What Are LLMs Good At & When Can LLMs Fail?
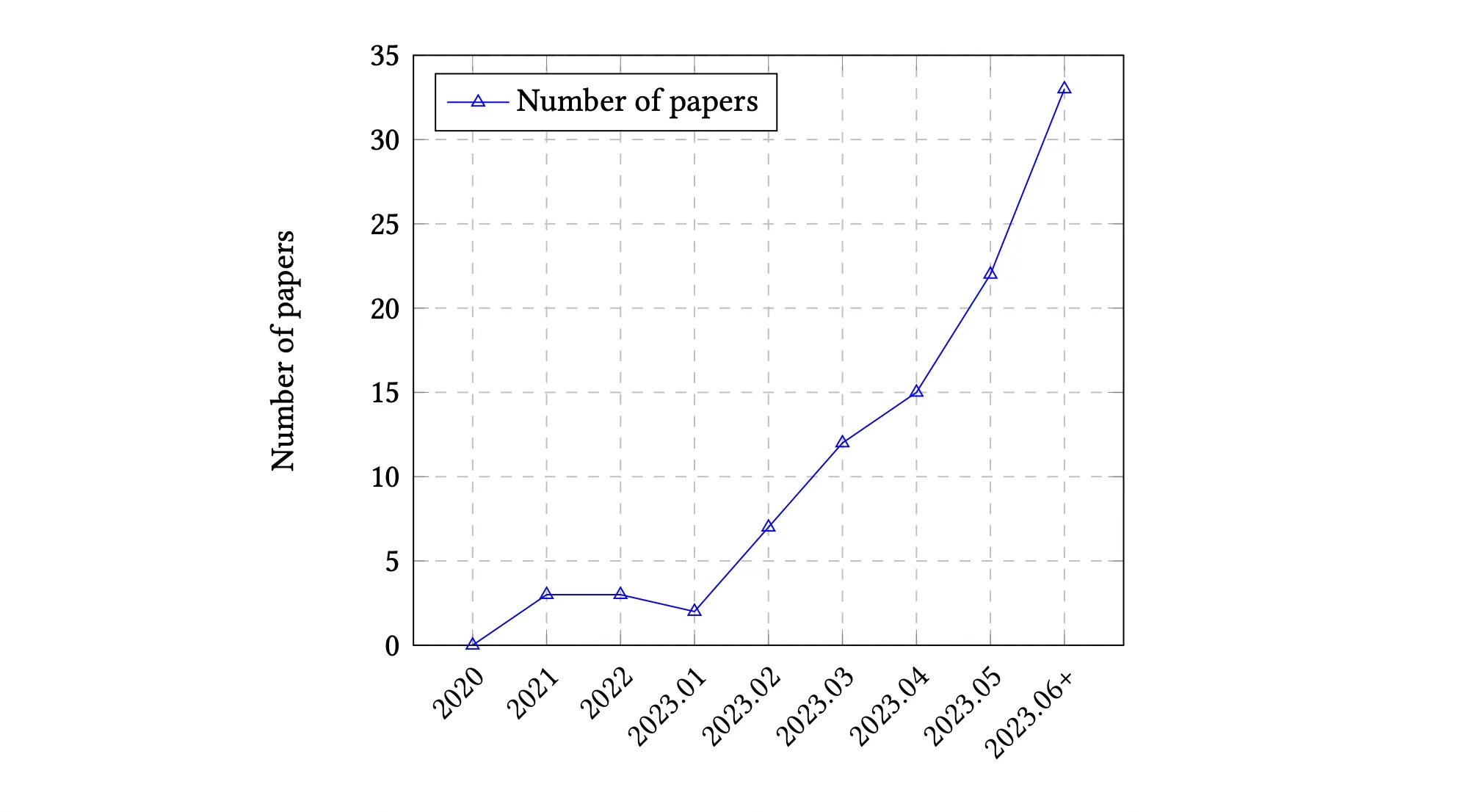
As seen in the graph above, the number of Large Language Model (LLM) related studies are increasing immensely. Considering some of these studies, what are LLMs good at, and at what do they still fail?

What Are LLMs Good At?
It has been proven time and time again, LLMs are proficient in generating text; producing fluent, succinct and precise linguistic expressions.
Large Language Models (LLMs) demonstrate remarkable proficiency in language comprehension tasks, such as sentiment analysis, text categorisation, and processing factual input.
LLMs showcase strong aptitude for arithmetic reasoning, excelling in logical and temporal reasoning. LLMs also demonstrate significant proficiency in more complex tasks like mathematical reasoning and structured data inference, which have become prominent benchmarks for evaluating their capabilities.
LLMs demonstrate strong contextual understanding, allowing them to produce coherent responses that are in line with the provided input. I need to add a caveat here, the challenge is to deliver accurate and highly contextual information at inference time.
LLMs also attain impressive results across various natural language processing tasks, encompassing machine translation, text generation, and question answering.
When Can LLMs Fail?
In the domain of Natural Language Inference (NLI), LLMs display below-average performance and face difficulties in accurately representing human disagreements. NLI is the task of determining whether a given “hypothesis” logically derives from a “premise.”
LLMs may manifest credibility deficits, potentially giving rise to fabricated information or erroneous facts within dialogues.
LLMs exhibit restricted proficiency in discerning semantic similarity between events and demonstrate substandard performance in evaluating fundamental phrases.
LLMs have limited abilities on abstract reasoning, and are prone to confusion or errors in complex contexts. (This has been mitigated to some degree with innovative prompting techniques.)
LLMs have the capacity to assimilate, disseminate, and potentially magnify detrimental content found within the acquired training datasets, frequently encompassing toxic linguistic elements, including offensive, hostile, and derogatory language.
LLMs may exhibit social biases and toxicity during the generation process, resulting in the production of biased outputs.
LLMs have limitations in incorporating real-time or dynamic information, making them less suitable for tasks that require up-to-date knowledge or rapid adaptation to changing contexts.
LLMs is sensitive to prompts, especially adversarial prompts, which trigger new evaluations and algorithms to improve its robustness.
⭐️ Follow me on LinkedIn for updates on Conversational AI ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI and language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.


https://arxiv.org/abs/2307.03109