Time-Aware Adaptive RAG (TA-ARE)
Standard RAG always retrieves regardless of the input question, while adaptive retrieval only retrieves when necessary…


Introduction
With the advent of Large Language Models (LLMs) there was the concept of emergent capabilities. The premise or assumption was that LLMs have hidden and unknown capabilities which are just waiting to be discovered. And entrepreneurs were eager to discover some competitive advantage in LLMs no-one knew about.
Emergent capabilities turned out to be a mirage. But the special ability of LLMs which was discovered was In-Context Learning (ICL). LLMs have the ability, when supplied with contextual data at inference, to reference the contextual data in generating their response. Hence, on instruction via the prompt, the LLM will discard model training data, and utilise the inference-data.
Time-Aware Adaptive REtrieval (TA-ARE) is a simple yet effective method that helps LLMs assess the necessity of retrieval without calibration or additional training.
Retrieval Augmented Generation (RAG)
Delivering contextual data to LLMs at inference became known as RAG. The notion that LLM response generation is supplemented or augmented with supplementary data retrieved at inference.
Standard RAG always retrieves regardless of the input question, while adaptive retrieval only retrieves when necessary.
Time-Aware Adaptive RAG (TA-ARE)
Study Findings
The study mentions that RAG generally improves the performance of question answering. This has been confirmed over and over again and is now seen as a given.
Time awareness, the study identified that many queries are time related and users ask questions while specifying the time-frame as a function to defined their question.
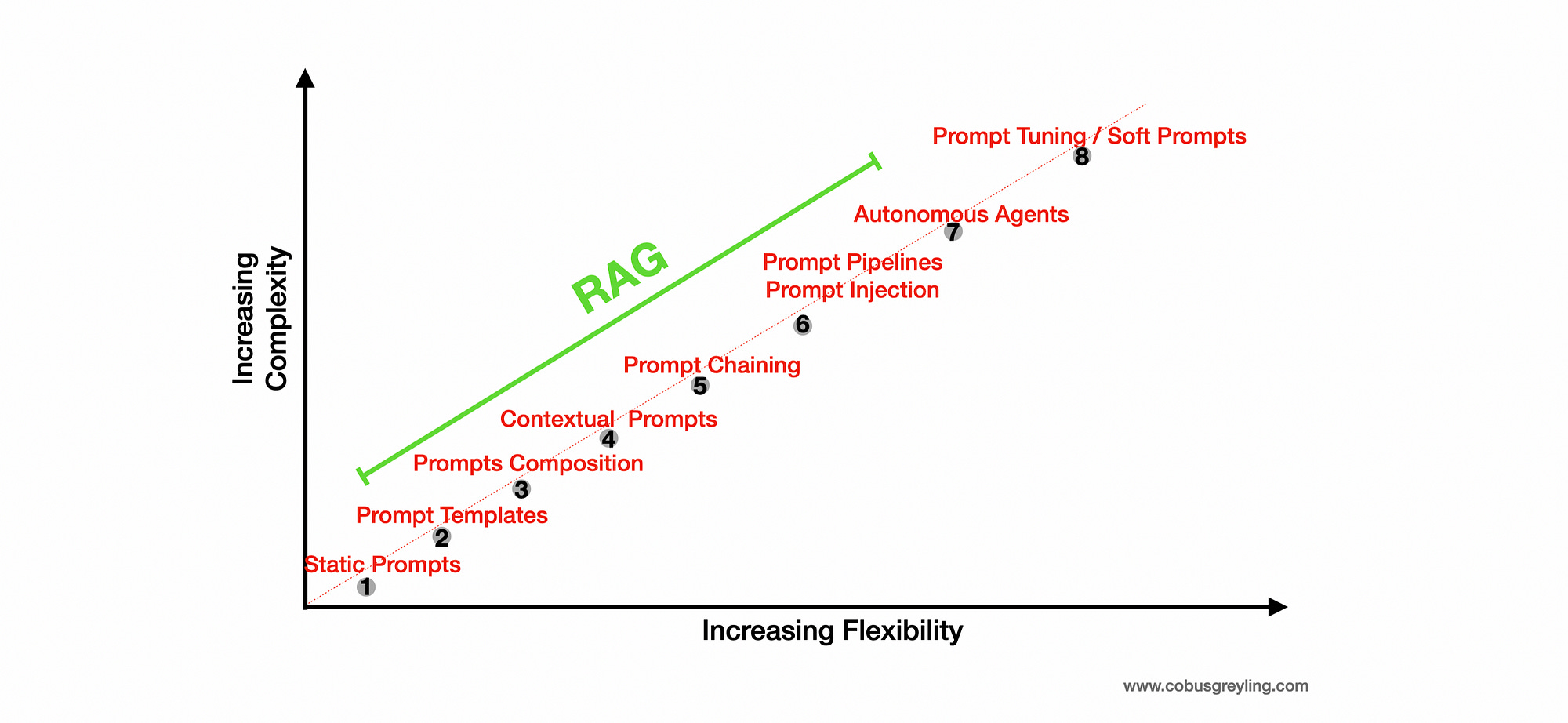
The effectiveness of vanilla prompting varies and does not scale with model sizes. Considering the image below, in order for prompts to scale well, complexity needs to be introduced; from step 1 up to step 8.
Even though LLMs can be described as Knowledge Intensive, LLMs do struggle with knowledge intensive user tasks; for two reasons.
LLMs generally lack and hold no knowledge of what can be termed new world knowledge.
Long-Tail Knowledge is harder to address; this problem is akin to the long tail of intent distribution.
TA-ARE
Standard RAG methods conduct retrieval indiscriminately, and do not perform triage on input queries. This blanket approach can lead to suboptimal task performance.
Inference cost can also be exacerbated by this.
The concept of adaptive RAG dynamically determines retrieval necessity and relies only on LLMs’ parametric knowledge when deemed unnecessary.
ARAG approaches can be categorised into calibration-based and model-based judgement. The problem is that tuning is required for thresholds for different datasets and models to balance task performance and inference overheads.
TA-ARE investigates to what extent LLMs can perform calibration-free adaptive retrieval via prompting.
To answer this question, evaluations is required whether LLMs retrieve only when necessary.
This requests a benchmark that distinguishes between questions that can be answered using LLMs’ parametric knowledge and those that require external information through retrieval.
Study Contribution
A new dataset RetrievalQA is created to assess Adaptive RAG (ARAG) for short-form open-domain QA.
Benchmarking existing methods finding that vanilla prompting is insufficient in guiding LLMs to make reliable retrieval decisions.
TA-ARE is conceptualised, a simple and effective method to help LLMs assess the necessity of retrieval without calibration or additional training.
Conclusion
Something which is evident is that complexity needs to be introduced in order for frameworks to scale.
Adaptive RAG where user input is triaged prior to assigning a process requires the calibration of a threshold of sorts.
The promise of Time-Aware Adaptive REtrieval (TA-ARE) is that it is a simple yet effective method that helps LLMs assess the necessity of retrieval without calibration or additional training.
The study states that the code will be available soon at https://github.com/hyintell/RetrievalQA.
I’m very much intrigued as to how TA-ARE is achieving the description in the study.

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.
