Temporal AI Agents
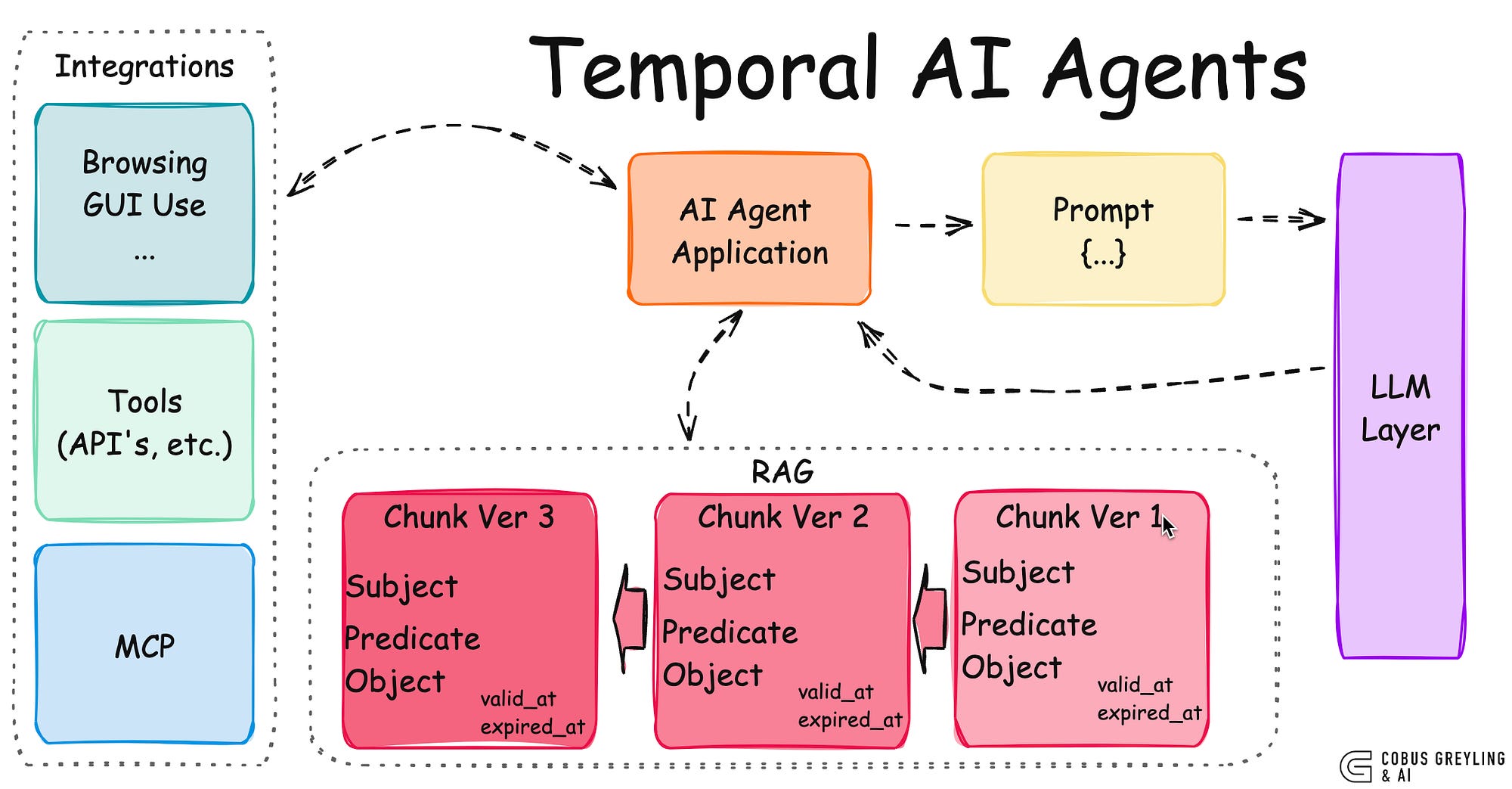
The Temporal AI Agent architecture treats chunks as micro-memory stores…

In Short
One of building blocks of AI Agents is memory…
Memory informs the AI Agents on the context of the current conversation from previous conversations.
Memory is also important from continuity perspective and optimising the user experience; the user does not have to repeat or re-input information which can be drawn from conversation history.
RAG is aimed at providing context at inference, leveraging the In-Context Learning (ICL) capabilities of Language Models.
RAG is not necessary aimed memory but rather context which is up to date; RAG is also aimed at injecting the prompt with the optimal chunks of data. Not too short for a shortfall of context, not too much to increase cost, overhead and latency.
Temporal AI Agents can be seen as a hybrid approach to memory and RAG. Will it replace Memory per se? No.
But, it enhances RAG by giving a contextual history and depth to the AI responses.
Think of the Temporal AI Agent architecture as treating chunks as micro-memory stores.
Think of the Temporal AI Agent architecture as treating chunks as micro-memory stores.
Each chunk — semantically segmented raw data is processed into time-stamped triplets and events that capture specific facts or relationships, like revenue figures or role changes, with temporal metadata, for example valid_at, expired_at).
These triplets, stored in a knowledge graph, act as compact, contextual memory units that preserve both the content and its temporal relevance.
This makes them micro-memory stores: discrete, structured representations of information tied to a specific time frame, enabling the system to track evolving contexts for Retrieval-Augmented Generation (RAG) or other queries.
Unlike a full-fledged agent memory system with episodic or procedural components, these chunks focus narrowly on time-aware facts, forming a lightweight, history-preserving backbone for dynamic data.
What Are Temporal AI Agents?
Temporal AI Agents works well to manage tasks with time-sensitive information.
They combine knowledge graphs — structured data stores of entities and relationships — with AI Agents that process and update chunks over time.
A knowledge graph here holds facts as triplets (subject-predicate-object), each tagged with timestamps like:
valid_at or
expired_at.
The temporal part means the system tracks how data changes.
AI Agents handle reasoning over these changes, making decisions or predictions that account for history and progression.
For example, in analysing earnings call transcripts, the system processes text into chunks, extracts events, and stores them in the graph.
This setup goes beyond static data handling.
It enables applications like scheduling, forecasting, or real-time analytics where context must stay fresh.
Keeping RAG Chunks Current
Temporal AI Agents enhance RAG.
Standard RAG pulls chunks of data from a store to inform Language Model responses, but in most cases chunks are not versioned, with no history or historic context available.
Temporal AI Agents fix this by keeping chunks — semantic pieces of raw data like transcript segments — current.
New data gets ingested, chunked using tools like SemanticChunker with embeddings, and turned into time-stamped triplets.
The system then checks for outdated info and updates the graph without deleting old entries.
This creates a dynamic, evolving store where RAG queries pull the latest, context-aware data. But older chucks are there to serve as a type of micro-memory for the AI Agent.
In practice, this means RAG becomes more reliable for dynamic scenarios, like monitoring financial workflows.
How Outdated Chunks Are Identified and Replaced
The process starts with ingestion: raw data is fetched, chunked semantically, and fed to AI Agents for extraction.
Statements are classified as static (unchanging), dynamic (evolving), or atemporal (timeless).
Triplets get timestamps and embeddings.
Identification uses the Invalidation Agent.
It compares new triplets to existing ones via:
Temporal overlap checks (do time spans intersect?).
Embedding similarity (cosine distance, threshold like 0.5).
LLM reasoning ( GPT-4o-mini detects contradictions).
Replacement is non-destructive, outdated triplets are marked with “expired_at” or “invalid_at” fields, linked to the new one via “invalidated_by.”
This preserves history for audits.
Batches handle updates efficiently and duplicates are resolved by picking the earliest invalidation time.
For long-term maintenance, archival rules prune low-relevance data based on time-to-live and scores (recency × trust × query frequency).
Triplet
A triplet is a structured representation of information in the form of a subject-predicate-object tuple.
It’s a fundamental unit for encoding relationships or facts in a knowledge graph, making it easy to store, query and reason about data.
Here’s a quick breakdown:
Subject: The entity or thing the fact is about (for example “TechNova”).
Predicate: The relationship or attribute connecting the subject to the object (for example “reported_revenue”).
Object: The value or entity related to the subject via the predicate (for example, “$10 million”).
For example, from a transcript chunk, a triplet might be:
Subject: “TechNova”
Predicate: “reported_revenue”
Object: “$10 million”
In temporal AI Agents, triplets are enriched with metadata like timestamps (valid_at, expired_at) to track when the fact is relevant, enabling time-aware reasoning.
Triplets are stored in a knowledge graph, where they can be queried or updated to maintain a dynamic, contextual memory for applications like RAG.
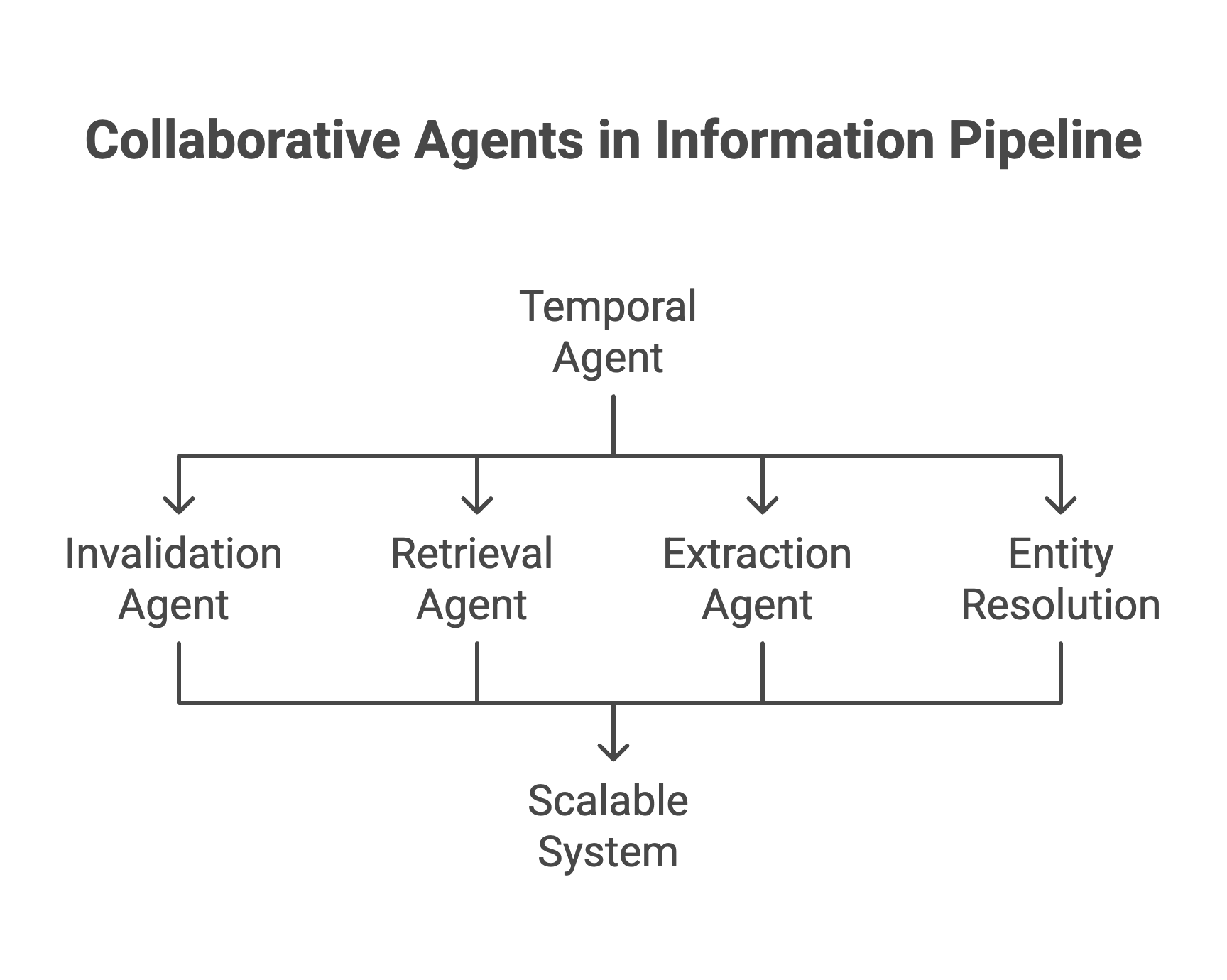
The Agents Involved
Multiple agents collaborate in this pipeline:
Temporal Agent
Core processor; extracts statements, classifies them, and integrates into the graph.
Invalidation Agent
Checks validity, marks outdated info.
Retrieval Agent
Queries the graph for answers, traversing relationships over time.
Extraction Agent
Pulls events and triplets from chunks.
Entity Resolution
Matches new entities to existing ones to avoid duplicates.
This modular design makes the system scalable.
Production Implementation
For real-world use, a scheduled routine runs at intervals ( daily or event-triggered).
It fetches new data, chunks it, processes into triplets, and invalidates outdated entries.
The notebook notes processing times (2–5 minutes per transcript), so production needs parallelism, caching and error handling.
In Closing
Temporal agents provide a straightforward way to manage changing data in AI systems.
By integrating time into knowledge graphs, they ensure accuracy in evolving contexts, useful for fields like finance or event tracking. If you’re building RAG apps, start with the notebook — it’s a solid base for experimentation.
Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. From Language Models, AI Agents to Agentic Applications, Development Frameworks & Data-Centric Productivity Tools, I share insights and ideas on how these technologies are shaping the future.