

WeKnow-RAG
This agentic approach to RAG leverages a graph-based method with a robust data topology to enhance the precision of information retrieval.

Knowledge Graphs enable searching for things and not strings by maintaining extensive collections of explicit facts structured as accurate, mutable, and interpretable knowledge triples.
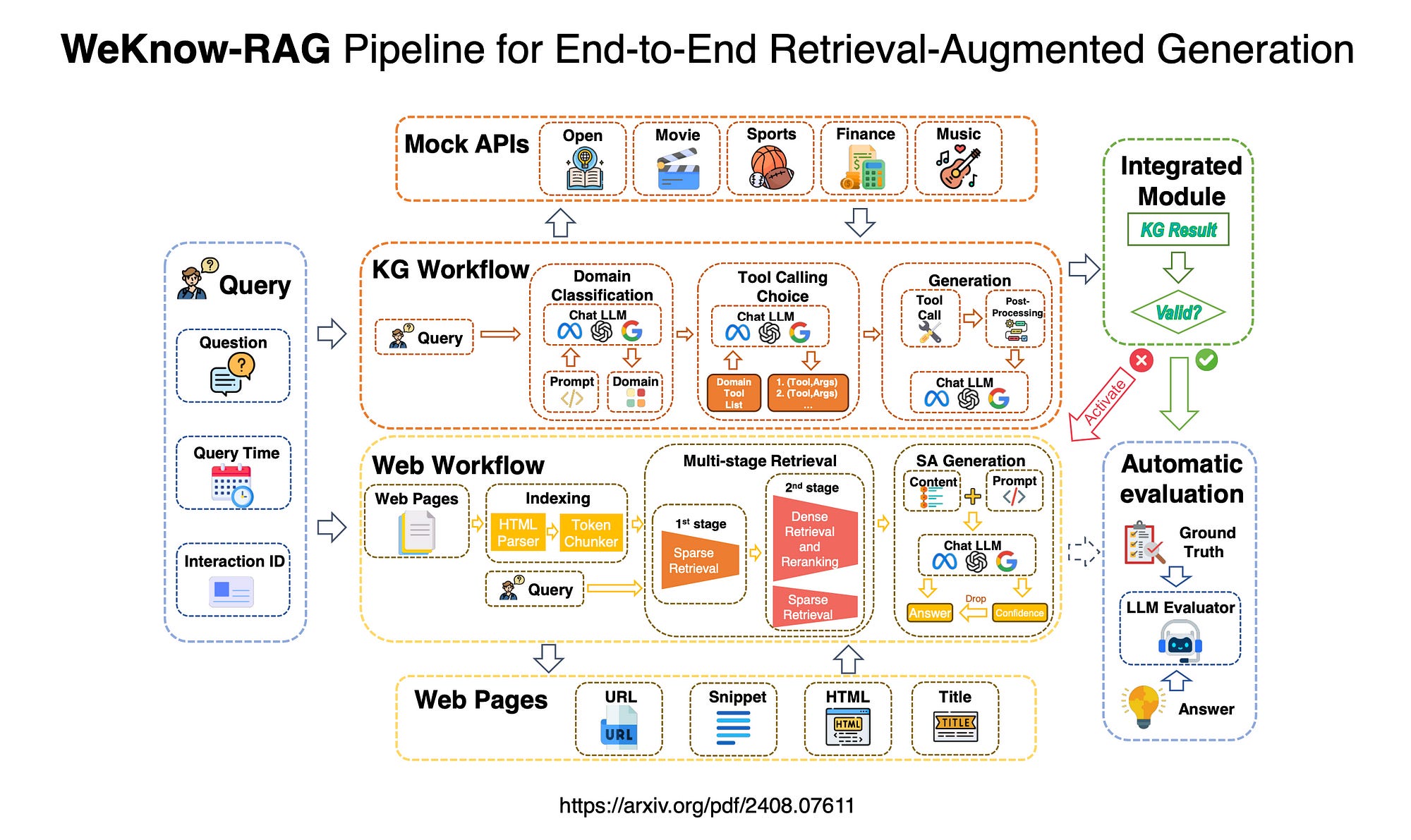
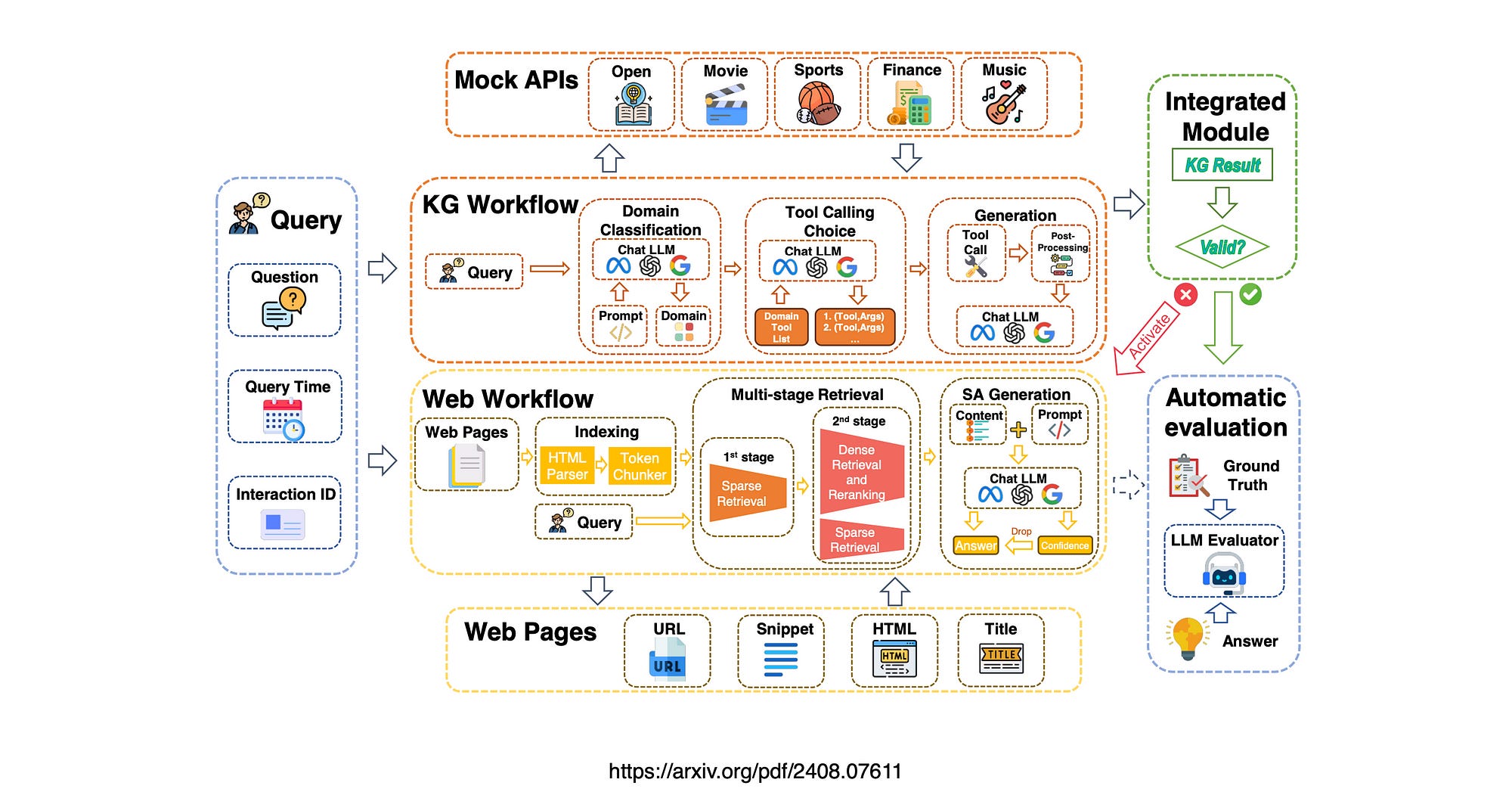
It employs a multi-stage retrieval process, integrating a self-assessment mechanism to ensure accuracy in responses. Domain-specific queries are handled using Knowledge Graphs, while web-retrieved data is processed through parsing and chunking techniques.
TLDR
This RAG implementation is again another good example of where an Agentic Approach is followed to create a resilient, knowledge intensive conversational user interface.
There is also an emergence of a Graph approach from two perspectives. A graph approach is followed for agentic flows; LangChain with LangGraph, LlamaIndex Workflows and Haystack Studio from Deepset to name a few. There is also a Graph approach to knowledge, where more time is spend on data discovery and data design to create stronger data topologies.
WeKnow-RAG is also a multi-stage approach to RAG and it is in keeping with recent developments where complexity is introduced in order to create more resilient and multifaceted solutions.
This approach from WeKnow-RAG includes a self-assessment mechanism.
KG was used for domain specific queries, while parsing and chunking was used for web retrieved data.
This implementation sees both Knowledge Base and a RAG/Chunking approach being combined for instances where data design is possible, or not possible. Often technologies are pitted against each other, in a one or the other scenario. Here it is illustrated that sometimes the answer is somewhere in the middle.
Introduction
This research considers a domain-specific KG-enhanced RAG system which is developed, designed to adapt to various query types and domains, enhancing performance in both factual and complex reasoning tasks.
A multi-stage retrieval method for web pages is introduced, utilising both sparse and dense retrieval techniques to effectively balance efficiency and accuracy in information retrieval.
A self-assessment mechanism for LLMs is implemented, enabling them to evaluate their confidence in generated answers, thereby reducing hallucinations and improving overall response quality.
An adaptive framework is presented that intelligently combines KG-based and web-based RAG methods, tailored to the characteristics of different domains and the rate of information change.
Adaptive & Intelegent Agents
WeKnow-RAG integrates Web search and Knowledge Graphs into a Retrieval-Augmented Generation (RAG) architecture, improving upon traditional RAG methods that typically rely on dense vector similarity search for retrieval.
While these conventional methods segment the corpus into text chunks and use dense retrieval systems exclusively, they often fail to address complex queries effectively.
The Challenges Identified Related To Chunking
RAG chunking implementations face several challenges:
Metadata and Hybrid Search Limitations: Methods that use metadata filtering or hybrid search are restricted by the predefined scope of metadata, limiting the system’s flexibility.
Granularity Issues: Achieving the right level of detail within vector space chunks is difficult, leading to responses that may be relevant but not precise enough for complex queries.
Inefficient Information Retrieval: These methods often retrieve large amounts of irrelevant data, which increases computational costs and reduces the quality and speed of responses.
Over-Retrieval: Excessive data retrieval can overwhelm the system, making it harder to identify the most relevant chunks.
These challenges underscore the need for more refined chunking strategies and retrieval mechanisms to improve relevance and efficiency in RAG systems.
Why KG
An effective RAG system should prioritise retrieving only the most relevant information while minimising irrelevant content.
Knowledge Graphs (KGs) contribute to this goal by offering a structured and precise representation of entities and their relationships.
Unlike vector similarity, KGs organise facts into simple, interpretable knowledge triples (e.g., entity — relationship → entity).
KGs can continuously expand with new data, and experts can develop domain-specific KGs to ensure accuracy and reliability in specialised fields. Many recent developments exemplify this approach, and research is increasingly focused on leveraging graph-based methods in this area.
In all honesty, Knowledge Graphs is an area where I want to improve my skills, as I feel my understanding of the technology is not as strong as it should be.
The following is an excerpt from the function call prompt used for querying knowledge graphs in the Music Domain. The full version includes several additional functions.
"System":"You are an AI agent of linguist talking to a human. ... For all questions you MUST use one of the functions provided. You have access to the following tools":{
"type":"function",
"function":{
"name":"get_artist_info",
"description":"Useful for when you need to get information about an artist, such as singer, band",
"parameters":{
"type":"object",
"properties":{
"artist_name":{
"type":"string",
"description":"the name of artist or band"
},
"artist_information":{
"type":"string",
"description":"the kind of artist information, such as birthplace, birthday, lifespan, all_works, grammy_count, grammy_year, band_members"
}
},
"required":[
"artist_name",
"artist_information"
]
}
}
}"...
To use these tools you must always respond in a Python function
call based on the above provided function definition of the tool! For example":{
"name":"get_artist_info",
"params":{
"artist_name":"justin bieber ",
"artist_information":"birthday"
}
}"User":{
"query"
}Finally
WeKnow-RAG enhances LLM accuracy and reliability by combining structured knowledge from graphs with flexible dense vector retrieval. This system uses domain-specific knowledge graphs for better performance on factual and complex queries and employs multi-stage web retrieval techniques to balance efficiency and accuracy.
Additionally, it incorporates a self-assessment mechanism to reduce errors in LLM-generated answers. The framework intelligently combines KG-based and web-based methods, adapting to different domains and the pace of information change, ensuring optimal performance in dynamic environments.
According to the study, WeKnow-RAG has shown excellent results in extensive tests which stands to reason, as this approach is in alignment with what are being considered as the most promising technology and architectural approaches for the near future.
I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.