TinyStories Is A Synthetic DataSet Created With GPT-4 & Used To Train Phi-3
The Small Language Model from Microsoft, called Phi-3, was trained using a novel dataset called TinyStories.


TLDR
Microsoft used the following recipe to create synthetic training data for the Phi-3 language model:
Microsoft researchers created a discrete dataset based on 3,000 words, comprising of roughly equal numbers of nouns, verbs, and adjectives.
They then instructed an LLM to create children’s stories using one noun, one verb, and one adjective from the list.
This prompt repeated millions of times over several days, generating millions of tiny children’s stories.
The TinyStories dataset was created to combine all the qualitative elements of natural language, such as grammar, vocabulary, facts, and reasoning.
The main challenge in using large language models for producing training data is generating a dataset that is sufficiently diverse.
This method also forces the LLM to not be too repetitive in the content generated.
Summary
The Small Language Model (SLM) Phi-3 was trained on synthetic data generated by GPT-3.5 and GPT-4. Training data created by large language models can often be too repetitive and lack diversity in verbs, nouns, and adjectives.
The dataset needed to include all the qualitative elements of natural language, such as grammar, vocabulary, facts, and reasoning, but it was designed to be smaller, less diverse, and more restricted in content.
The concept of creating a framework or data topology for the LLM to generate synthetic training data is intriguing.
The study indicates that training generative models on TinyStories can typically be completed in less than a day on a single GPU, while still exhibiting behaviours similar to those observed in larger models.
Creating TinyStories
Instead of relying solely on raw web data, the creators of Phi-3 sought high-quality data. Microsoft researchers created a discrete dataset based on 3,000 words, comprising roughly equal numbers of nouns, verbs, and adjectives.
They then instructed a large language model to create children’s stories using one noun, one verb, and one adjective from the list — a prompt repeated millions of times over several days, generating millions of tiny children’s stories.
Small language models are designed to excel at simpler tasks, making them more accessible and easier to use for organisations with limited resources. They can also be fine-tuned more easily to meet specific needs.

Data Design Elements
The TinyStories dataset was created to combine all the qualitative elements of natural language, such as grammar, vocabulary, facts, and reasoning. However, it is designed to be smaller, less diverse, and more restricted in content.

Diverse Data
To achieve this, researchers relied on the latest text generation models by OpenAI (GPT-3.5 and GPT-4) to produce large amounts of synthetic content according to specific instructions.
They instructed the models to generate content using vocabulary that a typical 3-year-old child would understand, and restricted the content to the format of short stories in English.
The main challenge in using large language models for producing training data is generating a dataset that is sufficiently diverse.
Prompting these models to produce stories, even with a high generation temperature, often results in a repetitive dataset that lacks the diversity needed to train a language model with an understanding of language comparable to that of children.
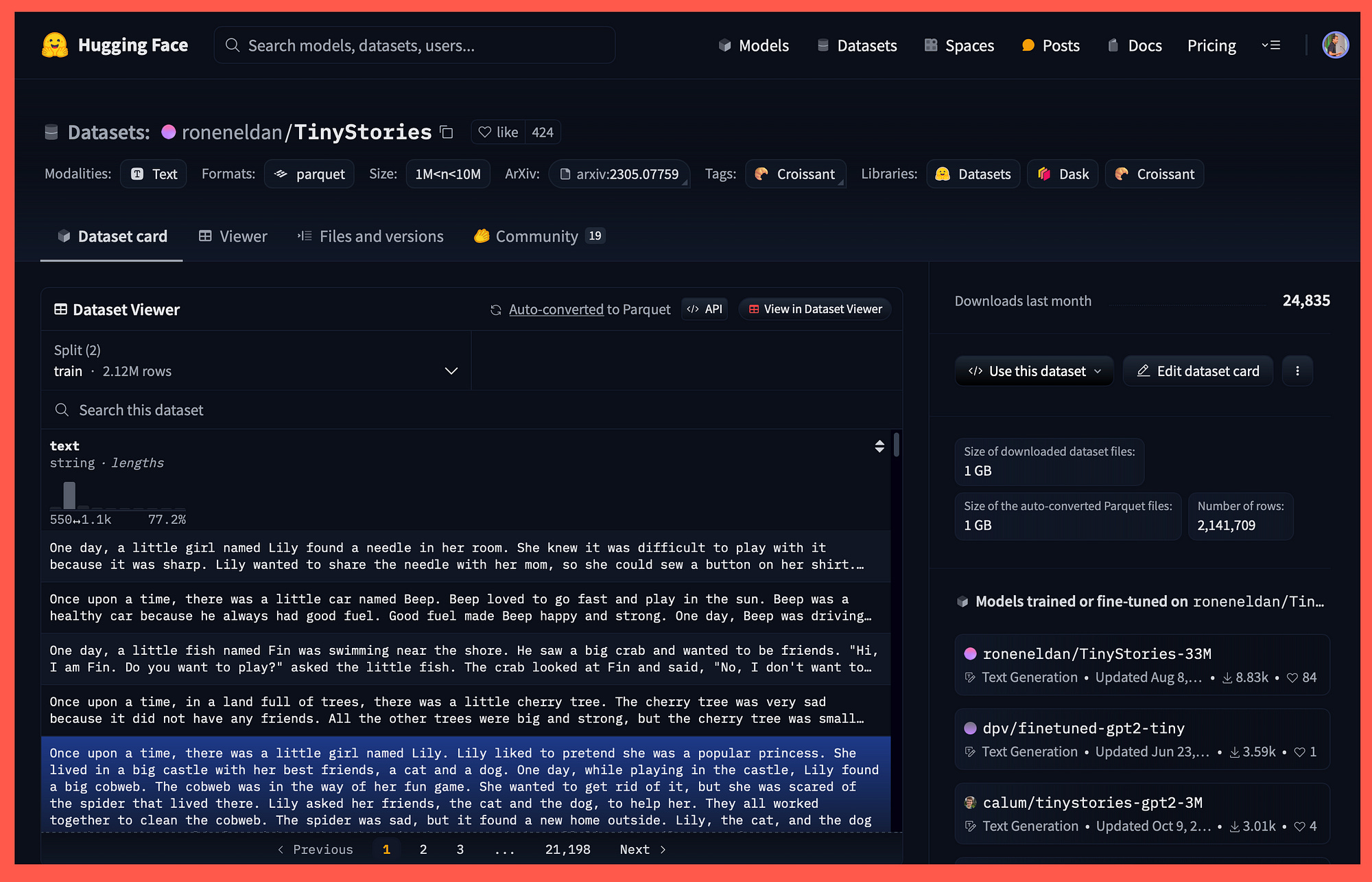
The TinyStories Dataset on HuggingFace
When prompted to create its own stories, the small language model trained on TinyStories generated fluent narratives with perfect grammar.
In Conclusion
TinyStories aims to facilitate the development, analysis, and research of language models, especially for low-resource or specialised domains, and to shed light on the emergence of language capabilities in these models.
A general question arising from this work is whether synthesising a refined dataset can be beneficial for training networks for practical uses. For example, it might be possible to train a customer service chatbot by synthesising a large dataset of hypothetical calls.
I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.