Validating Low-Confidence LLM Generation
This is an approach that actively detects and mitigates hallucinations during the generation process.

Introduction
The basic approach has a hallucination detection phase and a mitigation phase.
While the mitigation phase is more familiar, the detection phase is novel to some extent.
The study identifies that hallucination can be remedied via retrieved knowledge (no surprises there).
This proposed architecture detects hallucination in real-time by making use of a certainty model.
Uncertainty is detected via entity extraction, keyword extraction and instructing model.
Inference cost is a concern following this methodology; together with inference latency.
While reading the study, the thought did come to mind, why not default on a RAG approach, and run the certainty model in parallel in an incremental fashion.
Running the certainty model in parallel can lend inspectability and observability in terms of hallucination.
The certainty model can also be run on an ad-hoc basis to optimise on resources and cost; but still perform a level of due diligence.
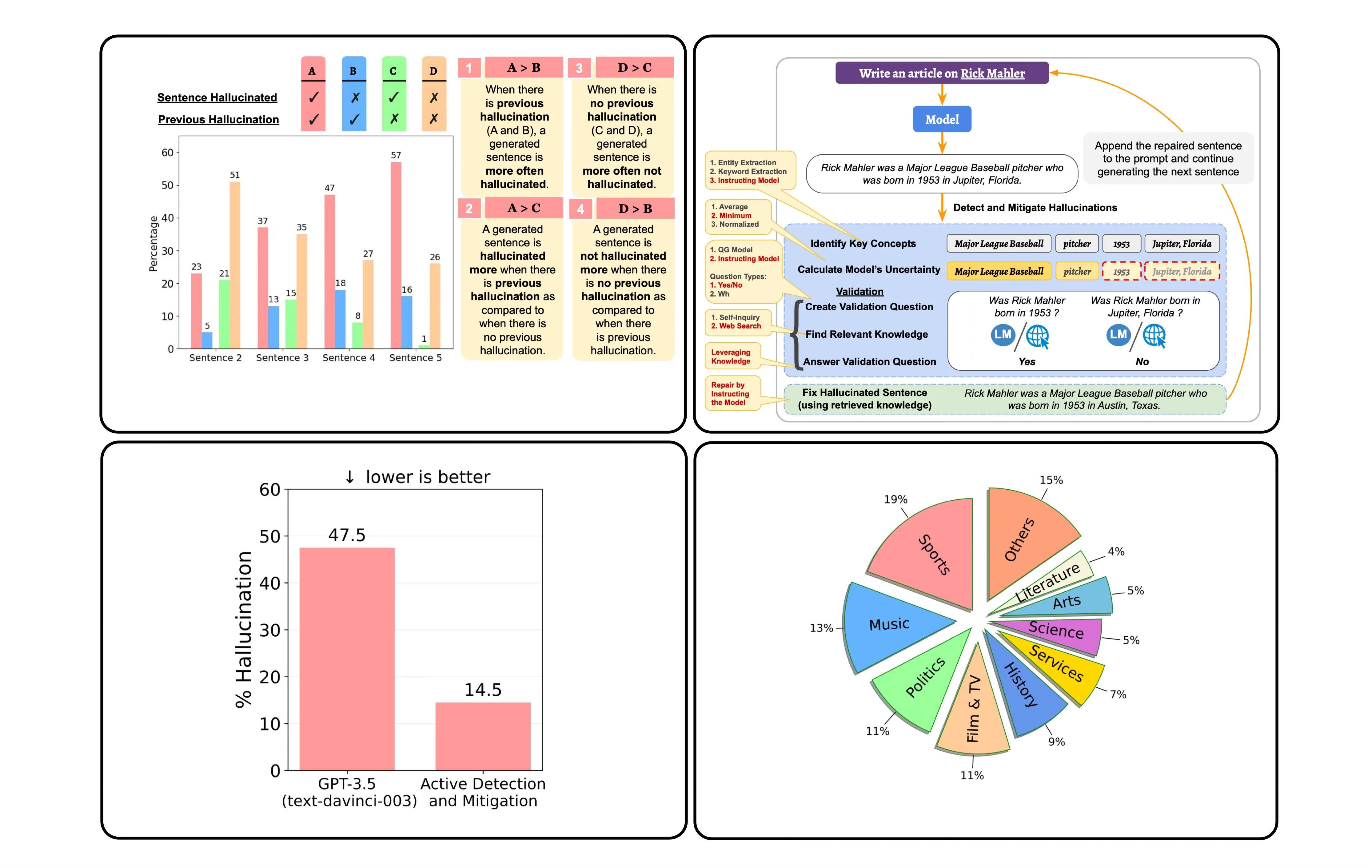
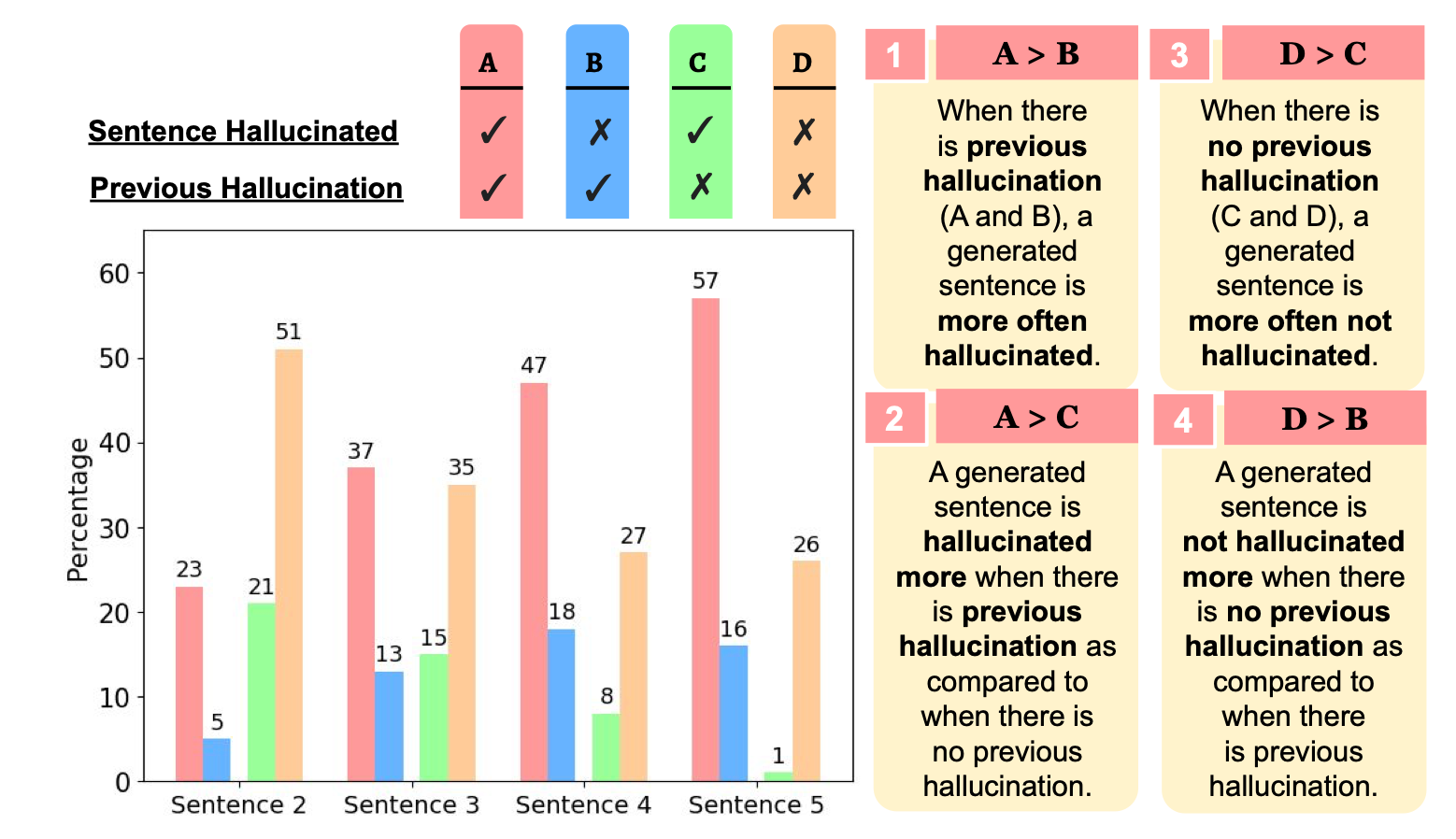
An interesting observation from the study that once hallucination starts, its is propagated to the next sentence; with a very low probability that hallucination will take place in once sentence, and not in the following sentence.
Detection & Mitigation
During the detection phase, hallucination candidates are identified followed by measuring the uncertainty to establish the degree of hallucination. This uncertainty provides a signal for hallucination.
The validation process is quite complex with added overhead:
Create a query that tests the correctness of the information pertaining to the concept,
Retrieve knowledge relevant to the validation question,
Answer the validation question leveraging the retrieved knowledge, and
Verify the corresponding information in the generated sentence to detect hallucinations.
The mitigation and repair phase relies on retrieving relevant reference knowledge. This step is interesting, because we find ourselves again back at a RAG approach where inference is grounded with a contextual reference.
The proposed active detection and mitigation approach successfully reduces the hallucinations of the GPT-3.5 model from 47.5% to 14.5% on average.
Basic Approach
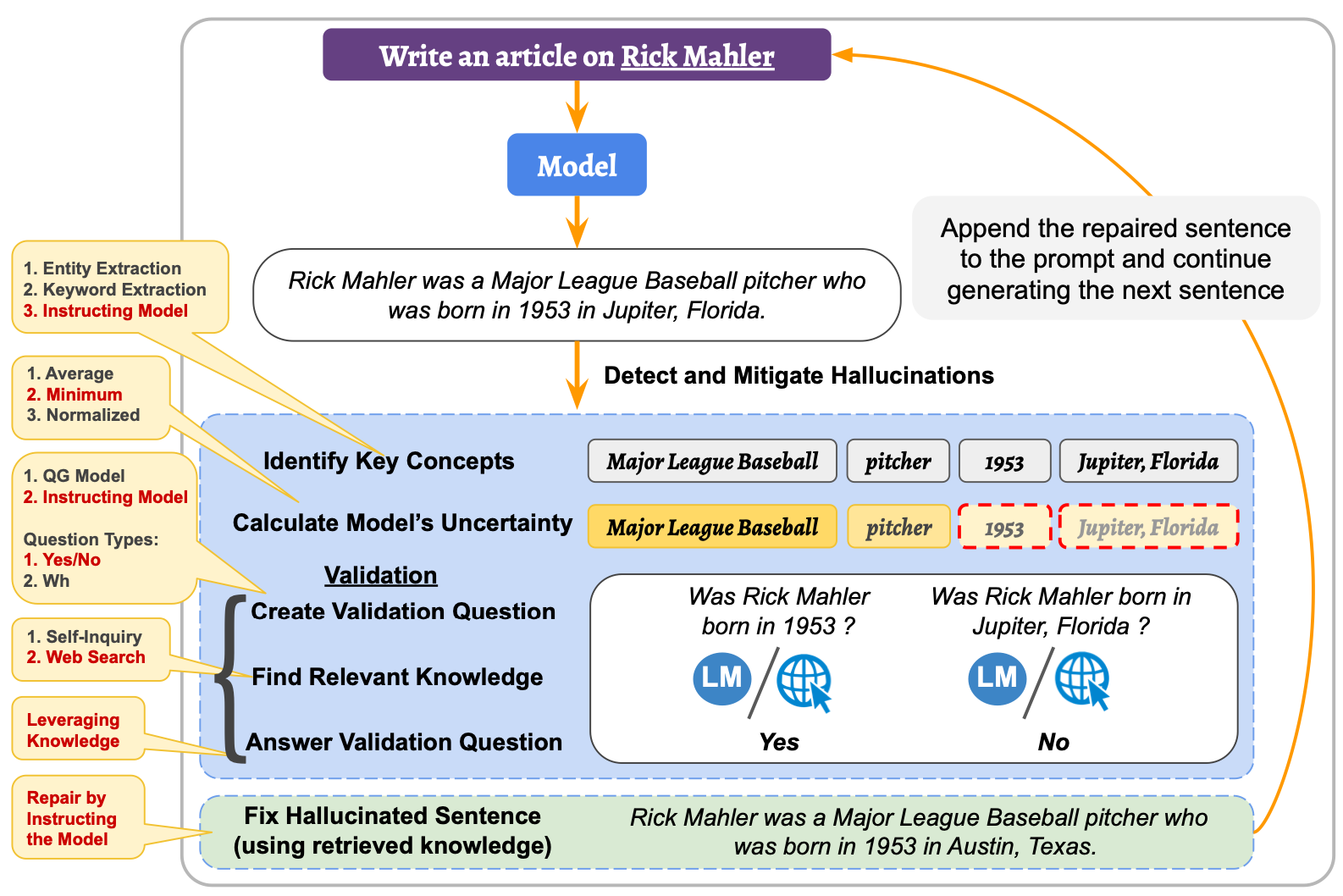
Considering the image below, given an input which passes through the model with the generated text.
The process then enters a phase of detection and mitigation of hallucinations.
In the Hallucination Detection phase, this approach:
Identifies the important concepts,
Calculate model’s uncertainty on them,
Then validate the correctness of the uncertain concepts by retrieving relevant knowledge.
In the Mitigation Stage:
Hallucinated sentences are repaired using the retrieved knowledge as evidence.
Append the repaired sentence to the input (and previously generated sentences) and
Continue generating the next sentence.
This approach not only mitigates hallucination as it happens, but also stems the propagation on subsequent sentences.
Hallucination in the context of language models refers to the generation of text or responses that seem syntactically sound, fluent, and natural but are factually incorrect, nonsensical, or unfaithful to the provided source input.
Detecting Hallucination
Hallucination is detected via Entity Extraction, Keyword Extraction and directly instructing the model to identify the important concepts from the generated sentences.
Considering the graphic below, the study identified patterns in terms of where hallucination shows up in sequences of sentences. The image shows four sentences, A, B, C & D.
Hallucination in a sentence often results in further hallucinations in the subsequently generated sentences and thus actively detecting and mitigating hallucinations can not only fix the current hallucination but can also prevent its propagation in the subsequently generated sentences.
This shows that hallucination is perpetuated and increases once hallucination starts. Even if no remedial action is taken, once hallucination is detected, the complete inference should be considered possibly false.
Relevant Reference Data
Sources of relevant reference data are:
Web-search
Self-inquiry
Validation Question
The table below shows the instructional prompts used for different steps of the approach.
These techniques are the preferred techniques as they do not require calling an external task-specific tool to achieve the corresponding objectives.
I guess there is always that tension between encapsulating functionality in a prompt and building an application structure outside of the prompt.
There is no single approach to this; with the growing complexity of LLM-based solutions, prompts cannot contain the whole and logic needs to be accommodated via chaining, agents, prompt pipelines, etc.

Inference Cost
While this approach improves the reliability of large language models (LLMs) by reducing hallucinations and making the models more trustworthy... This improvement comes with the drawback of increased inference cost.
The authors argue that, despite the higher cost, addressing the reliability and trustworthiness concerns of LLMs is crucial for their widespread adoption, given the rapid pace of computational advancements.
The authors do however acknowledge that their approach can be made more efficient by employing various techniques, such as validating concepts in parallel and executing intermediate steps with a smaller, low-cost model.

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.