Why AI Agent Accuracy Isn’t Where It Should Be
Especially for web browsing & Computer Use


AI agents, powered by Language Models, promise (via the marketing hype) to transform how we interact with technology by automating complex tasks.
However, their accuracy and reliability are still falling short of expectations, especially for real-world applications like browsing the web or using computers.
In this post, I want to break down why this is the case and what it means for their future.
Why AI Agent Accuracy Isn’t Where It Should Be
Studies like “AI Agents That Matter” highlight that current benchmarks often prioritise accuracy over other factors like cost and generalisability.
This narrow focus has led to overly complex and expensive AI Agents that may not perform well outside controlled environments.
For instance, the study found that many benchmarks lack proper holdout sets, causing AI Agents to overfit and take shortcuts, which undermines their real-world reliability.
For tasks like browser use and computer use, benchmarks like τ-Bench and Web Bench show that even top AI Agents struggle with dynamic challenges like authentication and form filling.
This suggests that while accuracy may look good on paper, it doesn’t always translate to practical use, especially in enterprise settings where agents need to handle multiple applications and APIs.

Implications for Real-World Use
The current state of AI agent accuracy means businesses and users must be cautious.
While AI Agents can handle routine tasks, they’re not yet ready for critical operations without extensive testing.
This gap highlights the need for more comprehensive benchmarks that reflect real-world complexities, ensuring AI Agents are both accurate and reliable in dynamic environments.

The State of AI Agent Accuracy
In this section I attempt to provide a comprehensive examination of the accuracy of AI Agents, drawing on recent studies and benchmarking efforts, particularly for tasks involving browser use and computer use.
Background on AI Agents
AI agents are autonomous systems powered by large language models (LLMs), designed to perform tasks, make decisions and interact with tools and users in ways that mimic human behaviour.
They are seen as a transformative technology, with applications ranging from web browsing to enterprise workflow automation.
However, their effectiveness depends heavily on accuracy and reliability, which are currently under scrutiny.
Key Findings from “AI Agents That Matter”
The study “AI Agents That Matter” , published in 2024, provides critical insights into the shortcomings of current AI agent benchmarks. The research analysed evaluation practices and identified several issues:
Narrow Focus on Accuracy
Benchmarks often prioritise accuracy without considering other metrics like cost, reliability and generalisability.
This has led to state-of-the-art (SOTA) AI Agents that are needlessly complex and costly, with the community sometimes drawing mistaken conclusions about the sources of accuracy gains.
On one evaluation created to test developers’ attempts to have models use computers, OSWorld, Claude currently gets 14.9%.
That’s nowhere near human-level skill (which is generally 70–75%), but it’s far higher than the 7.7% obtained by the next-best AI model in the same category.
~ Anthropic
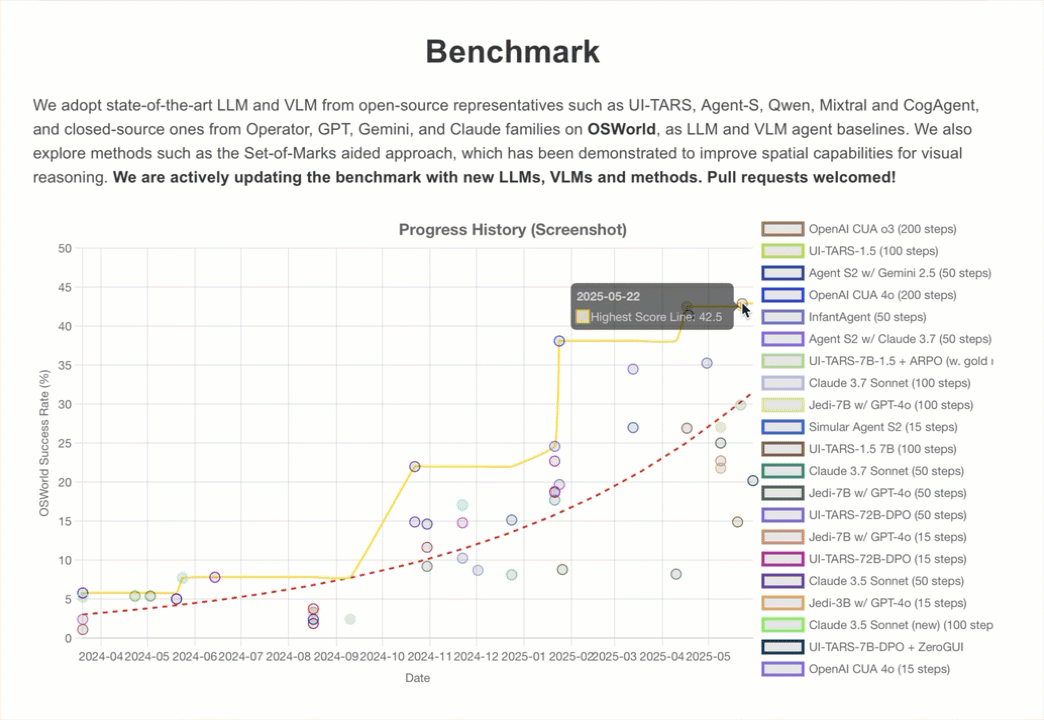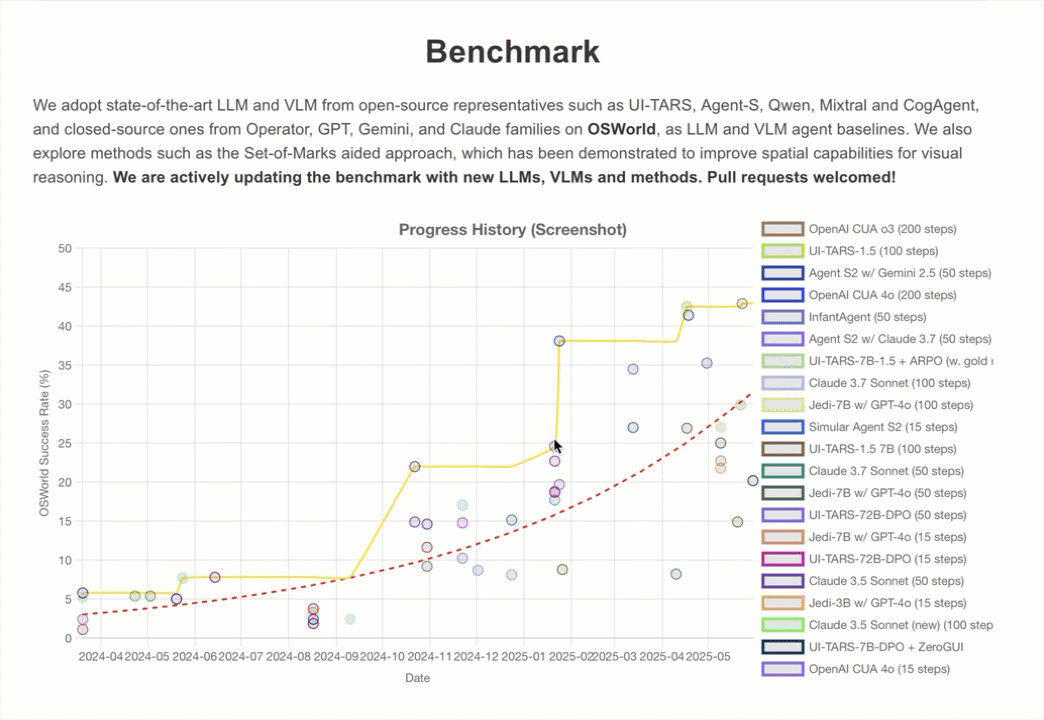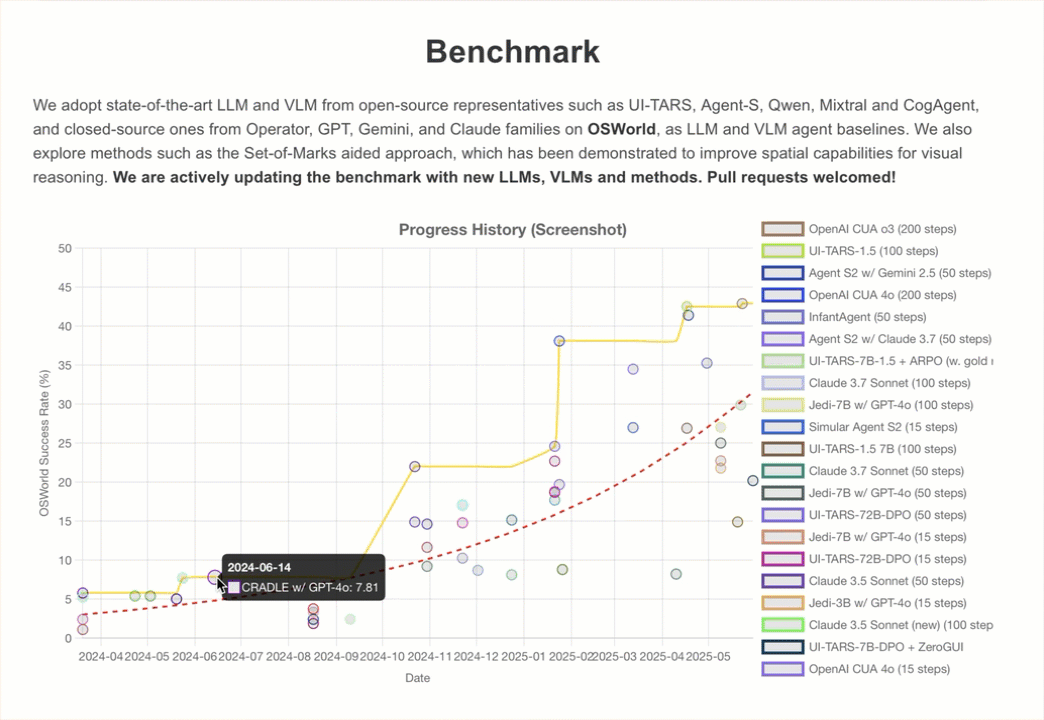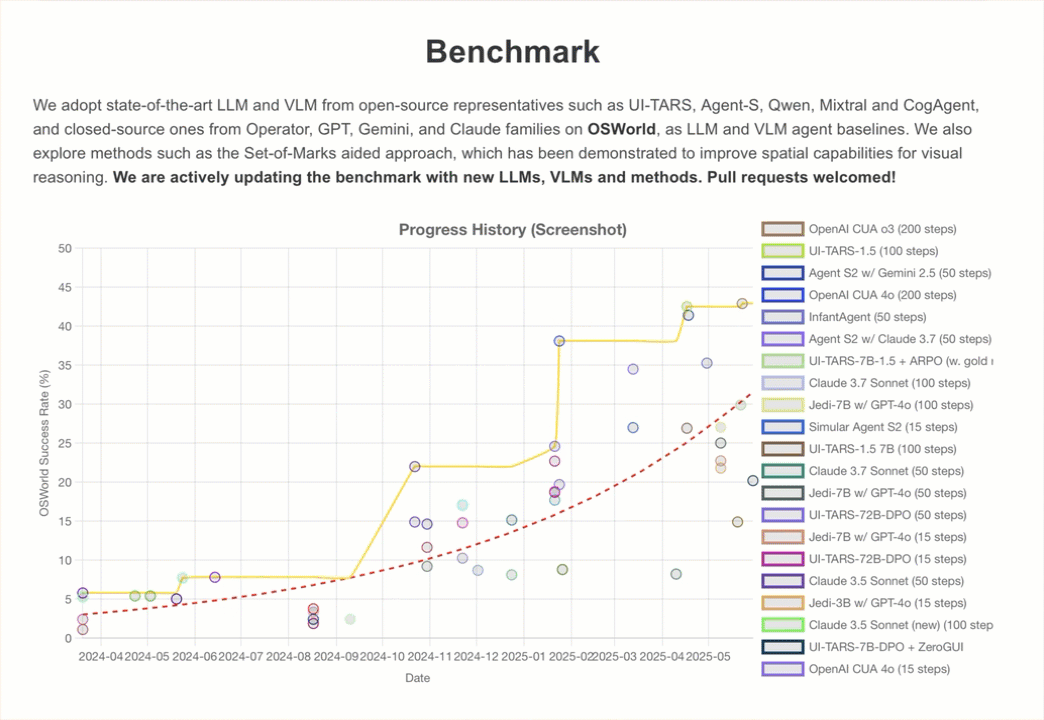
Joint Optimisation of Cost & Accuracy
The study introduces the concept of jointly optimising accuracy and cost, demonstrating through a modification to the DSPy framework on the HotPotQA benchmark that costs can be significantly reduced while maintaining accuracy.
This suggests a need for a more balanced approach to agent evaluation.
Overfitting Due to Inadequate Holdout Sets
Many benchmarks lack adequate holdout sets, leading to overfitting and fragile AI Agents that take shortcuts.
The study prescribes a principled framework to avoid overfitting, emphasising the need for different types of hold-out samples based on the desired level of generality.
Lack of Standardisation and Reproducibility
There is a pervasive lack of standardisation in evaluation practices, with reproducibility errors found in benchmarks like WebArena and HumanEval.
This can inflate accuracy estimates and lead to overoptimism about AI Agent capabilities, as detailed in the paper’s analysis.
The findings indicate that the current focus on accuracy is insufficient for ensuring AI Agents are effective in real-world scenarios, particularly when cost and reliability are critical factors.
Key Challenges
Benchmarks prioritise accuracy over cost, reliability & generalisability, leading to complex, costly AI Agents.
Inadequate holdout sets in benchmarks cause overfitting, reducing real-world reliability.
Poor reproducibility in evaluations (e.g., WebArena, HumanEval) inflates accuracy estimates.
Dynamic Real-World Tasks, AI Agents struggle with browser tasks like authentication, form filling and file downloading, as shown in τ-Bench and Web Bench.
Enterprise-Specific Needs, standard benchmarks fail to model enterprise barriers like authentication and multi-application workflows.
Implications for Real-World Deployment
The current state of AI Agent accuracy has significant implications for their deployment in real-world applications.
Research suggests that AI Agents are not yet ready to fully replace human workers in complex tasks, as their accuracy and reliability are not on par with human performance.
This is particularly evident in tasks requiring nuanced understanding, adaptability and error recovery, which are essential in dynamic environments.
For businesses and organisations, this means that while AI Agents can augment human capabilities and handle routine tasks, they should not be relied upon for critical operations without thorough testing and validation.
The hype around AI Agents must be tempered with realism, recognising that their current accuracy is insufficient for many high-stakes applications, especially in enterprise settings where reliability is paramount.

{kind=link}
The Future
The analysis points to several areas for future research and development:
Developing more comprehensive benchmarks that account for cost, reliability and real-world dynamics.
Improving standardisation and reproducibility in evaluation practices to ensure accurate performance assessments.
Advancing AI Agent architectures to better handle dynamic tasks, particularly in browser use and computer use scenarios.
Focusing on enterprise-specific needs, such as multi-application workflows and operational barriers, to bridge the gap between benchmarks and real-world deployment.

Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. From Language Models, AI Agents to Agentic Applications, Development Frameworks & Data-Centric Productivity Tools, I share insights and ideas on how these technologies are shaping the future.