Training a Language Model With AI Agents
Phi-4 Language Model open-sourced by Microsoft - Synthetic data, AI Agents, Synthetic Generation Prompts and Hallucination Refusal.

In Short
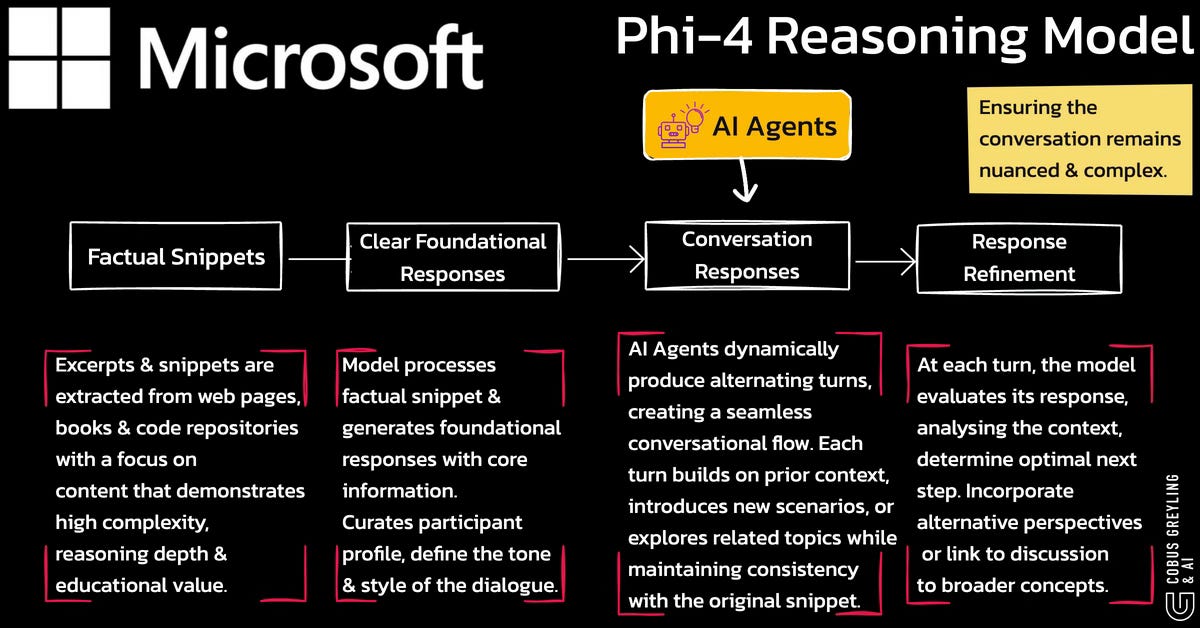
In training Phi-4, a synthetic data pipeline was used to transform factual snippets into engaging, multi-turn conversations that flow naturally and promote deep reasoning.
Initial Response
The model processes a factual snippet and generates a clear, foundational response that conveys the core information. Optionally, it curates a participant profile to define the tone and style of the dialogue.
Conversation Development
AI Agents dynamically produce alternating turns, creating a seamless conversational flow.
Each turn builds on prior context, introduces new scenarios, or explores related topics while maintaining consistency with the original snippet.
Response Refinement
After each turn, the model evaluates its response, analysing the context to determine the optimal next step.
It may incorporate alternative perspectives or link the discussion to broader concepts, ensuring the conversation remains nuanced and complex.
This iterative process ensures a smooth, contextually accurate flow of data, generating intellectually rich dialogues from simple factual inputs.
Introduction
The Phi-4 language model, a 14-billion parameter model, demonstrates a remarkable ability to avoid hallucination — generating false or ungrounded information.
Unlike many language models that may produce plausible but incorrect responses when faced with ambiguous or incomplete queries, Phi-4 is designed to prioritise factual accuracy.
This is achieved through a training process that
emphasises high-quality data &
robust post-training techniques.
By integrating synthetic data tailored to reinforce truthfulness, Phi-4 can identify when it lacks sufficient information and opts for conservative responses or refusals rather than fabricating answers.
This makes it particularly reliable for STEM-focused question-answering, where precision is critical.
The model’s refusal mechanism doesn’t compromise its utility but enhances trust, ensuring users receive responses grounded in its training data rather than speculative outputs.
This focus on avoiding hallucination sets Phi-4 apart from its predecessors and competitors, making it a dependable tool for applications requiring high accuracy.

- Also follow me on LinkedIn or on X! 🙂
Synthetic Generation Prompts
This approach allows Phi-4 to surpass its teacher model, GPT-4
Phi-4’s development leverages synthetic generation prompts to enhance its training process, a key innovation highlighted in the study.
Prompts are carefully designed instructions used to create high-quality synthetic data, which forms a significant part of Phi-4’s training corpus.
Unlike traditional models that rely heavily on organic data from the web or code, Phi-4 uses prompts to generate targeted, domain-specific data, particularly for STEM tasks.
The prompts guide the creation of diverse scenarios, questions & problem sets, ensuring the model is exposed to complex reasoning challenges during training.
This approach allows Phi-4 to surpass its teacher model, GPT-4, in STEM-focused capabilities without major architectural changes.
By controlling the quality and structure of the prompts, the developers ensure the synthetic data aligns with real-world applications, improving the model’s reasoning and problem-solving skills.
This strategic use of synthetic generation prompts is a cornerstone of Phi-4’s ability to deliver precise and contextually relevant responses.
Synthetic Data
Synthetic data is central to Phi-4’s training recipe, distinguishing it from other language models that predominantly use organic datasets.
The study emphasises that Phi-4, with its 14-billion parameters, incorporates synthetic data throughout its pre-training and post-training phases to boost performance.
This data is generated using carefully crafted prompts to simulate high-quality, diverse, and task-specific content, particularly in STEM domains.
By blending synthetic data with organic sources, Phi-4 achieves a balanced training corpus that enhances its reasoning abilities and reduces reliance on potentially noisy web data.
AI Agents
Phi-4’s development includes the use of AI Agents, which are specialised systems or processes that enhance its training and performance, as outlined in the study.
AI Agents play a crucial role in generating and curating synthetic data, ensuring it meets the high-quality standards required for Phi-4’s training.
Unlike traditional models, Phi-4 employ AI Agents to simulate interactive scenarios, solve complex problems and validate data integrity during the training process.
The AI Agent-driven approach allowed Phi-4 to refine its reasoning capabilities, particularly for STEM-focused tasks, by exposing it to dynamic and challenging datasets.
The AI Agents also contribute to post-training innovations, such as fine-tuning the model’s refusal mechanisms to prevent hallucination.
By integrating AI Agents, Phi-4 achieves strong performance relative to its size, surpassing its teacher model, GPT-4, in key benchmarks.
This strategic use of agents highlights Phi-4’s advanced training framework, making it a versatile and reliable model for applications requiring sophisticated reasoning and accuracy.
Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. From Language Models, AI Agents to Agentic Applications, Development Frameworks & Data-Centric Productivity Tools, I share insights and ideas on how these technologies are shaping the future.

COBUS GREYLING
Where AI Meets Language | Language Models, AI Agents, Agentic Applications, Development Frameworks & Data-Centric…www.cobusgreyling.com
Phi-4 Technical Report
We present phi-4, a 14-billion parameter language model developed with a training recipe that is centrally focused on…arxiv.org
Introducing Phi-4: Microsoft's Newest Small Language Model Specializing in Complex Reasoning |…
Today we are introducing Phi-4, our 14B parameter state-of-the-art small language model (SLM) that excels at complex…techcommunity.microsoft.com