

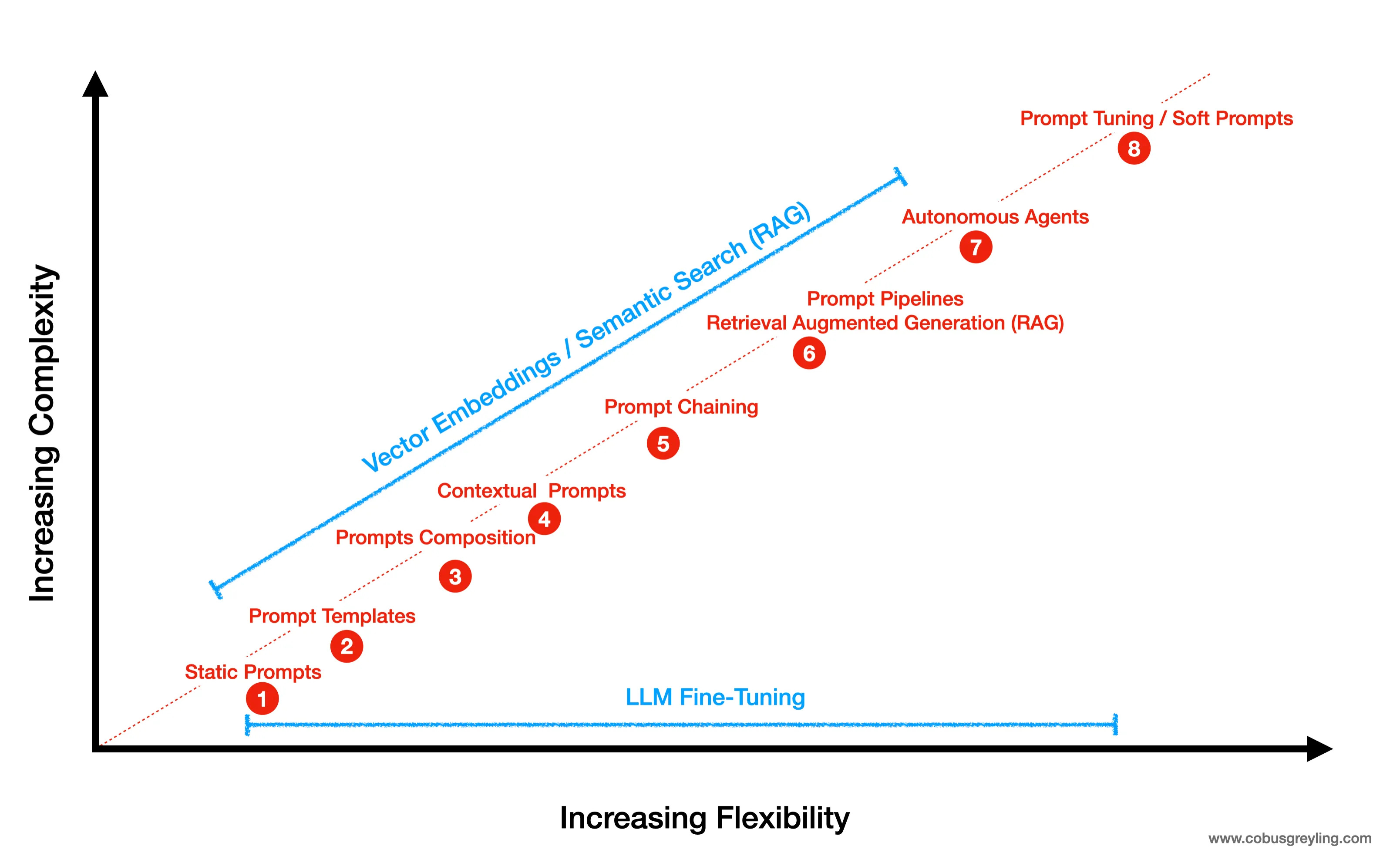
What Is The Future Of Prompt Engineering?
The skill of Prompt Engineering has been touted as the ultimate skill of the future. But, will prompt engineering be around in the near future?

I’m currently the Chief Evangelist @ HumanFirst. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Build Frameworks, natural language data productivity suites & more.
Introduction
The skill of Prompt Engineering has been touted as the ultimate skill of the future. But, will prompt engineering be around in the near future? In this article I attempt to decompose how the future LLM interface might look like…considering it will be conversational.
A year ago, Sam Altman was asked the following question, how will most users interact with Foundation Models in five years time?
Sam Altman responded saying that he does not think we will be using prompt engineering in five years time. He highlighted two main modalities of input, voice or text. And a complete unstructured UI where natural language is the input and the model acting on the instruction of the human.
To some degree this statement is jarring due to the fact that so much technology and innovation is based on the basic principle of prompt engineering.
One can argue that Prompt Engineering is natural language structured in a certain way. But it seems like what the CEO of OpenAI is referring to, are truly unstructured and highly intuitive interfaces.
The best way to try and under stand the future of LLM interfaces is to start by breaking down the use-cases.
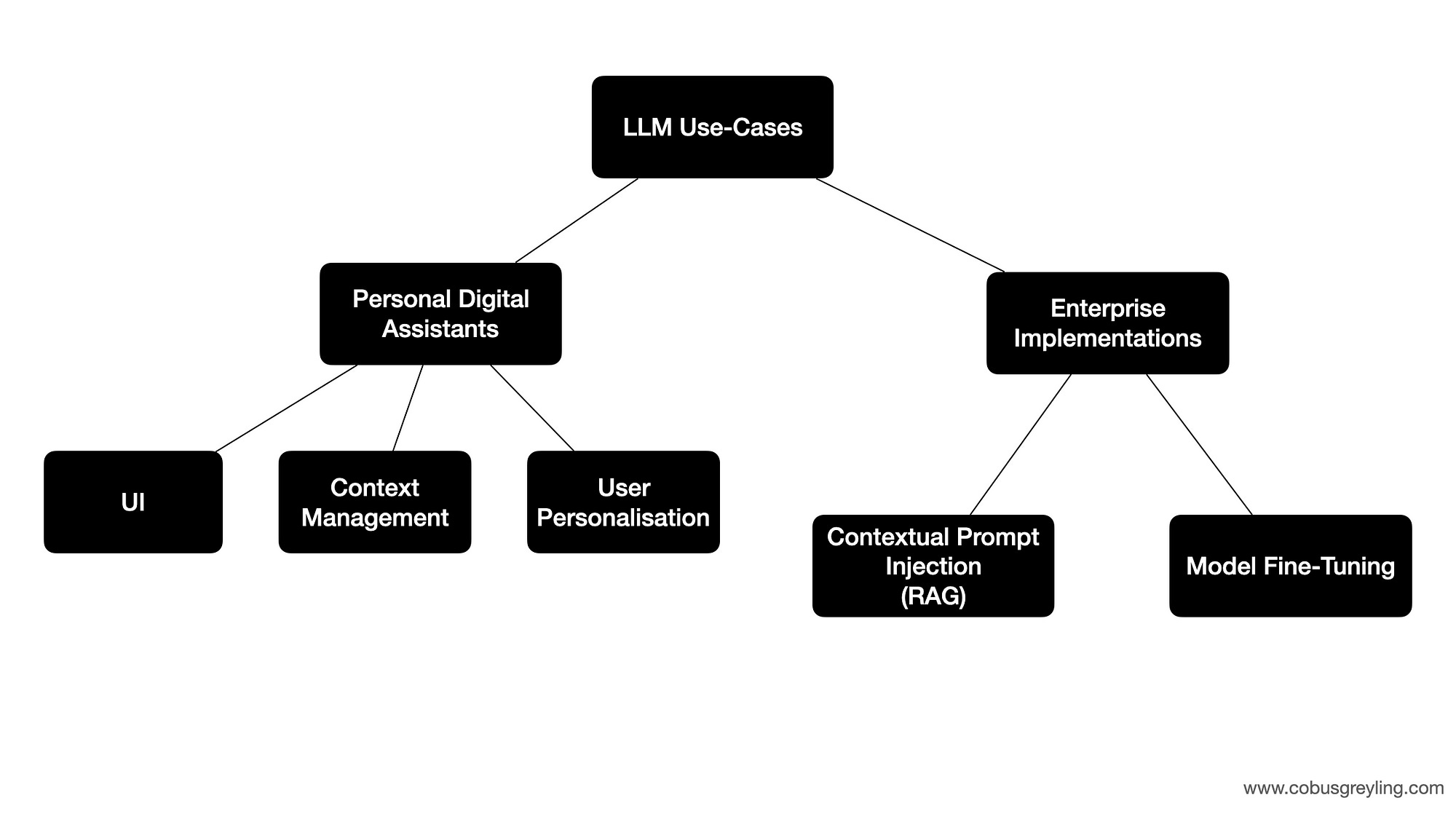
There are two main use-cases; personal and enterprise implementations. Personal use or personal digital assistants currently in circulation are HuggingChat, ChatGPT and Cohere Coral.
What interests me most is highly scaleable enterprise implementations.
Considering enterprise use-cases, the two main approaches for manipulating the LLM is [1] fine-tuning and [2] injecting contextual reference (RAG) data into the prompt at inference (RAG). One approach does not necessarily replace the other. Model Fine-Tuning changes the behaviour and response of the LLM. RAG supplements the user’s input with a contextual reference.
The Problem Of Context & Ambiguity
One of the main challenges of Prompt Engineering is problem statement and problem formulation. Translating a requirement existing in thought, into a text request.
Taking a step back, with traditional chatbots establishing context is very important. Context is first established by classifying the user input according to one or more intents. Further context is established via previous conversations, API calls to CRM systems, etc.
Context also largely depend on time and place, and what our spatial reference is at the time of asking the question.
Apart from contextual awareness, ambiguity is also a challenge. Considering the example below, this form of ambiguity is easy for us as humans to decode; but traditionally harder for NLU/chatbots.

However, consider how well OpenAI answers the question below via the gpt-3.5-turbo model:
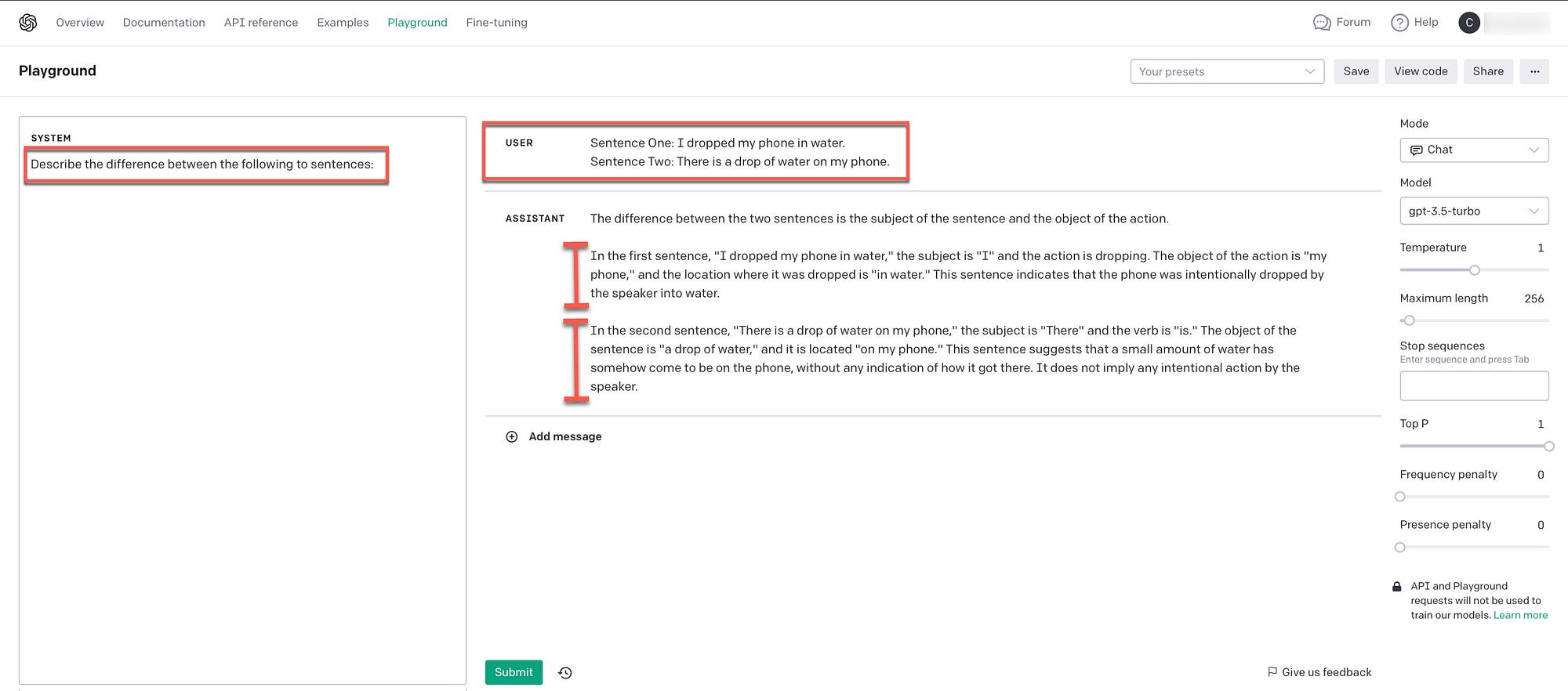
But there is ambiguity which is impossible to resolve with multiple meanings; an example of a sentence which is truly ambiguous and requires disambiguation is: I saw Tom with binoculars.
Structured Conversation
Even-though Sam Altman’s prediction speaks of the interface being more natural and less prompt engineered, there is an interesting phenomenon taking place in terms of LLM input and output.
We saw with OpenAI the Edit and Complete modes being marked as legacy (scheduled for deprecation) and the chat completion mode being set as a de facto standard.
I always argue that complexity needs to be accommodated somewhere, either the UX/UI is more complex…or the user is given an unstructured natural language interface; which in turn then necessitates complexity on the solution side.
With ChatML roles are defined and a definite structure is given to the input to the LLM. As seen in the code example below. Hence the input mode is more conversational, but there is underlying structure imposed which needs to be adhered to.
pip install openai
import os
import openai
openai.api_key = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages = [{"role": "system", "content" : "You are ChatGPT, a large language model trained by OpenAI. Answer as concisely as possible.\nKnowledge cutoff: 2021-09-01\nCurrent date: 2023-03-02"},
{"role": "user", "content" : "How are you?"},
{"role": "assistant", "content" : "I am doing well"},
{"role": "user", "content" : "What is the mission of the company OpenAI?"}]
)
#print(completion)
print(completion)Conclusion
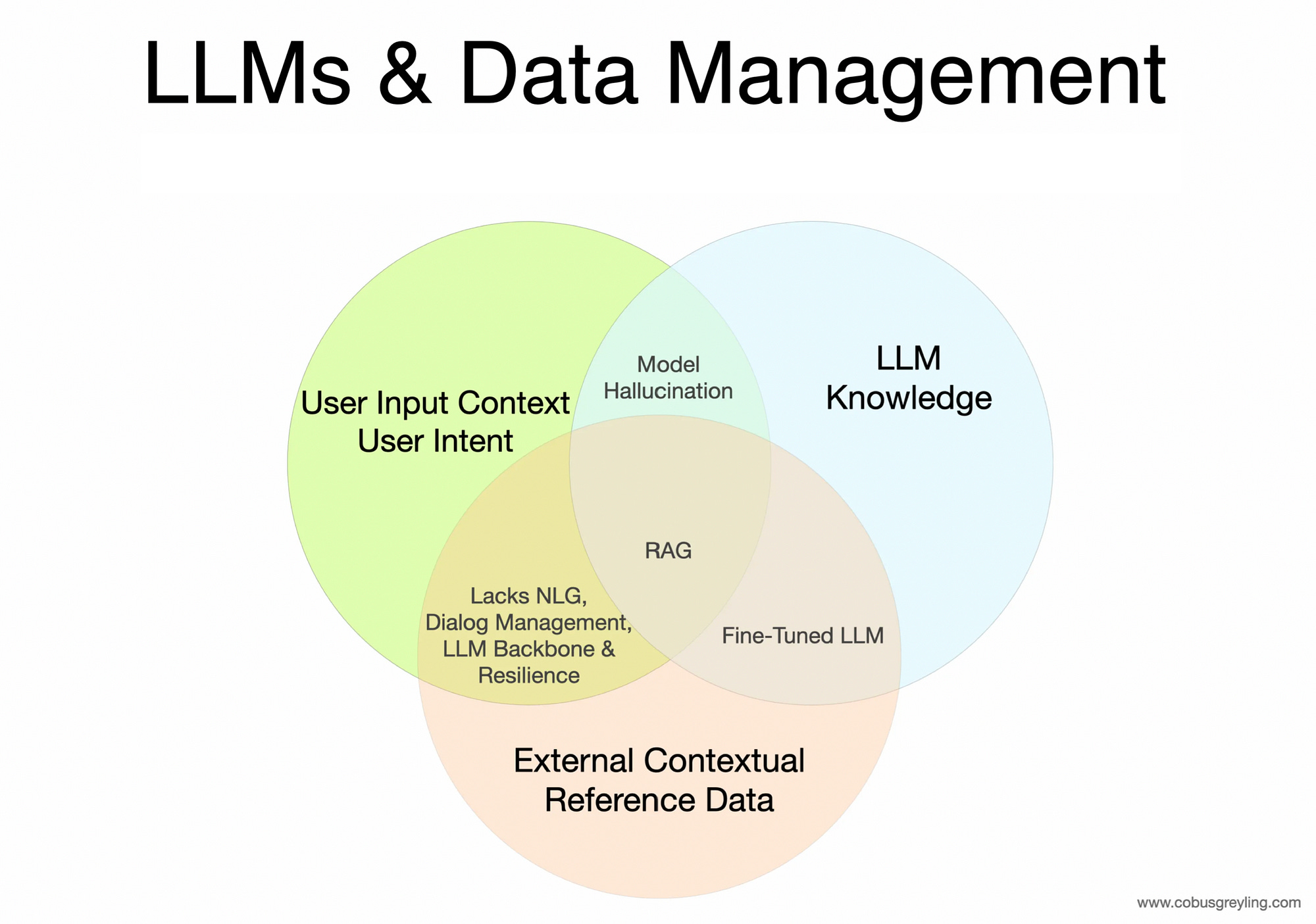
Intent, Context, ambiguity and disambiguation are all part and parcel of any conversation.
With human language interface, context and contextual awareness will always be important.
Ambiguity exists, and a level of disambiguation is part and parcel of human conversation. In human conversation we continuously use disambiguation establish meaning and intent.
Disambiguation can be automated to some degree with in-context auto-learning. This is the process of the conversational UI understanding how to disambiguate in various scenarios based on user input into disambiguation menus.
For instance, asking a LLM to generate five options, and you as the user select the best generated answer, is a form of disambiguation.
Enterprise specific implementation will be domain specific and will demand constraints, with a level of out-of-domain detection.
Problem or request decomposition will aways be important to create a chain of thought reasoning process.
Fine-Tuning will set model behaviour and RAG will supply inference specific context.
RAG creates a contextual reference for the LLM to use during inference.
Data Management will always be part of LLM applications.
The principle of Soft Prompts should be kept in mind. Soft Prompts are created during the process of prompt tuning. Unlike hard prompts, soft prompts cannot be viewed and edited in text.Prompts consist of an embedding, a string of numbers, that derives knowledge from the larger model.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️