The Evolution Of Prompt Engineering
As functionality grows, invariably the complexity of prompt engineering will grow. Here I explain how complexity can be introduce to the process of prompt engineering.

Static Prompts
Today experimenting with prompts and prompt engineering is commonplace. Through the process of creating and running prompts, users can experiment with the generative capabilities of LLMs.
Text Generation Is A Meta Capability Of Large Language Models & Prompt Engineering Is Key To Unlocking It.
One of the first principles gleaned when experimenting with Prompt Engineering is that a generative model cannot be explicitly requested to do something.
Rather, users need to understand what they want to achieve and mimic the initiation of that vision. The process of mimicking is referred to as prompt design, prompt engineering or casting.
Prompt Engineering is the way in which instruction and reference data is presented to the LLM.
Introducing a set structure to the prompt yields more accurate responses from the LLM. For instance as seen below, prompts can be contextually engineered to create a contextual reference for the LLM.

Contextually engineered prompts typically consist of three sections, instruction, context and question.
Here is a practical example of a contextual prompt:
prompt = """Answer the question as truthfully as possible using the provided text, and if the answer is not contained within the text below, say "I don't know"
Context:
The men's high jump event at the 2020 Summer Olympics took place between 30 July and 1 August 2021 at the Olympic Stadium.
33 athletes from 24 nations competed; the total possible number depended on how many nations would use universality places
to enter athletes in addition to the 32 qualifying through mark or ranking (no universality places were used in 2021).
Italian athlete Gianmarco Tamberi along with Qatari athlete Mutaz Essa Barshim emerged as joint winners of the event following
a tie between both of them as they cleared 2.37m. Both Tamberi and Barshim agreed to share the gold medal in a rare instance
where the athletes of different nations had agreed to share the same medal in the history of Olympics.
Barshim in particular was heard to ask a competition official "Can we have two golds?" in response to being offered a
'jump off'. Maksim Nedasekau of Belarus took bronze. The medals were the first ever in the men's high jump for Italy and
Belarus, the first gold in the men's high jump for Italy and Qatar, and the third consecutive medal in the men's high jump
for Qatar (all by Barshim). Barshim became only the second man to earn three medals in high jump, joining Patrik Sjöberg
of Sweden (1984 to 1992).
Q: Who won the 2020 Summer Olympics men's high jump?
A:"""
openai.Completion.create(
prompt=prompt,
temperature=0,
max_tokens=300,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
model=COMPLETIONS_MODEL
)["choices"][0]["text"].strip(" \n")At this stage, prompts are static in nature, and does not form part of a larger application.
Prompt Templating
The next step from static prompts is prompt templating.
A static prompt is converted into a template with key values being replaced with placeholders. The placeholders are replaced with application values/variables at runtime.
Some refer to templating as entity injection or prompt injection.
In the template example below from DUST you can see the placeholders of ${EXAMPlES:question}, ${EXAMPlES:answer} and ${QUESTIONS:question} and these placeholders are replaced with values at runtime.

Prompt templating allows for prompts to the stored, re-used, shared, and programmed. And generative prompts can be incorporated in programs for programming, storage and re-use.
Templates are text files with placeholders where variables and expressions can be inserted at run-time.
Prompt Pipelines
In the case of prompt pipelines, a pre-defined prompt template is populated with questions or requests from a user. The context or reference included in the prompt to instruct the LLM is data retrieved from a knowledge store.
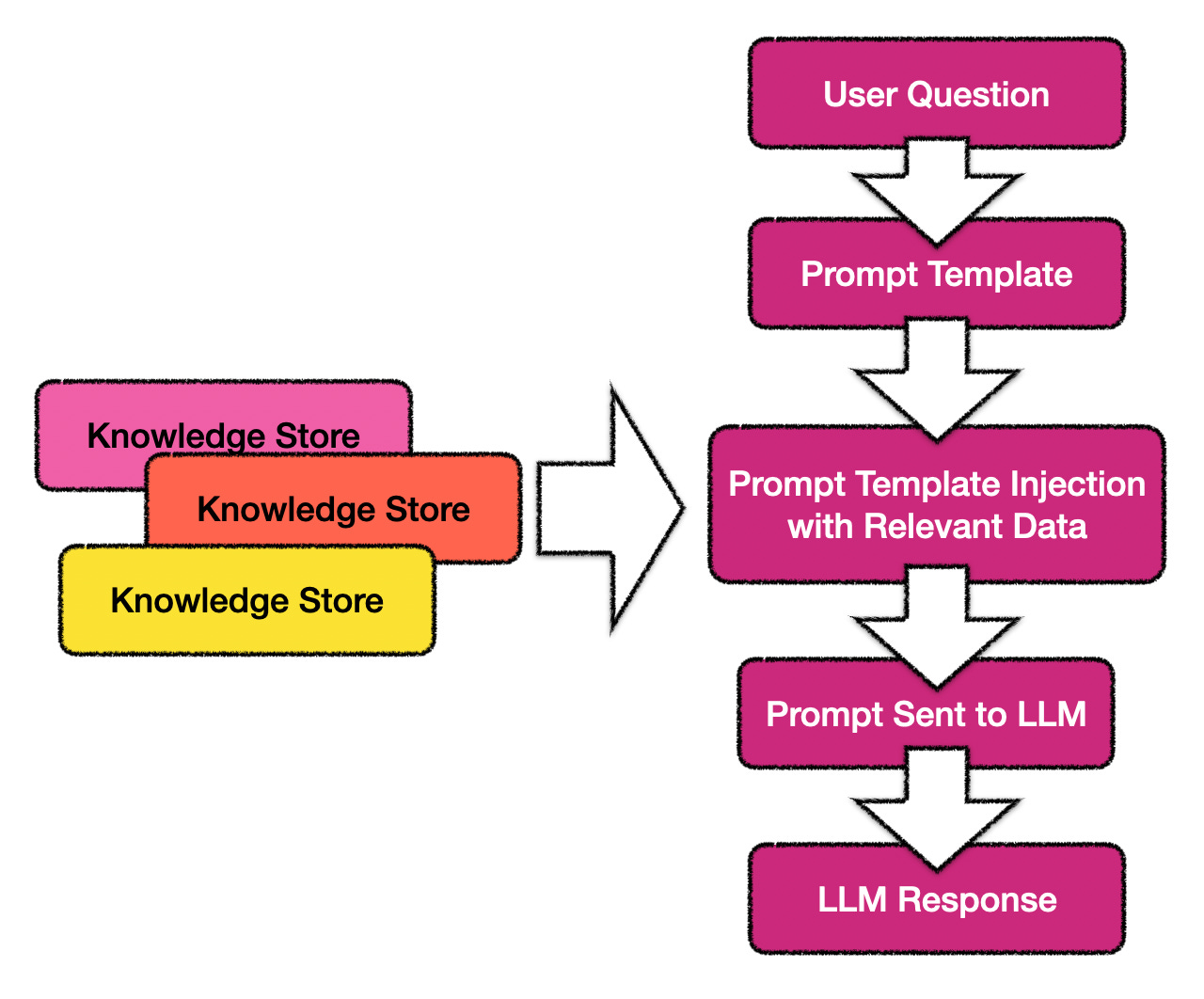
Prompt Pipelines can also be described as an intelligent extension to prompt templates.
Hence the variables or placeholders in the pre-defined prompt template are populated (also known as prompt injection) with the question from the user, and the knowledge to be searched from the knowledge store.
The data from the knowledge store acts as a contextual reference for the question to be answered. Having this body of information available prevents LLM hallucination. The process is also helpful in preventing LLM to use dated or old data from the model which is inaccurate at the time.
Subsequently the composed prompt is sent to the LLM and the LLM response returned to the user.
Below is an example of a prompt template prior to the document and the question data being injected.

Prompt Chaining
Prompt chaining is the process of chaining or sequencing a number of prompts to form a larger application. The prompt sequences can be arranged in series or parallel.
When prompts are sequenced in series, a prompt (aka node) in the chain is often dependant on the output from the previous node in the chain. In some instances data processing and decision making cases are implemented between prompts/nodes.
LLMs are highly versatile with open-ended capabilities.
There are also instances where processes need to run in parallel, for instance, a user request can be kicked off in parallel while the user is having a conversation with the chatbot.
Prompt Chaining will primarily consist of a conversational UI for input. The output will mostly also be unstructured conversational output. Hence creating a digital assistant or chatbot. Prompt chaining can also be used in RPA scenarios where processes and pipelines are kicked-off and the user is notified regarding the result.
When chaining Large Language Model prompts through a Visual Programming UI, the largest part of the functionality will be the GUI which facilitates the authoring process.
Below is an image of what such a GUI for prompt engineering, and prompt chain authoring might look like. This design originated from research performed by the University of Washington and Google.

Read more about prompt chaining here.
In Conclusion
The term “last mile” has often been used in the context of production implementations of Generative AI and Large Language Models (LLMs). Ensuring that the AI implementation does indeed solve enterprise issues and achieve measurable business value.
Production implementations need to face the rigours and scrutiny of customers and also the demands of continuous scaling, updates and improvements.
Production implementations of LLMs demand:
Curated and structured data for fine tuning LLMs
A supervised approach to Generative AI
A scaleable and manageable ecosystem for LLM based applications

⭐️ Please follow me on LinkedIn for updates on Conversational AI ⭐️

I’m currently the Chief Evangelist @ HumanFirst. I explore and write about all things at the intersection of AI and language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces and more.
