Using DSPy For A RAG Implementation
RAG enables LLMs to adaptively access real-time knowledge, providing insightful responses beyond their original training. Yet, implementing refined RAG pipelines introduces complexities.

DSPy simplifies this process, offering a seamless setup for prompting pipelines.

Introduction
Retrieval-augmented generation (RAG) is a methodology enabling Language Models (LLMs) to access extensive knowledge repositories, search them for pertinent passages, and leverage this information to generate refined responses.
RAG enable LLMs to dynamically utilise real-time knowledge even if not originally trained on the data by leveraging In-Context Learning (ICL).
However, with this approach comes greater complexities in setting up and refining RAG pipelines.
DSPy has a seamless approach to setting up a RAG prompting pipeline.

Below the DSPy RAG application sequence is shown…
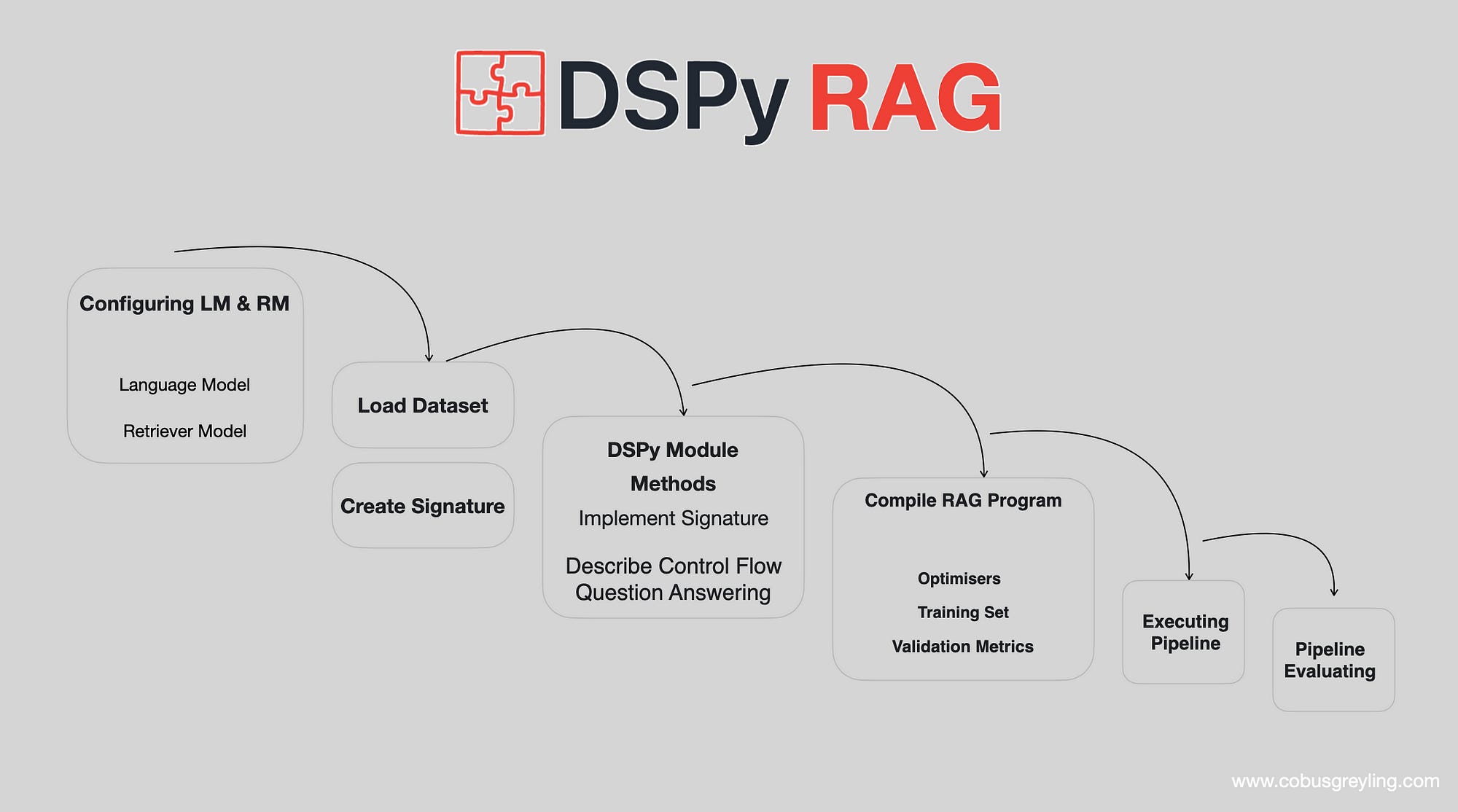
DSPy RAG Program
In this notebook, GPT-3.5 (specifically gpt-3.5-turbo) and the ColBERTv2retriever are made use of.
The ColBERTv2 retriever is hosted on a free server, housing a search index derived from Wikipedia 2017 “abstracts,” which contain the introductory paragraphs of articles from a 2017 dump.
Below you can see how the Language Model and the Retriever Model are configured within DSPy settings.
import dspy
turbo = dspy.OpenAI(model='gpt-3.5-turbo')
colbertv2_wiki17_abstracts = dspy.ColBERTv2(url='http://20.102.90.50:2017/wiki17_abstracts')
dspy.settings.configure(lm=turbo, rm=colbertv2_wiki17_abstracts)next the test data is loaded:
from dspy.datasets import HotPotQA
# Load the dataset.
dataset = HotPotQA(train_seed=1, train_size=20, eval_seed=2023, dev_size=50, test_size=0)
# Tell DSPy that the 'question' field is the input. Any other fields are labels and/or metadata.
trainset = [x.with_inputs('question') for x in dataset.train]
devset = [x.with_inputs('question') for x in dataset.dev]
len(trainset), len(devset)And the signatures are created…you can see how the context, input and output fields are defined.
class GenerateAnswer(dspy.Signature):
"""Answer questions with short factoid answers."""
context = dspy.InputField(desc="may contain relevant facts")
question = dspy.InputField()
answer = dspy.OutputField(desc="often between 1 and 5 words")The RAG pipeline is created as a DSPy module which will require two methods:
The
__init__method will simply declare the sub-modules it needs:dspy.Retrieveanddspy.ChainOfThought. The latter is defined to implement ourGenerateAnswersignature.The
forwardmethod will describe the control flow of answering the question using the modules we have: Given a question, we'll search for the top-3 relevant passages and then feed them as context for answer generation.
class RAG(dspy.Module):
def __init__(self, num_passages=3):
super().__init__()
self.retrieve = dspy.Retrieve(k=num_passages)
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
def forward(self, question):
context = self.retrieve(question).passages
prediction = self.generate_answer(context=context, question=question)
return dspy.Prediction(context=context, answer=prediction.answer)Here is an example of the training data:
Example({'question': 'At My Window was released by which American singer-songwriter?',
'answer': 'John Townes Van Zandt'})
(input_keys={'question'}),
Example({'question': 'which American actor was Candace Kita guest starred with ',
'answer': 'Bill Murray'})
(input_keys={'question'}),
Example({'question': 'Which of these publications was most recently published, Who Put the Bomp or Self?',
'answer': 'Self'})
(input_keys={'question'}), Executing the Program
Below the program is executed with a question…
# Ask any question you like to this simple RAG program.
my_question = "What castle did David Gregory inherit?"
# Get the prediction. This contains `pred.context` and `pred.answer`.
pred = compiled_rag(my_question)
# Print the contexts and the answer.
print(f"Question: {my_question}")
print(f"Predicted Answer: {pred.answer}")
print(f"Retrieved Contexts (truncated): {[c[:200] + '...' for c in pred.context]}")With the response:
Question: What castle did David Gregory inherit?
Predicted Answer: Kinnairdy Castle
Retrieved Contexts (truncated): ['David Gregory (physician) | David Gregory (20 December 1625 – 1720) was a Scottish physician and inventor. His surname is sometimes spelt as Gregorie, the original Scottish spelling. He inherited Kinn...', 'Gregory Tarchaneiotes | Gregory Tarchaneiotes (Greek: Γρηγόριος Ταρχανειώτης , Italian: "Gregorio Tracanioto" or "Tracamoto" ) was a "protospatharius" and the long-reigning catepan of Italy from 998 t...', 'David Gregory (mathematician) | David Gregory (originally spelt Gregorie) FRS (? 1659 – 10 October 1708) was a Scottish mathematician and astronomer. He was professor of mathematics at the University ...']In Conclusion
Considering the DSPy implementation, there are a few initial observations:
The code is clean and concise.
Creating an initial RAG application is straight forward with enough parameters which can be set.
Having a robust data ingestion pipeline is very convenient and that will have to be a consideration.
The built-in evaluation of the pipeline and retrieval is convenient..
I cannot comment on the extensibility and scaling of the RAG framework, and the complexity of building code around the DSPy RAG framework.
However, as a quick standalone implementation, it is impressive in its simplicity.
Lastly, considering the graphic below, the GitHub communities of LangChain, LlamaIndex and DSPy.