Visualise & Discover RAG Data
RAGxplorer is a web-based GUI for importing, chunking, mapping & exploring semantic similarity.

Introduction
RAGxplorer is a work in progress, and a number of improvements came to mind. But it is a very timely development, considering the necessary focus that data centric AI should enjoy.
In the past, I have referred to the four dimensions of data;
Data Discovery
Data Design
Data Development
Data Delivery

Data Delivery has received much attention; data delivery can be described as the methods and means by which propriety data is introduced to the LLM for inference. This can be done via RAG, fine-tuning, prompt-tuning etc.
RAG
In essence Retrieval-Augmented Generation is the process of leveraging the in-context learning abilities of LLMs by injecting prompts with a contextual reference at inference.
Creating a RAG pipeline consists of four basic steps;
Chunking
Creating Embeddings (embeddings is a representation of the semantic relation between phrases.)
Extracting Chunks which is semantically related to a query.
Injecting a prompt with this contextual reference (chunk).
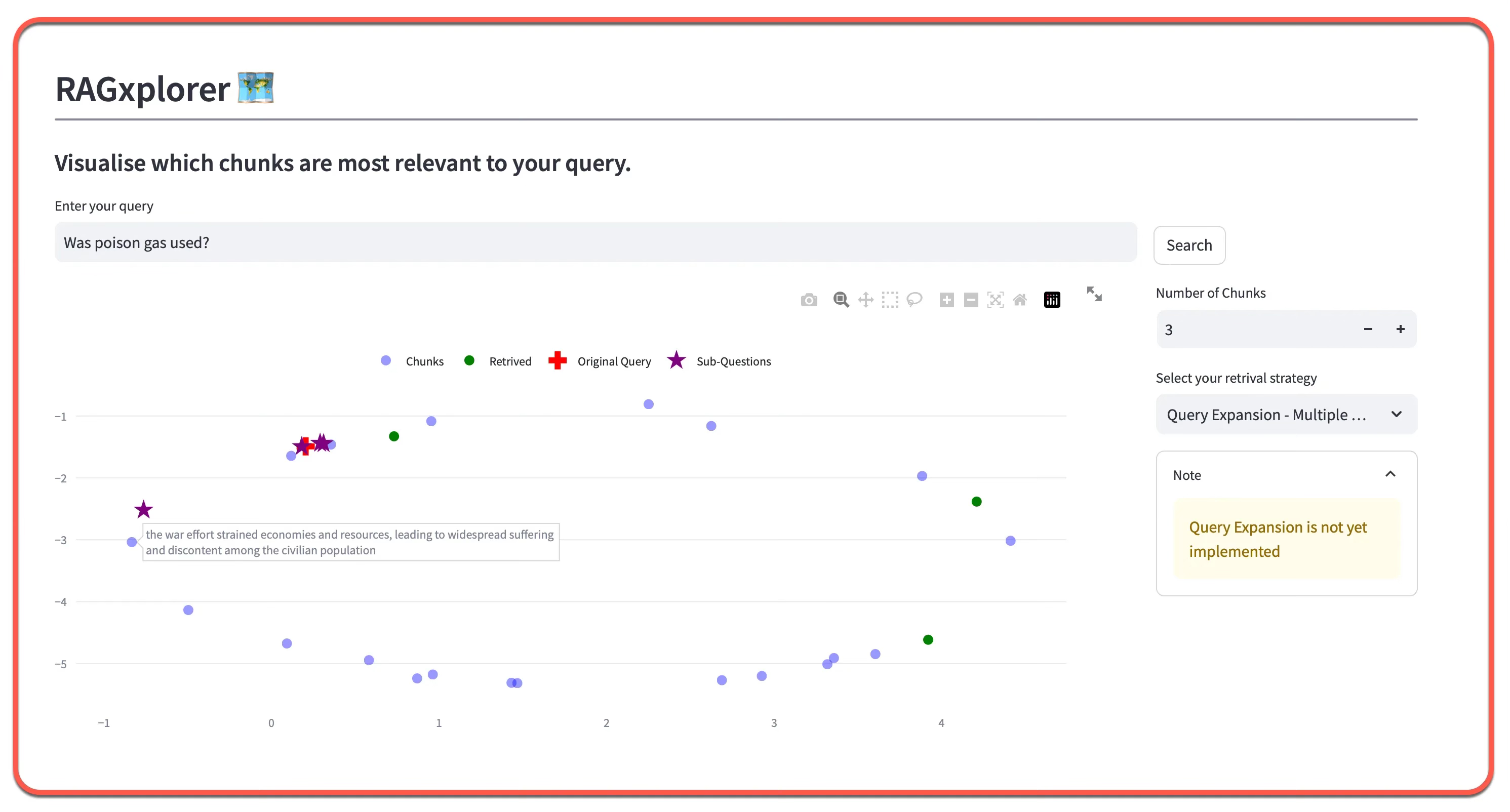
The idea of visual inspection also helps to see which chunks are nearby and were not retrieved; with the tooltip provides the actual text.
RAGxplorer
RAGxplorer is an interactive tool for visualising document chunks in the embedding space. Designed to explore the semantic relation between chunks, and mapping which chunks are linked to a specific user input.

all-MiniLM-L6-v2 and text-embedding-ada-002.RAGxplorer empowers users to upload documents, transforming them into segmented formats (chunks) compatible with RAG applications.
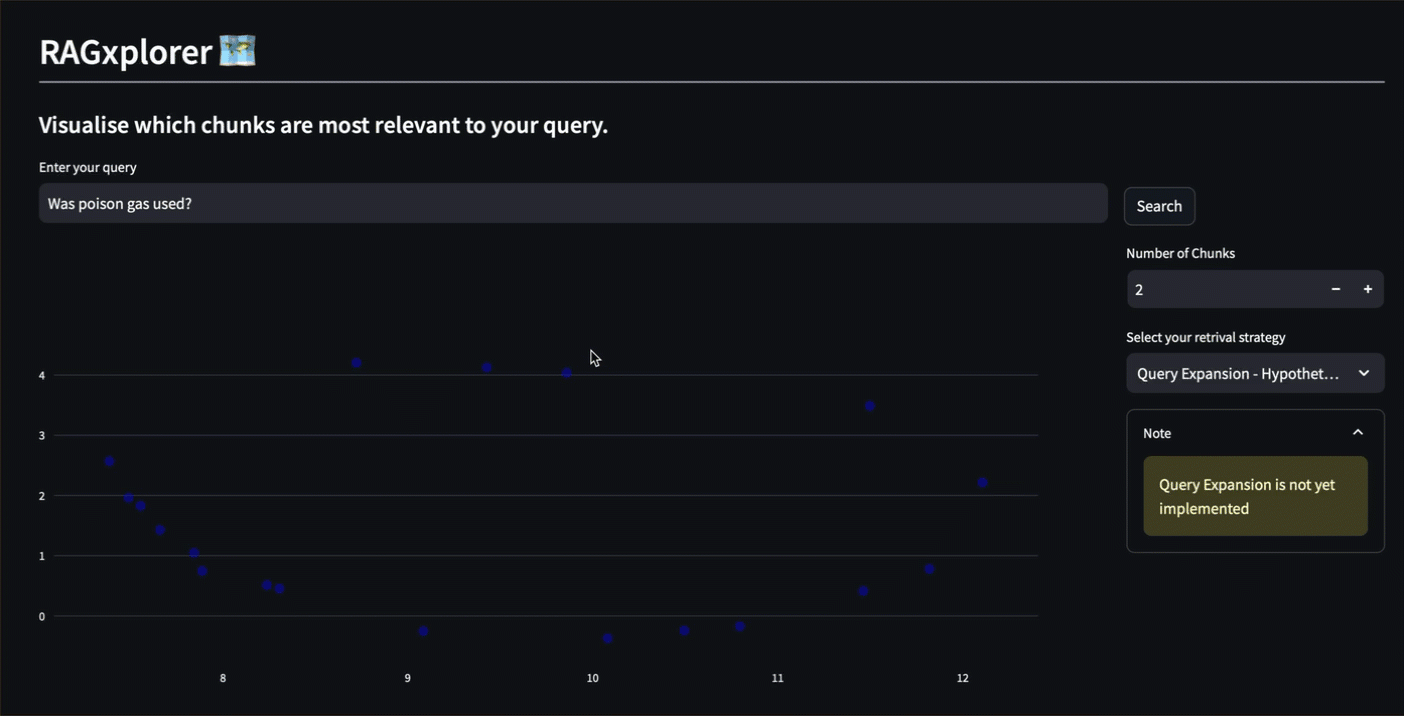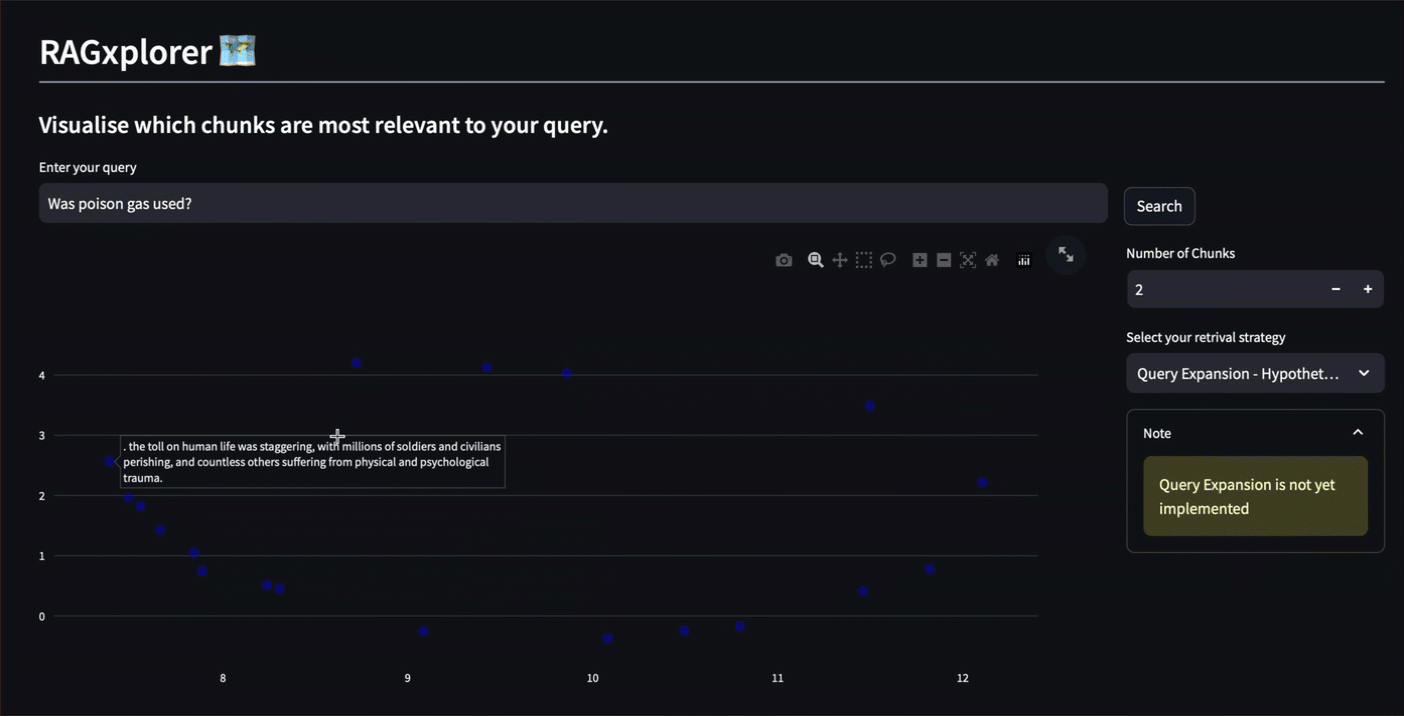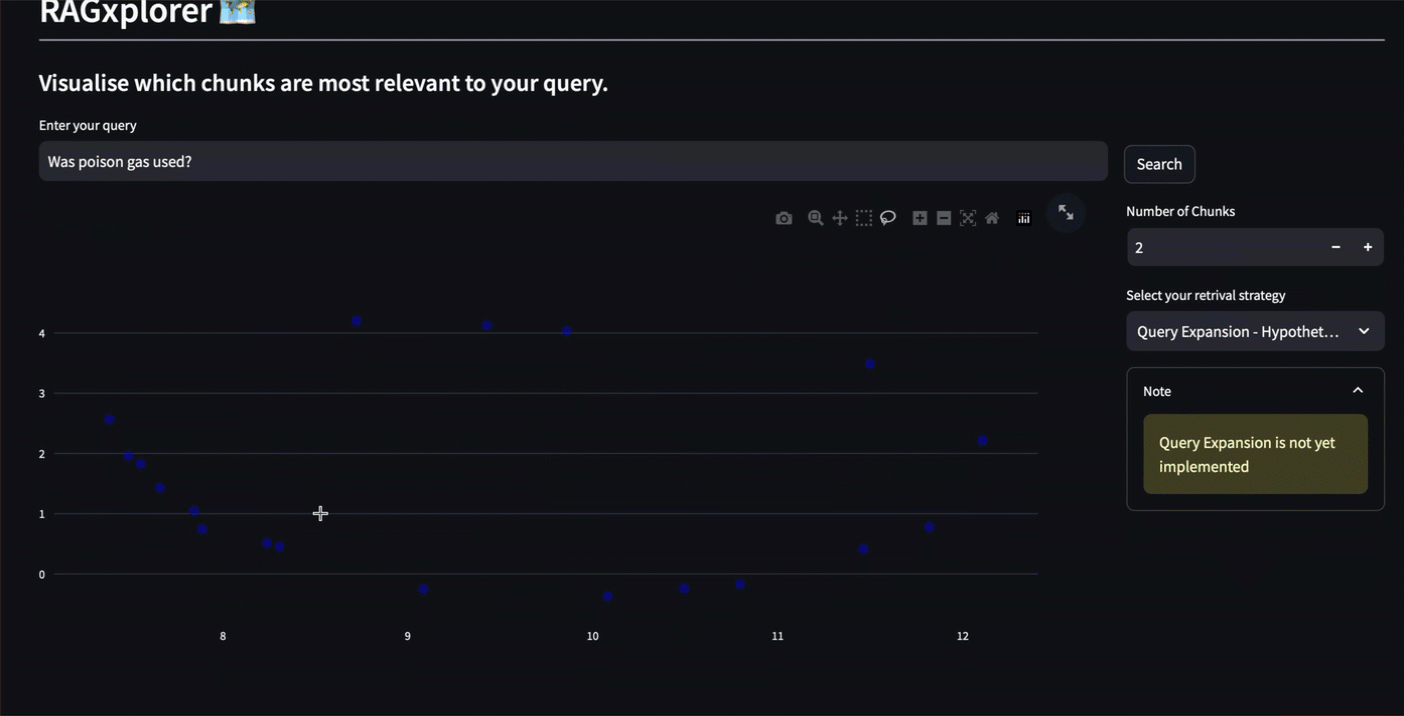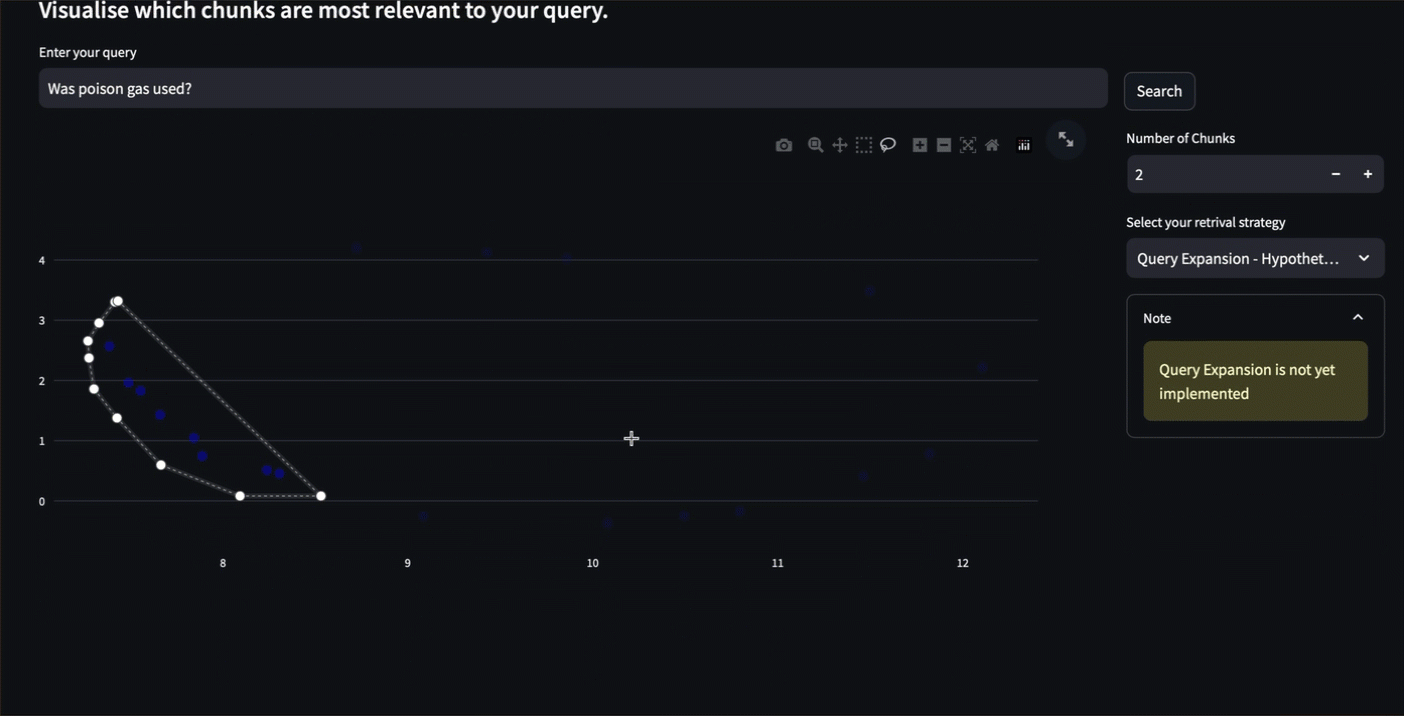
RAGxplorer facilitates the visualisation of these segments in an embedding space. This visual representation enhances comprehension of the interrelationships among different segments and their connections to specific queries, offering valuable insights into the functionality of RAG-based systems.
While visually inspecting chunks, if it seems that the chunks are odd or not similar (and vice-versa, that the related ones are not retrieved), it may mean that users should try a different chunking strategy or embedding model.
In the RAG framework, documents are segmented into parts, referred to as chunks, for efficient searching.
Relevant chunks are then provided to the Language Model (LLM) as supplementary context.

The “Chunk Size” corresponds to the number of tokens within each chunk, while “Chunk Overlap” signifies the number of tokens shared between consecutive chunks to preserve contextual information. It’s worth noting that a single word typically consists of 3 to 4 tokens.

RAGxplorer Features
Document Upload: Users can upload PDF documents that they wish to analyse.
Chunk Configuration: Options to configure the chunk size and overlap, offering flexibility in how the document is processed.
Vector Database Creation: Builds a vector database from the uploaded document for efficient retrieval and visualisation.
Query Expansion: Generates sub-questions and hypothetical answers to enhance the retrieval process.
Interactive Visualisation: Utilises Plotly for dynamic and informative visual representations of the data.
Prompt Injection
The image below from the OpenAI playground shows how the context from the chunk can be injected into a prompt. So the instruction is defined, with the question and the context which serves as reference.
The generated answer is accurate and succinct due to available context to perform in-context learning.

And the response from the OpenAI model:
Yes, poison gas was used during World War I on an unprecedented scale, along with tanks, aircraft, and other weapons. However, the entry of fresh American troops and resources ultimately helped to tip the balance in favor of the Allies and contributed to the eventual crumbling of the Central Powers.
Conclusion
Visualising data in this fashion will not replace detailed inspection of training data. Rather data visualisation should be seen as a higher order of data discovery, and an avenue to perform spot-checks.
Data visualisation is useful to find outliers, and areas which are data-sparce or under represented. These areas might be user intents which needs to be augmented, or it might be considered out of domain.
The generation of sub-questions is an ideal approach to refine responses to user questions. And can also serve as a form of disambiguation, hence allowing the user to select a question when prompted with a disambiguation menu.
Data exploration will become increasingly important, together with making use of a data productivity suite which act as a latent space. One way of describing a latent space, is where data is compressed in order for patterns and trends to emerge.
This is certainly the case with RAGxplorer.
I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.