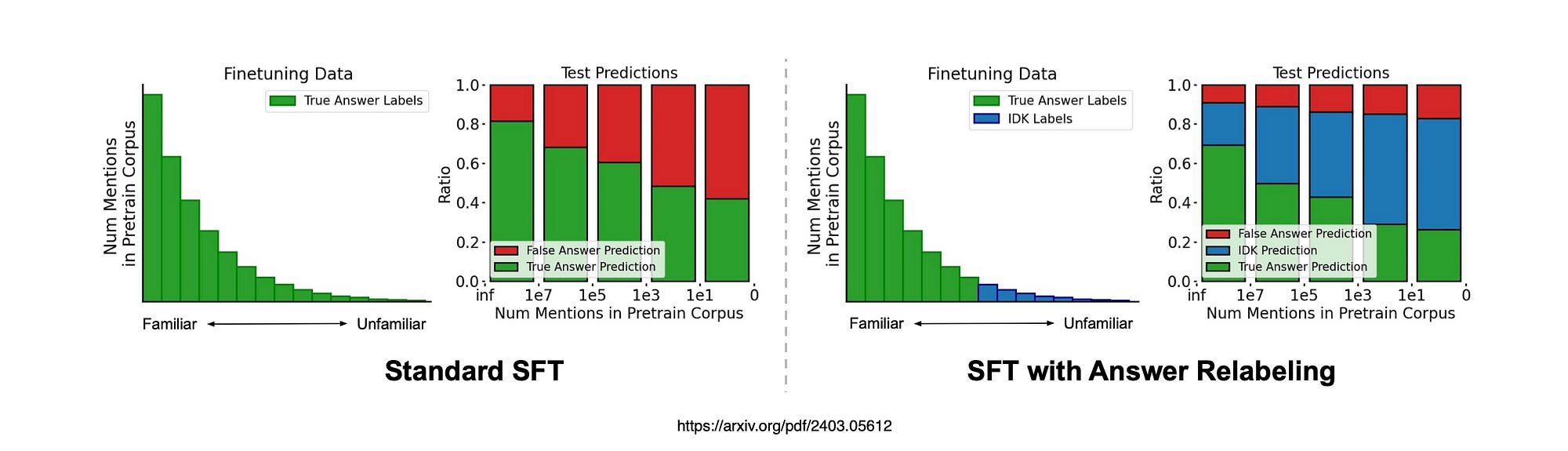
The comparison displays how two types of model fine-tuning perform on the TriviaQA dataset.
The long-tail visuals represent the data used for fine-tuning, while the bar graphs show prediction results.
The standard model, fine-tuned with true answer labels, tends to inaccurately predict false answers as test inputs become less familiar.
In contrast, the model with answer relabelling is fine-tuned with true labels for familiar inputs and I don’t know labels for unfamiliar ones.
This model more frequently predicts I don’t know as inputs become less familiar, indicating a more cautious approach to unfamiliar topics.
Supervised Fine-Tuning
Identify examples in the fine-tuning data for which the model cannot generate the correct answer.
Relabel those examples to have a hedged or abstaining response, for example, I don’t know.
Fine-tune the base model with this re-labeled dataset using SFT.
In Conclusion
There has been a number of recent studies focussing on the aspect I like to refer to as data design. Where fine-tuning data is designed in such a way, that it enhances the capabilities of the language model. As apposed to imbuing the model with knowledge.
Past studies have looked at improving the reasoning capabilities of a language model by masking parts of the training data.
Small Language Models typically lack self-awareness & tend to exhibit greater confidence in their generated responses. Following an approach of Prompt Erasure & Partial Answer Masking (PAM) drastically improves the quality of SLM responses.
This research from Google DeepMind again shows how the behaviour of the model can be altered to state when it does not have an answer to a questions.
I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.