

The Cycle of Scaling LLM-Supporting Frameworks
Ever-since we began leveraging Large Language Models (LLMs), a recurring pattern has emerged…

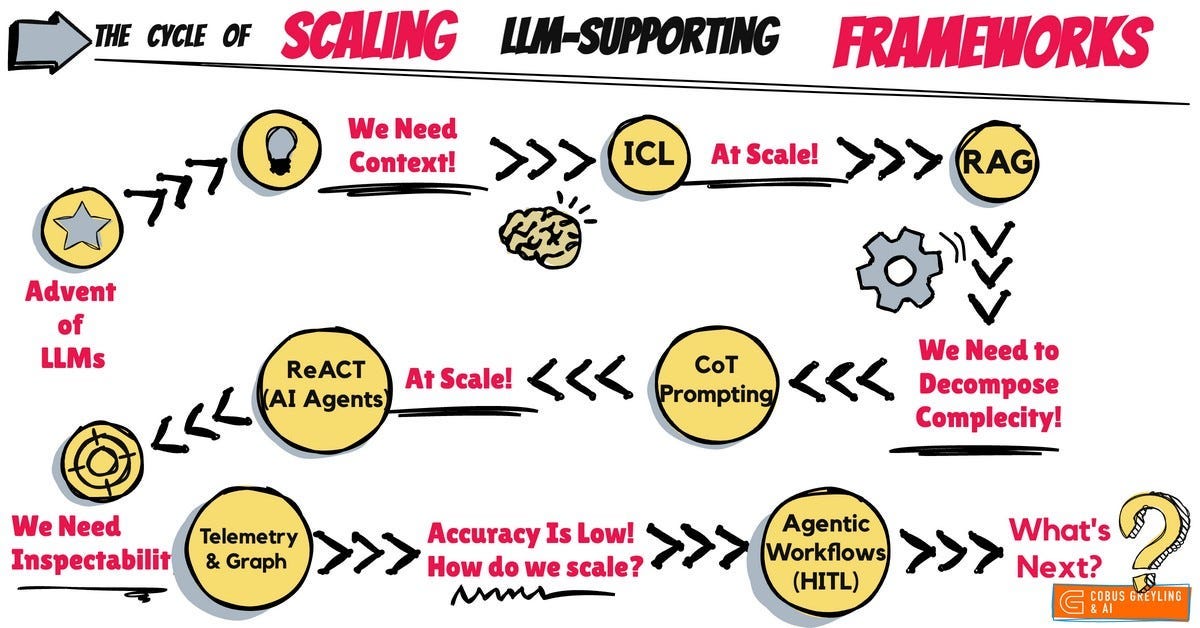
Ever-since we began leveraging Large Language Models (LLMs), a recurring pattern has emerged:
As LLMs are implemented, a limitation is identified, followed by the development of a solution — only to face the challenge of scaling that solution effectively.
For example, LLMs initially struggled to utilise the knowledge they were trained on, leading to the introduction of In-Context Learning through prompt engineering.
However, this approach proved difficult to scale, prompting the creation of Retrieval-Augmented Generation (RAG) frameworks to enhance performance at a larger scale.
As users began providing more complex and compound inputs, it became clear that Chain-of-Thought prompting improved accuracy when handling intricate tasks.
Yet, scaling this method beyond manual prompt adjustments posed a challenge, which led to the development of ReACT frameworks — the first AI agents capable of reasoning and acting autonomously.
However, inspectability emerged as a new hurdle, reviving interest in graph-based approaches to monitor and understand AI Agent flows.
Despite these advances, accuracy remained a persistent issue, driving a resurgence in Agentic Workflows, which integrate human oversight to refine outcomes.
So, here’s the question: what groundbreaking innovation lies ahead in this cycle of discovery, solution, and scaling?
- Let’s connect on LinkedIn, and stay in touch on X!
Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. From Language Models, AI Agents to Agentic Applications, Development Frameworks & Data-Centric Productivity Tools, I share insights and ideas on how these technologies are shaping the future.