

The Multi-AI Agent Gap
This study calls for simplicity when it comes to AI Agents; for now…

For starters, the study contains two very good definitions for AI Agents and for Multi-AI Agent systems.
AI Agent & MAS Definitions
An LLM-based AI Agent is defined as an artificial entity with prompt specifications (initial state), conversation trace (state), and ability to interact with the environments such as tool usage (action).
A multi-agent system (MAS) is then defined as a collection of AI Agents designed to interact through orchestration, enabling collective intelligence.
MASs are structured to coordinate efforts, enabling task decomposition, performance parallelisation, context isolation, etc.
AI Agent Accuracy In General
There has been various studies and research on the accuracy of AI Agents, which showed that the accuracy of AI Agents at this stage is surprisingly low.
Included in these studies are THEAGENTCOMPANY, AI Agents that Matterand also research from OpenAI when they launched Operator.
This does not mean that AI Agents do not have a future, it just shows that there is still much work to be done before AI Agents reaches a stage where they are on par with human capabilities.
- Find me on LinkedIn or on X! 🙂
Back To The Study
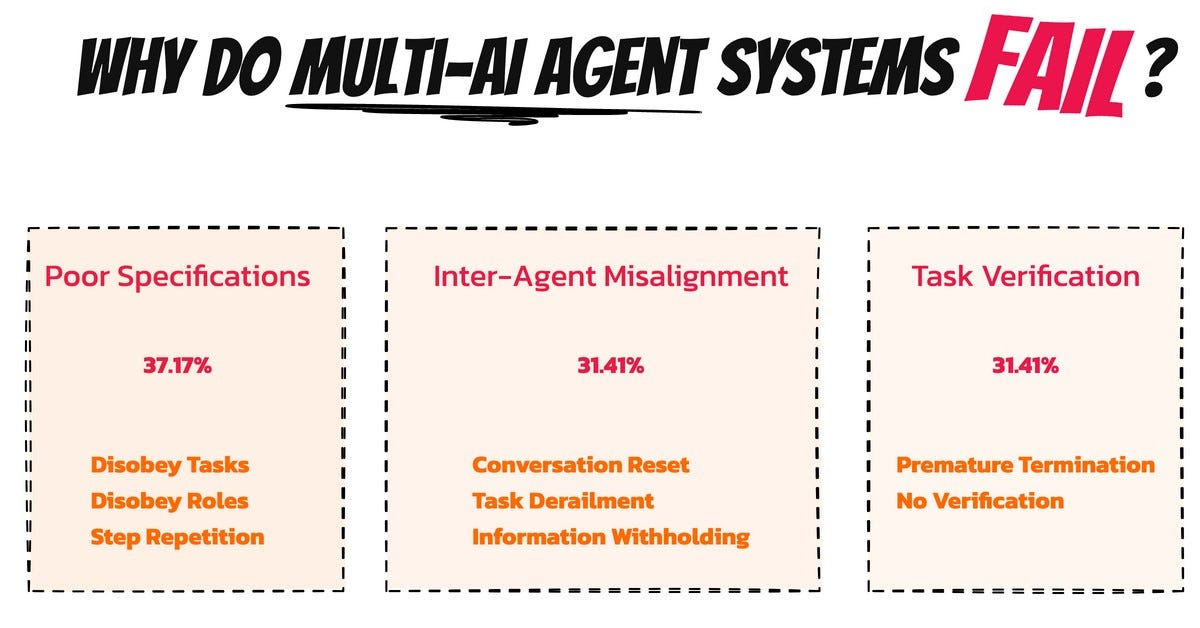
What’s behind the failure of Multi-Agent LLM Systems?

Researchers from UC Berkeley and collaborators examined 151 task runs across 5 frameworks, revealing failure rates exceeding 75% in some cases.
Key reasons for these breakdowns:
Poor system specification (37.2%): Unclear agent roles and task breakdowns derail collaboration.
Inter-agent misalignment (31.4%): Lack of coordination leads to conflicting or redundant actions.
Weak task verification (31.4%): Inadequate checks allow errors to slip through unnoticed.
Solutions to boost success, in short are:
— Define precise roles and clear task termination criteria.
— Deploy verification AI Agents with targeted quality tests.
— Implement standardised protocols for agent communication.
— Enhance memory and state tracking across agents.
— Enable agents to signal uncertainty for better decision-making.
Interesting Findings
Multi-agent systems (MAS) are becoming more popular, but they don’t improve accuracy or performance much compared to single-agent setups or simple methods like best-of-N sampling on common benchmarks.
The study holds empirical analysis that the correctness of the state-of-the-art (SOTA) open-source MASs can be as low as 25%.
Good MAS design requires organisational understanding — even organisations of sophisticated individuals can fail catastrophically if the organisation structure is flawed.
Several works highlight the challenges of building robust agentic systems and suggest new strategies, typically for single-agent designs, to improve reliability.
For instance, a recent Anthropic’s blog post draws the importance of modular components, such as prompt chaining and routing, rather than adopting overly complex frameworks.
Similarly, other studies show that complexity can hinder real-world adoption for agentic systems.
The study warns against the introduction of unnecessary complexity where it is not needed to perform a task.
Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. From Language Models, AI Agents to Agentic Applications, Development Frameworks & Data-Centric Productivity Tools, I share insights and ideas on how these technologies are shaping the future.