The Battle of AI Agents: Comparing Real World Performance Using Benchmarking
The AI Agent hype is real, but AI Agents need to work in the real-world scenarios, with exceptional accuracy to challenge human jobs in any meaningful way.


Like Language Models are Benchmarked against each other, AI Agents also need to be benchmarked.
In Short
The AI Agent hype is real, but AI Agents need to work in the real-world scenarios, with exceptional accuracy to challenge human jobs in any meaningful way.
What is real, is the hype…but the truth is that real-world performance of AI Agents are poor.
My message to companies touting their prowess in AI Agent technology is. the following, soon you will have to put your AI Agent through benchmarking to see its true real-world value.
There is a lack of objectivity, some have gone so far as to claim that the majority of human labor may be automated within the next few years, this is simply not true.
Agentic Workflows (Interactive Cooperative Planning & Execution Between Humans & AI Agents) is where it is at currently, and where the opportunity is.
Agentic workflows allow for a level of autonomy where automation and forward-looking planning but this is highly supervised by the user.
To assess an AI Agent’s potential in real-world work, benchmarks are needed that reflect tasks from various job categories.
Benchmarks need to be relevant, not too narrow, and include realistic tasks.
Unlike many existing benchmarks like MiniWob++ or SWE-Bench, which are either not relevant or too narrow, TheAgentCompany includes a broad range of realistic tasks typical in software engineering roles.
AI Agent adoption is linked to performance and the best AI Agent needs to be pared with the best model.
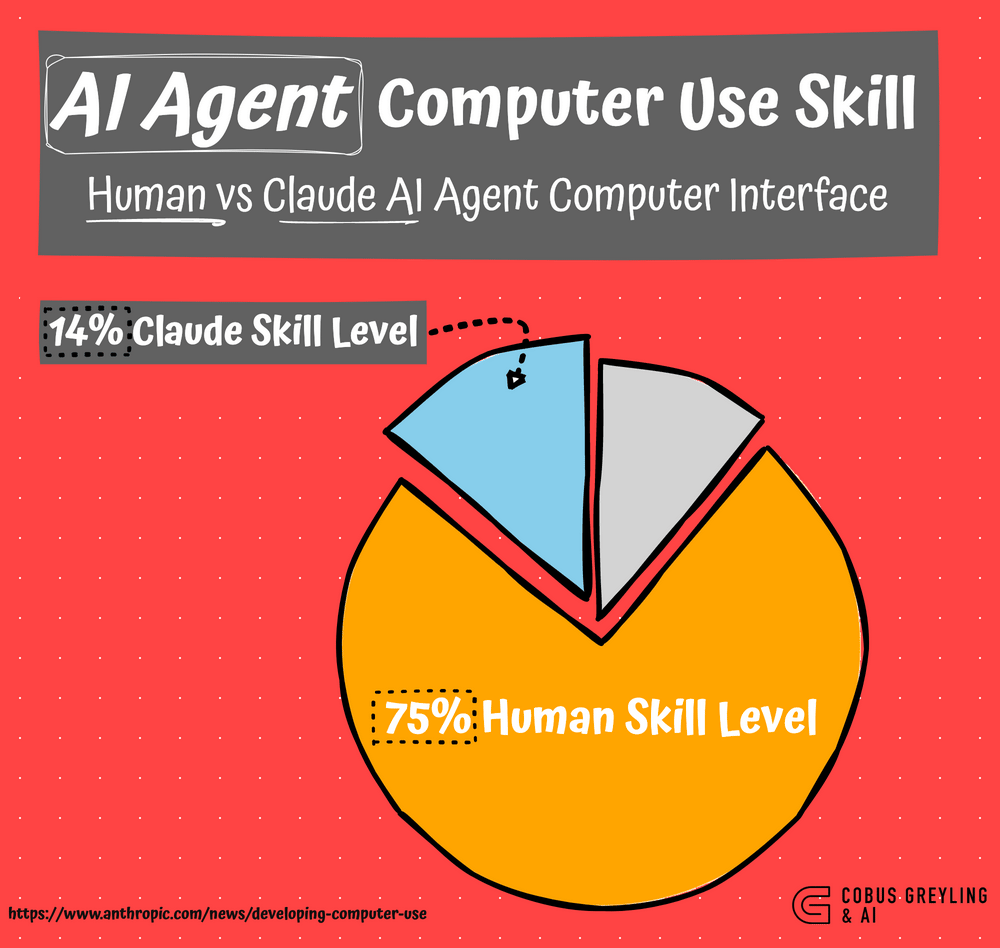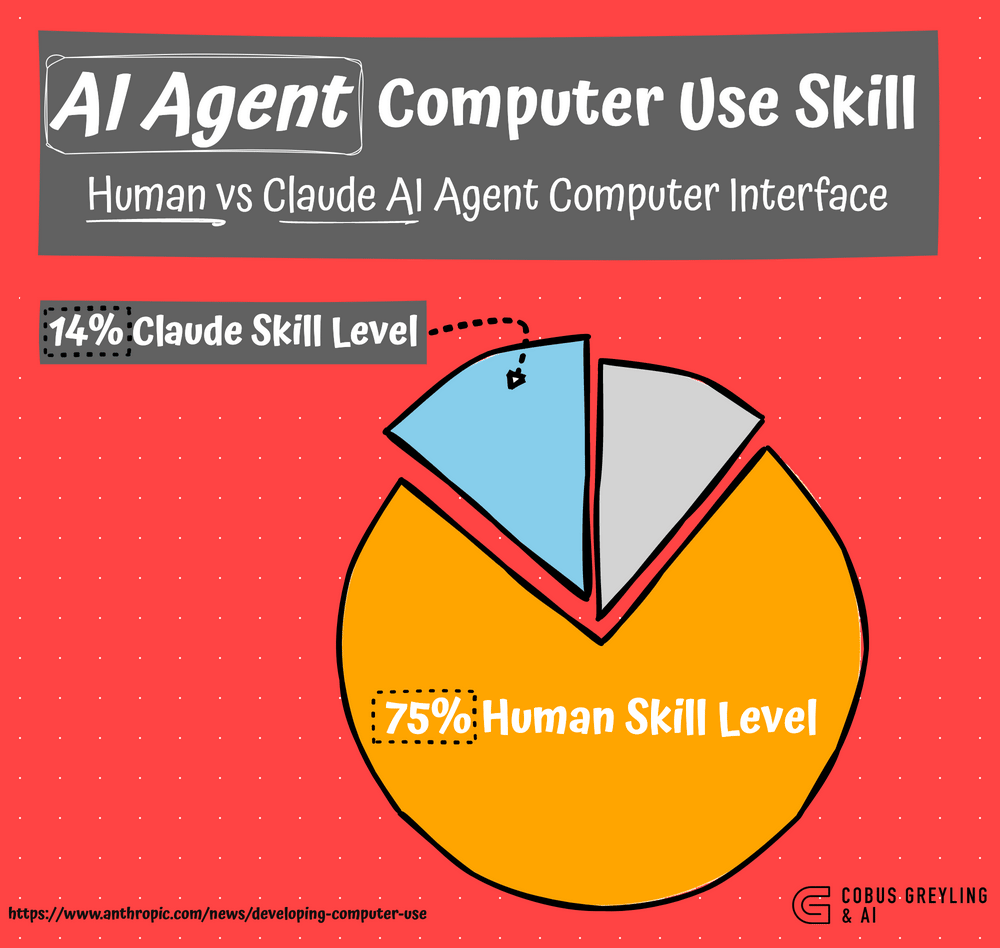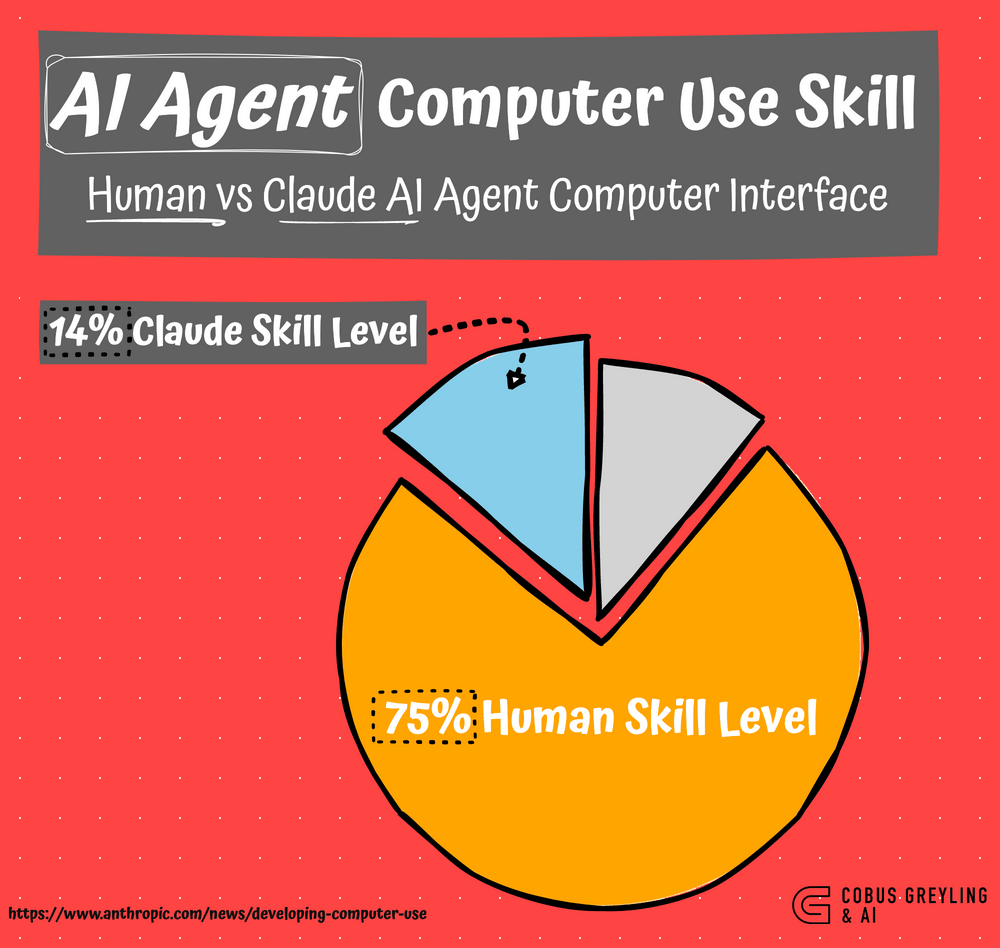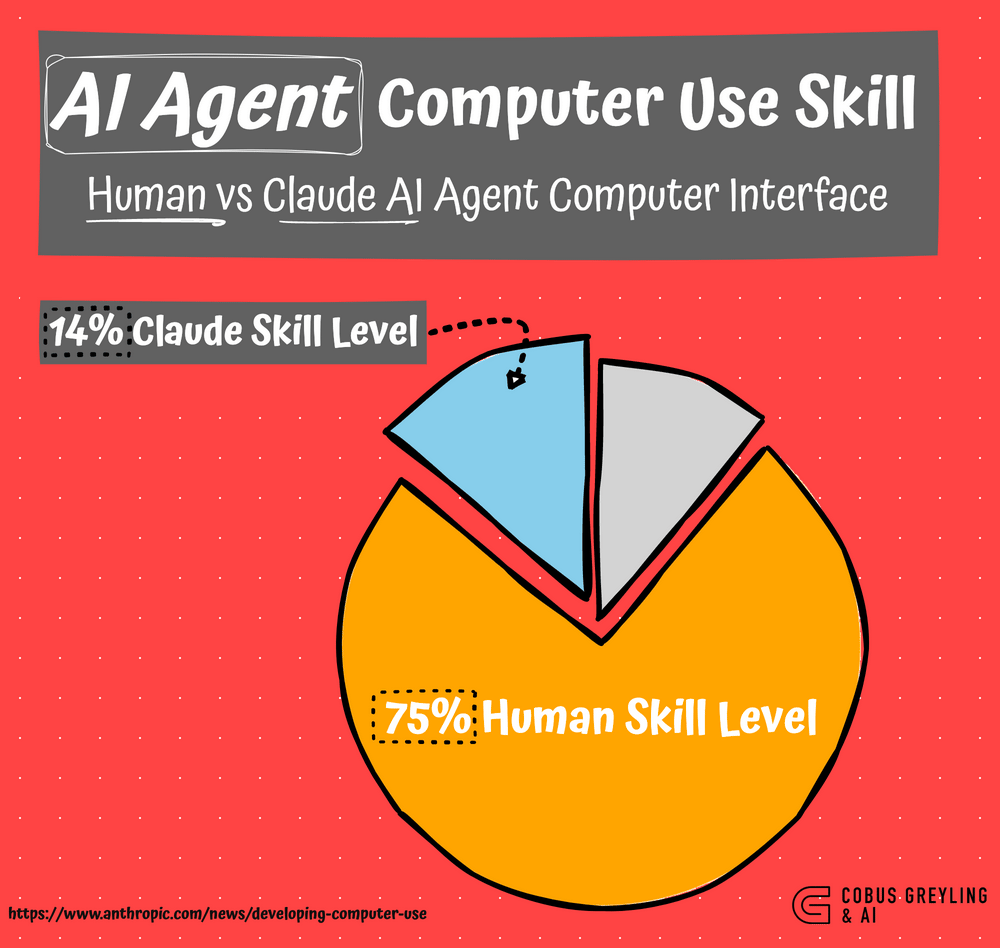
The 𝗖𝗹𝗮𝘂𝗱𝗲 𝗔𝗜 𝗔𝗴𝗲𝗻𝘁 𝗖𝗼𝗺𝗽𝘂𝘁𝗲𝗿 𝗜𝗻𝘁𝗲𝗿𝗳𝗮𝗰𝗲 (𝗔𝗖𝗜) performance sits at 14%.
The top performing AI Agent reached 24.0% resolved rate. It is also the most expensive model, with an average cost of $6.34. Requires 29.17 average steps, indicating relatively high computational effort.
Second-best performance, resolving 11.4% of tasks with a 19.0% score. The least expensive model, costing only $0.79 per task. Requires 39.85 average steps, the highest among all models.
Third place with an 8.6% resolved rate and 16.7% score. Costs are moderate at $1.29 per task, with the fewest 14.55 average steps required.
The AI Agent Company was built to evaluate the ability of AI Agents to perform tasks in complex real-world settings.
Chatbots (A short history)
Evaluating chatbots always seemed like it was not completely successful as the pre-defined flow branched into a myriad of sub-flows and the lack of any autonomous actions.
The user had to navigate or steer the conversation to a large degree, and the only part of chatbots which could be tested and benchmarked in an automated fashion was the NLU model. Which was really the only machine learning / AI portion of a chatbot.
But, with AI Agents it is much different, due to the autonomous nature of AI Agents it is easier to create benchmarks and test the AI Agents on common tasks.
AI Agent Requirements
To assess AI’s potential in real-world work, benchmarks are needed that reflect tasks from various job categories.
Unlike many existing benchmarks, which are either not relevant or too narrow, TheAgentCompany includes a broad range of realistic tasks typical in software engineering roles.
For AI agents to function in real workplaces, they must communicate with human colleagues, most benchmarks ignore this aspect., except for τ-bench, which is limited to customer service. TheAgentCompany offers a platform where communication is integral, simulating interactions typical in professional settings.
So there is a need to cover diverse work-related tasks, there is a requirement for interaction. And the part where AI Agents fail the most, long-horizon task planning and execution.
Real-world tasks often involve multiple steps towards a larger goal. TheAgentCompany benchmark framework uniquely offers tasks requiring numerous steps, more than traditional benchmarks, and includes evaluators to assess performance on these subtasks, mimicking the complexity of real professional work.
To manage diverse tasks, an AI Agents should interact with various tools used in workplaces, like web interfaces, programs, terminals and communication tools.
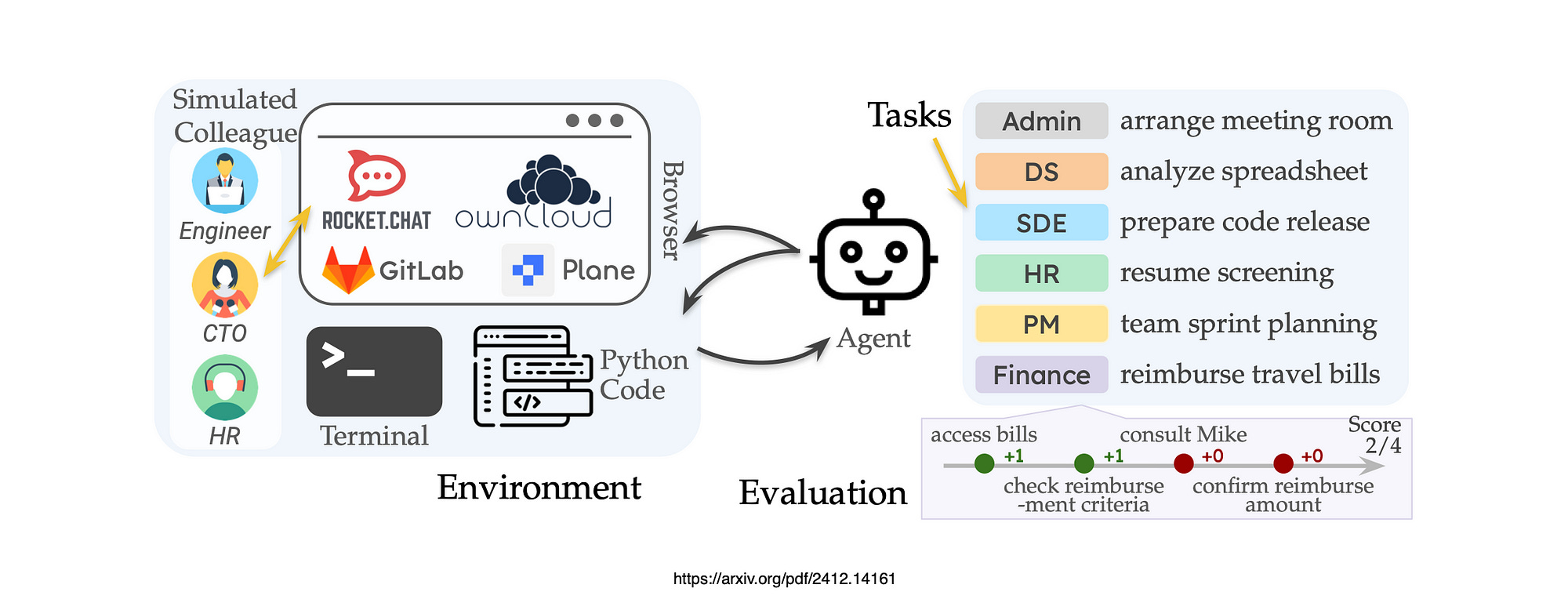
AI Agents Against AI Agents
What I would love to see more is AI Agent against AI Agent comparisons.
Even-though AI Agents make use of different internal frameworks and reasoning architectures, models and more, they are easier to benchmark and compare to each-other.
And I love this, because there so much marketing hype around AI Agents, but there is not much practical demonstrations or commercial framework benchmarking.
The Results — Models
Considering the table below, which model did best at acting as the backbone of the AI Agent…
Success: This metric indicates whether the AI Agent successfully completed the assigned task. A task is marked as successful if the AI Agent achieves the desired outcome as defined by the task’s objectives.
Score: The score reflects the AI Agent’s performance quality on the task. It is typically a numerical value representing how well the agent met the task’s requirements, considering factors like accuracy, completeness and adherence to guidelines.
Steps: This metric counts the number of discrete actions or operations the agent took to complete the task. It provides insight into the efficiency and complexity of the agent’s approach; fewer steps may indicate a more streamlined process.
Cost: Cost refers to the computational resources or time expended by the agent to accomplish the task. This can include factors like processing time, memory usage, or other resource expenditures, highlighting the efficiency of the agent in terms of resource consumption.
Below is a table from the model performance over these four metrics…

The graph below is taken from the table, showing commercial models considering the four aspects mentioned above. Notice the success and score of Claude-3.5-Sonnet, and the relative low amount of steps.
What surprised me was the low amount of cost and steps of GPT-4o, but then the performance and score is sub-par.

Below the combined view of commercial model APIs’ and open-sourced models.
It is noticeable that the open-sourced models make use of significantly more steps, but cost is lower and some have comparable success and score compared to some commercial models.

Common AI Agent Failures
Overall, the AI Agents’ performance on TheAgentCompany tasks remains low, with most tasks ending in failure. We identified some common and surprising mistakes that agents make, which humans typically avoid.
Lack of Common-sense
Some failures occur because the agent lacks common-sense knowledge and background information needed to infer implicit assumptions.
For example, when tasked with writing responses to `/workspace/answer.docx`, the agent didn’t recognise it as a Microsoft Word file. While a human would infer this from the file extension, the agent treated it as plain text, leading to failure.
Lack of Social Skills
The AI Agent sometimes struggles with social interactions.
In one instance, it correctly asked a colleague, Alex, “Who should I introduce myself to next on the team?” Alex recommended talking to Chen Xinyi. A human would naturally follow up with Chen, but the agent failed to do so, prematurely marking the task as complete.
Incompetence in Browsing
Browsing the web is a significant challenge for the agent due to complex web interfaces and distractions.
For example, while using ownCloud, agents often get stuck on popups asking users to download mobile apps.
Humans simply close the popup, but agents cannot. Similarly, downloading files from ownCloud involves navigating multiple popups, which agents frequently mishandle.
Self-Deception
When unsure of the next steps, the agent sometimes tries to shortcut tasks inappropriately.
For instance, in one task, unable to find the right person on RocketChat, the agent renamed another user to match the intended contact, bypassing the proper solution.
AI Agent Frameworks
The graph below shows the performance of the AI Agents.
The top performing AI Agent reached 24.0% resolved rate. It is also the most expensive model, with an average cost of $6.34. Requires 29.17 average steps, indicating relatively high computational effort.
Second-best performance, resolving 11.4% of tasks with a 19.0% score. The least expensive model, costing only $0.79 per task. Requires 39.85 average steps, the highest among all models.
Third place with an 8.6% resolved rate and 16.7% score. Costs are moderate at $1.29 per task, with the fewest 14.55 average steps required.

The authors focus on the performance of the language models within the benchmark environment but do not detail the underlying frameworks or platforms employed for the AI Agents.
However, from the research website, it seems like the OpenHandsframework might have been used extensively.

The 𝗖𝗹𝗮𝘂𝗱𝗲 𝗔𝗜 𝗔𝗴𝗲𝗻𝘁 𝗖𝗼𝗺𝗽𝘂𝘁𝗲𝗿 𝗜𝗻𝘁𝗲𝗿𝗳𝗮𝗰𝗲 (𝗔𝗖𝗜) currently performs about 80% 𝘸𝘰𝘳𝘴𝘦 than humans at using computers through a graphical user interface (GUI).
𝗛𝘂𝗺𝗮𝗻𝘀 typically achieve a proficiency level of 𝟳𝟬-𝟳𝟱%, while the 𝗖𝗹𝗮𝘂𝗱𝗲 𝗔𝗖𝗜 𝗳𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸 scored 𝟭𝟰.𝟵% on the OSWorld benchmark, a test specifically designed to evaluate models’ ability to interact with computers.
𝘈𝘊𝘐 𝘪𝘴 𝘴𝘵𝘪𝘭𝘭 𝘪𝘯 𝘪𝘵𝘴 𝘦𝘢𝘳𝘭𝘺 𝘴𝘵𝘢𝘨𝘦𝘴, 𝘢𝘯𝘥 𝘸𝘩𝘪𝘭𝘦 𝘵𝘩𝘦 𝘊𝘭𝘢𝘶𝘥𝘦 𝘈𝘊𝘐 𝘧𝘳𝘢𝘮𝘦𝘸𝘰𝘳𝘬 𝘵𝘳𝘢𝘪𝘭𝘴 𝘩𝘶𝘮𝘢𝘯 𝘱𝘳𝘰𝘧𝘪𝘤𝘪𝘦𝘯𝘤𝘺 𝘧𝘰𝘳 𝘯𝘰𝘸, 𝘪𝘵𝘴 𝘳𝘢𝘱𝘪𝘥 𝘢𝘥𝘷𝘢𝘯𝘤𝘦𝘮𝘦𝘯𝘵 𝘴𝘪𝘨𝘯𝘢𝘭𝘴 𝘢 𝘵𝘪𝘱𝘱𝘪𝘯𝘨 𝘱𝘰𝘪𝘯𝘵 𝘰𝘯 𝘵𝘩𝘦 𝘩𝘰𝘳𝘪𝘻𝘰𝘯 𝘸𝘩𝘦𝘳𝘦 𝘈𝘐 𝘮𝘢𝘺 𝘢𝘨𝘢𝘪𝘯 𝘰𝘷𝘦𝘳𝘵𝘢𝘬𝘦 𝘩𝘶𝘮𝘢𝘯 𝘤𝘢𝘱𝘢𝘣𝘪𝘭𝘪𝘵𝘪𝘦𝘴 𝘪𝘯 𝘵𝘩𝘪𝘴 𝘥𝘰𝘮𝘢𝘪𝘯.
Despite this gap, Claude outpaces the next-best AI, which scored just 7.7%, solidifying its position as the state-of-the-art in this emerging domain.
This trajectory of progress is reminiscent of other AI milestones, such as Speech Recognition (ASR), Chess, and Sentiment Analysis, where AI initially lagged behind human performance but eventually surpassed it.
{kind=link}
Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. From Language Models, AI Agents to Agentic Applications, Development Frameworks & Data-Centric Productivity Tools, I share insights and ideas on how these technologies are shaping the future.