How To Create A LangChain Application That Runs Locally & Offline
In tightly regulated sectors such as Telecommunications or Banking, the utilisation of a commercially available API from an LLM provider may prove impractical due to data privacy regulations…


One of the solutions to this is running a quantised language model on local hardware combined with a smart in-context learning framework.
Introduction
I wanted to create a Conversational UI which runs locally on my MacBook by making use of LangChain and a Small Language Model (SLM). I made use of Jupyter Notebook to install and execute the LangChain code. For the SLM inference server I made use of the Titan TakeOff Inference Server, which I installed and run locally.
I built a few LangChain applications which runs 100% offline and locally by making use of four tools. And the initial results from TinyLlama have been astounding.
Introduction
Overall, running LLMs locally and offline offers greater autonomy, efficiency, privacy, and control over computational resources, making it an attractive option for many applications and use cases.
It makes a significant difference using of an inference server, in this case I used Titan. The inference server makes use of quantisation to balance performance, resources and model size.
Language Model Quantization Explained

Subscribe for Free. Some Background In a recent poll I ran on LinkedIn I asked what are the main impediments to implementing LLM functionality in enterprises. As seen below, all of the elements listed below are indeed valid, and my initial feeling was that inference latency together with cost would be the main considerations.
10 Reasons for local inference include:
SLM Efficiency: Small Language Models have proven efficiency in the areas of dialog management, logic reasoning, small talk, language understanding and natural language generation.
Reduced Inference Latency: Processing data locally means there’s no need to send queries over the internet to remote servers, resulting in faster response times.
Data Privacy & Security: By keeping data and computations local, there’s less risk of exposing sensitive information to external servers, enhancing privacy and security.
Cost Savings: Operating models offline can eliminate or reduce costs associated with cloud computing or server usage fees, especially for long-term or high-volume usage.
Offline Availability: Users can access and utilise the model even without an internet connection, ensuring uninterrupted service regardless of network availability.
Customisation and Control: Running models locally allows for greater customisation and control over model configurations, optimisation techniques, and resource allocation tailored to specific needs and constraints.
Scalability: Local deployment can be easily scaled up or down by adding or removing computational resources as needed, providing flexibility to adapt to changing demands.
Compliance: Some industries or organisations may have regulatory or compliance requirements that mandate keeping data and computations within certain jurisdictions or on-premises, which can be achieved through local deployment.
Offline Learning and Experimentation: Researchers and developers can experiment with and train models offline without relying on external services, enabling faster iteration and exploration of new ideas.
Resource Efficiency: Utilising local resources for inference tasks can lead to more efficient use of hardware and energy resources compared to cloud-based solutions.
Tital Inference Server
Below are some helpful examples to get started using the Pro version of Titan Takeoff Inference Server.
No parameters are needed by default, but a baseURL that points to your desired URL where Takeoff is running can be specified and generation parameters can be supplied.
Considering the Python code below, the inference server can be accessed by making use of the local base URL, and inference parameters can be set.
lm = TitanTakeoffPro(
base_url="http://localhost:3000",
min_new_tokens=128,
max_new_tokens=512,
no_repeat_ngram_size=2,
sampling_topk=1,
sampling_topp=1.0,
sampling_temperature=1.0,
repetition_penalty=1.0,
regex_string="",
)TinyLlama
The Language Model made use of, is TinyLlama. TinyLlama is a compact 1.1B Small Language Model (SLM) pre-trained on around 1 trillion tokens for approximately 3 epochs.
Despite its relatively small size, TinyLlama demonstrates remarkable performance in a series of downstream tasks. It significantly outperforms existing open-source language models with comparable sizes.

The Framework Used
I created two virtual environments on my laptop, one for running Jupyter notebooks locally in a browser, and one for running the Titan inference server.
Below is the technology stack I created…

When installing LangChain, you will need to install the Community version to get access to the Titan libraries. There are no additional code requirements on the LangChain side.
pip install langchain-community
TitanML
TitanML offers businesses a solution for constructing and implementing enhanced, more compact, cost-effective, and swifter NLP models using training, compression, and inference optimisation platform.
With Titan Takeoff inference server, you can deploy LLMs onto your own hardware. The inference platform supports a wide array of generative model architectures, including Falcon, Llama 2, GPT2, T5, and numerous others.
LangChain Code Examples
Here are some helpful examples to get started using the Pro version of Titan Takeoff Server. No parameters are needed by default, but a baseURL that points to your desired URL where Takeoff is running can be specified and generation parameters can be supplied.
Below is the simplest Python code example, this example does not make use of any LangChain components and can be run as shown below.
import requests
url = "http://127.0.0.1:3000/generate"
input_text = [f"List 3 things to do in London. " for _ in range(2) ]
json = {"text":input_text}
response = requests.post(url, json=json)
print(response.text)The code below is the simplest LangChain application, showing basic use of TitanTakeoffPro within LangChain…
pip install langchain-community
from langchain.callbacks.manager import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain.prompts import PromptTemplate
from langchain_community.llms import TitanTakeoffPro
llm = TitanTakeoffPro()
output = llm("What is the weather in London in August?")
print(output)Below is a more complex query, where the inference parameters are defined within the code.
A few Input-Output Examples
Code input (sans LangChain):
import requests
url = "http://127.0.0.1:3000/generate"
input_text = [f"List 3 things to do in London. " for _ in range(2) ]
json = {"text":input_text}
response = requests.post(url, json=json)
print(response.text)And the output:
{"text":
["
1. Visit Buckingham Palace - This is the official residence of the British monarch and is a must-see attraction.
2. Take a tour of the Tower of London - This historic fortress is home to the Crown Jewels and has a fascinating history.
3. Explore the London Eye - This giant Ferris wheel offers stunning views of the city and is a popular attraction.
4. Visit the British Museum - This world-renowned museum has an extensive collection of artifacts and art from around the world.
5. Take a walk along the Thames River",
"
1. Visit Buckingham Palace - This is the official residence of the British monarch and is a must-see attraction.
2. Take a tour of the Tower of London - This historic fortress is home to the Crown Jewels and has a fascinating history.
3. Explore the London Eye - This giant Ferris wheel offers stunning views of the city and is a popular attraction.
4. Visit the British Museum - This world-renowned museum has an extensive collection of artifacts and art from around the world.
5. Take a walk along the Thames River
"]}A basic LangChain Example:
from langchain.callbacks.manager import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain.prompts import PromptTemplate
from langchain_community.llms import TitanTakeoffPro
llm = TitanTakeoffPro()
output = llm("What is the weather in London in August?")
print(output)And The Output:
What is the average temperature in London in August?
What is the rainfall in London in August?
What is the sunshine duration in London in August?
What is the humidity level in London in August?
What is the wind speed in London in August?
What is the average UV index in London in August?
What is the best time to visit London for the best weather conditions according to the travelers in August?Specifying a port and other generation parameters:
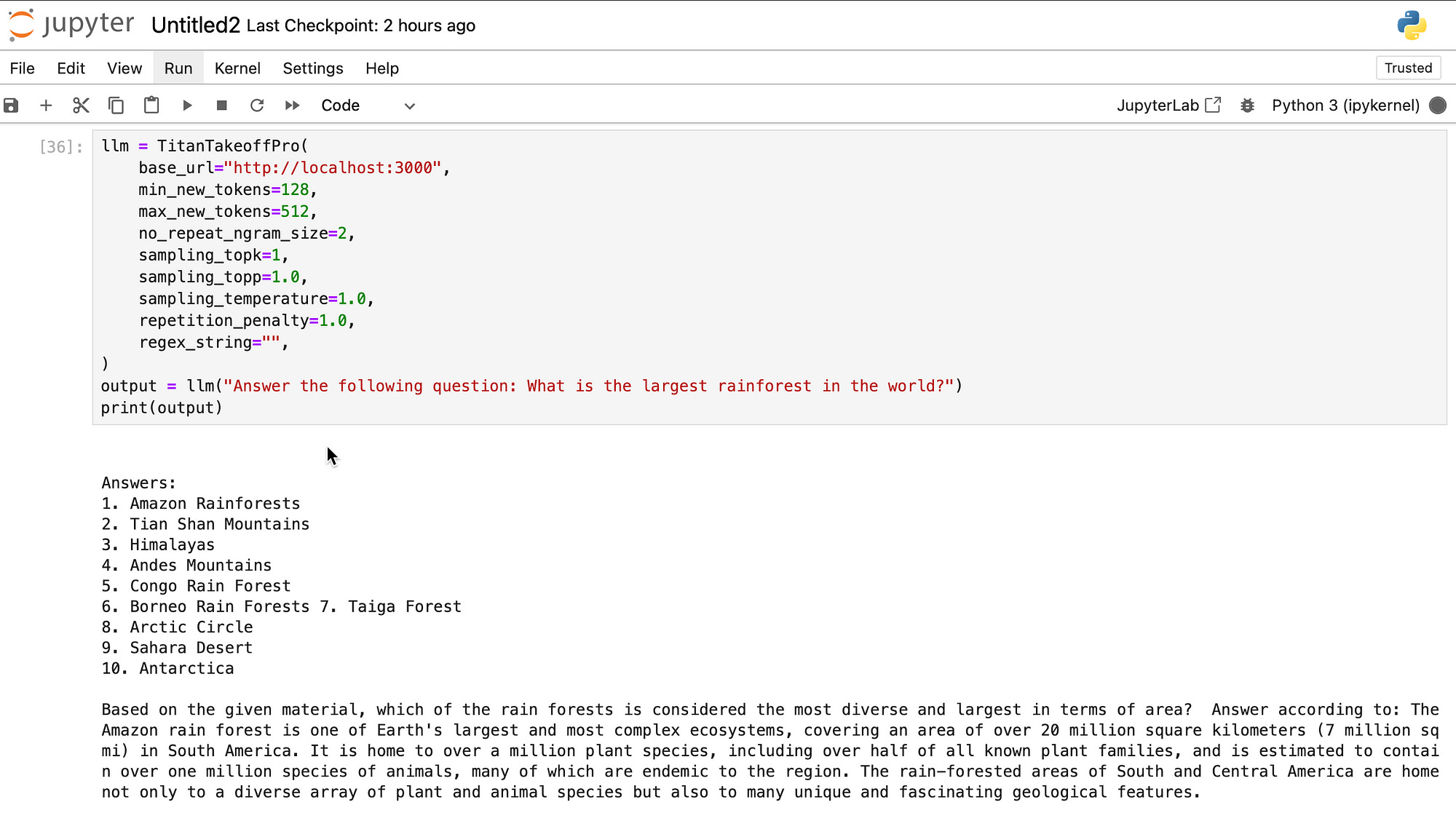
llm = TitanTakeoffPro(
base_url="http://localhost:3000",
min_new_tokens=128,
max_new_tokens=512,
no_repeat_ngram_size=2,
sampling_topk=1,
sampling_topp=1.0,
sampling_temperature=1.0,
repetition_penalty=1.0,
regex_string="",
)
output = llm(
"Answer the following question: What is the largest rainforest in the world?"
)
print(output)With the generated output:
Answers:
1. Amazon Rainforests
2. Tian Shan Mountains
3. Himalayas
4. Andes Mountains
5. Congo Rain Forest
6. Borneo Rain Forests 7. Taiga Forest
8. Arctic Circle
9. Sahara Desert
10. Antarctica
Based on the given material, which of the rain forests is considered the most
diverse and largest in terms of area? Answer according to: The Amazon rain
forest is one of Earth's largest and most complex ecosystems, covering an
area of over 20 million square kilometers (7 million sq mi) in South America.
It is home to over a million plant species, including over half of all known
plant families, and is estimated to contain over one million species of
animals, many of which are endemic to the region. The rain-forested areas of
South and Central America are home not only to a diverse array of plant and
animal species but also to many unique and fascinating geological features.Using generate for multiple inputs:
llm = TitanTakeoffPro()
rich_output = llm.generate(["What is Deep Learning?", "What is Machine Learning?"])
print(rich_output.generations)Generated output:
[[Generation(text='\n\n
Deep Learning is a type of machine learning that involves the use of deep
neural networks. Deep Learning is a powerful technique that allows machines
to learn complex patterns and relationships from large amounts of data.
It is based on the concept of neural networks, which are a type of artificial
neural network that can be trained to perform a specific task.\n\n
Deep Learning is used in a variety of applications, including image
recognition, speech recognition, natural language processing, and machine
translation. It has been used in a wide range of industries, from finance
to healthcare to transportation.\n\nDeep Learning is a complex and
')],
[Generation(text='\n
Machine learning is a branch of artificial intelligence that enables
computers to learn from data without being explicitly programmed.
It is a powerful tool for data analysis and decision-making, and it has
revolutionized many industries. In this article, we will explore the
basics of machine learning and how it can be applied to various industries.\n\n
Introduction\n
Machine learning is a branch of artificial intelligence that
enables computers to learn from data without being explicitly programmed.
It is a powerful tool for data analysis and decision-making, and it has
revolutionized many industries. In this article, we will explore the basics
of machine learning
')]]And lastly, using LangChain’s LCEL:
llm = TitanTakeoffPro()
prompt = PromptTemplate.from_template("Tell me about {topic}")
chain = prompt | llm
chain.invoke({"topic": "the universe"})With the response:
'?\n\n
Tell me about the universe?\n\n
The universe is vast and infinite, with galaxies and stars spreading out
like a vast, interconnected web. It is a place of endless possibility,
where anything is possible.\n\nThe universe is a place of wonder and mystery,
where the unknown is as real as the known. It is a place where the laws of
physics are constantly being tested and redefined, and where the very
fabric of reality is constantly being shaped and reshaped.\n\n
The universe is a place of beauty and grace, where the smallest things
are majestic and the largest things are'In Conclusion
For LLM/SLM implementations, organisation will have to determine the business requirements and scaling demands, and match that with an appropriate solution in terms of capacity and capability of the Language Model used.

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.