AI Agents - Orchestrating Multiple Models
Small Language Models should & will handle most tasks in agentic systems

AI Agents and agentic applications will, as a default, depend on multiple language models to function effectively in production.
This approach involves orchestrating various models where small ones perform the bulk of sub-tasks.
Evidence from OpenAI’s systems shows this pattern already in use with recent enhancements pushing efficiency further.
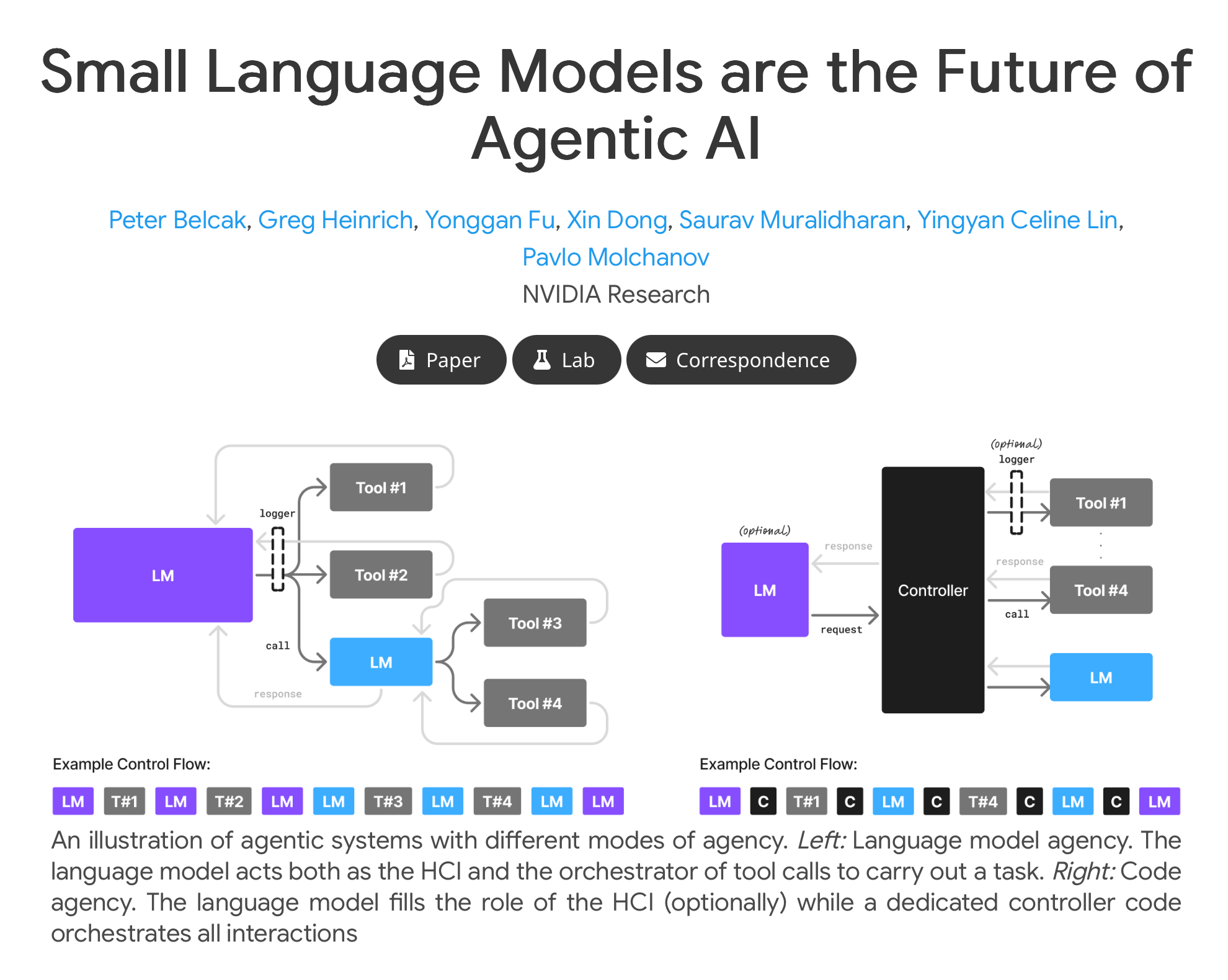
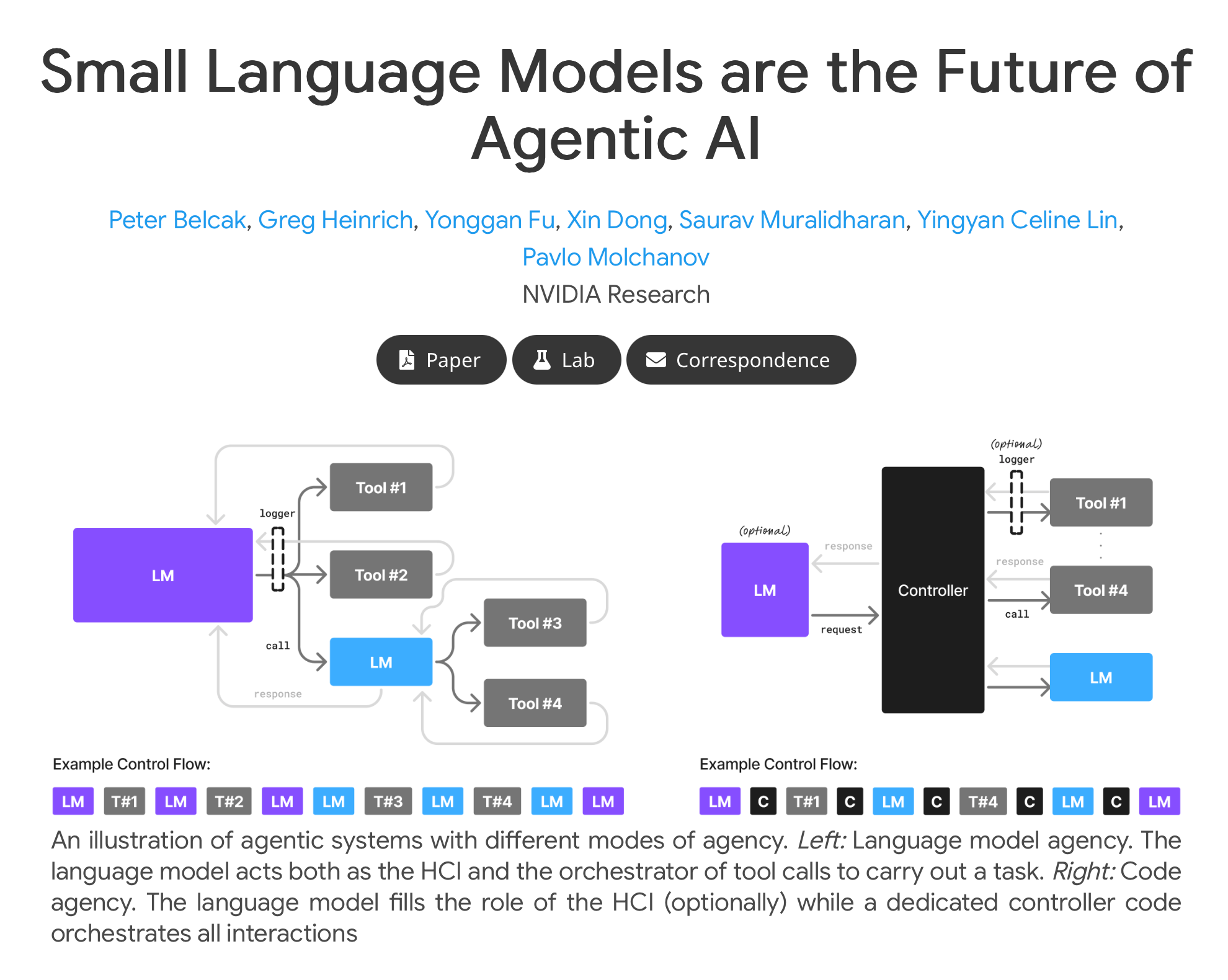
NVIDIA’s research reinforces this by advocating small language models as the core for agentic AI emphasising their suitability for modular workflows.
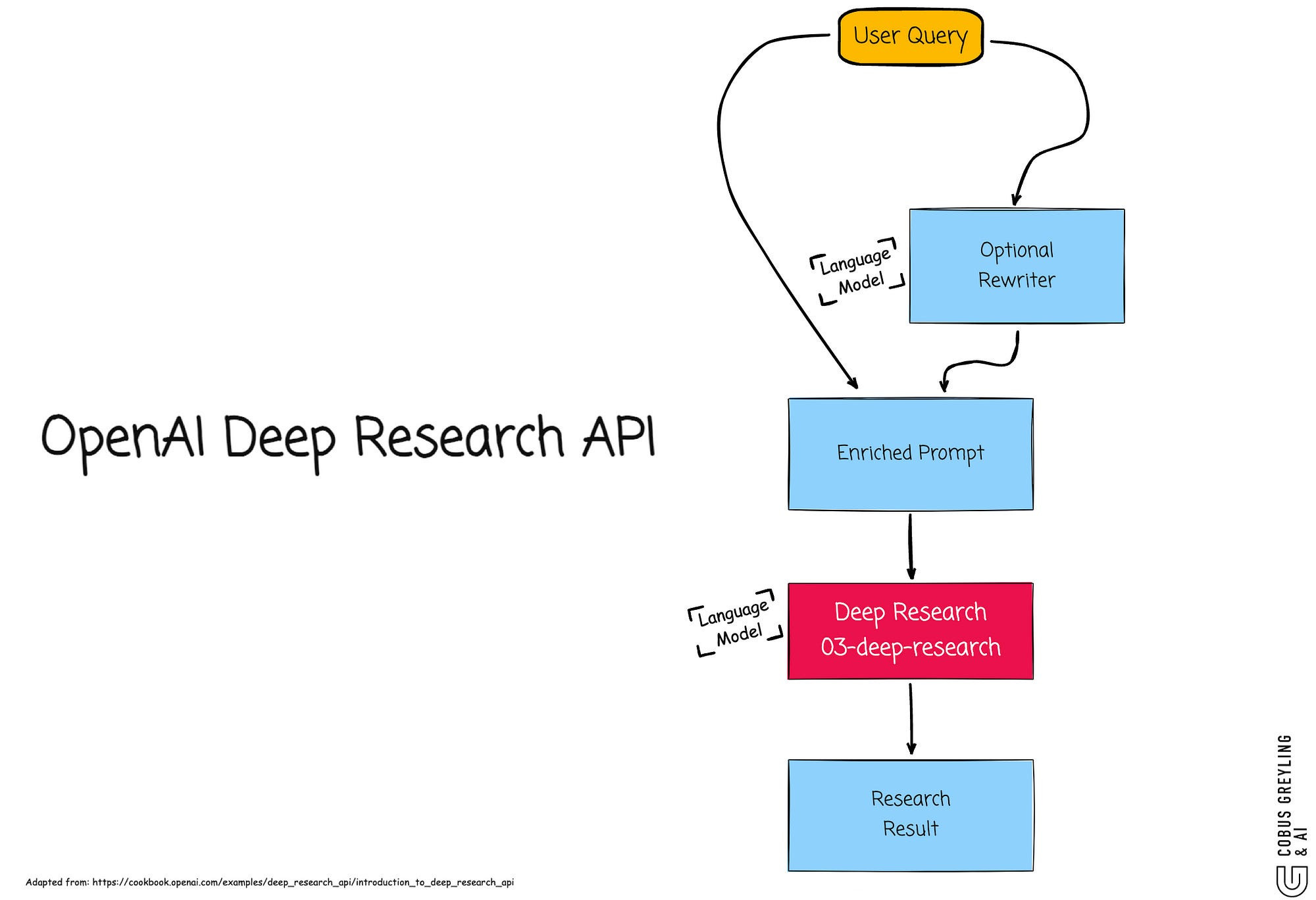
OpenAI’s ChatGPT architecture reveals a multi-model setup.
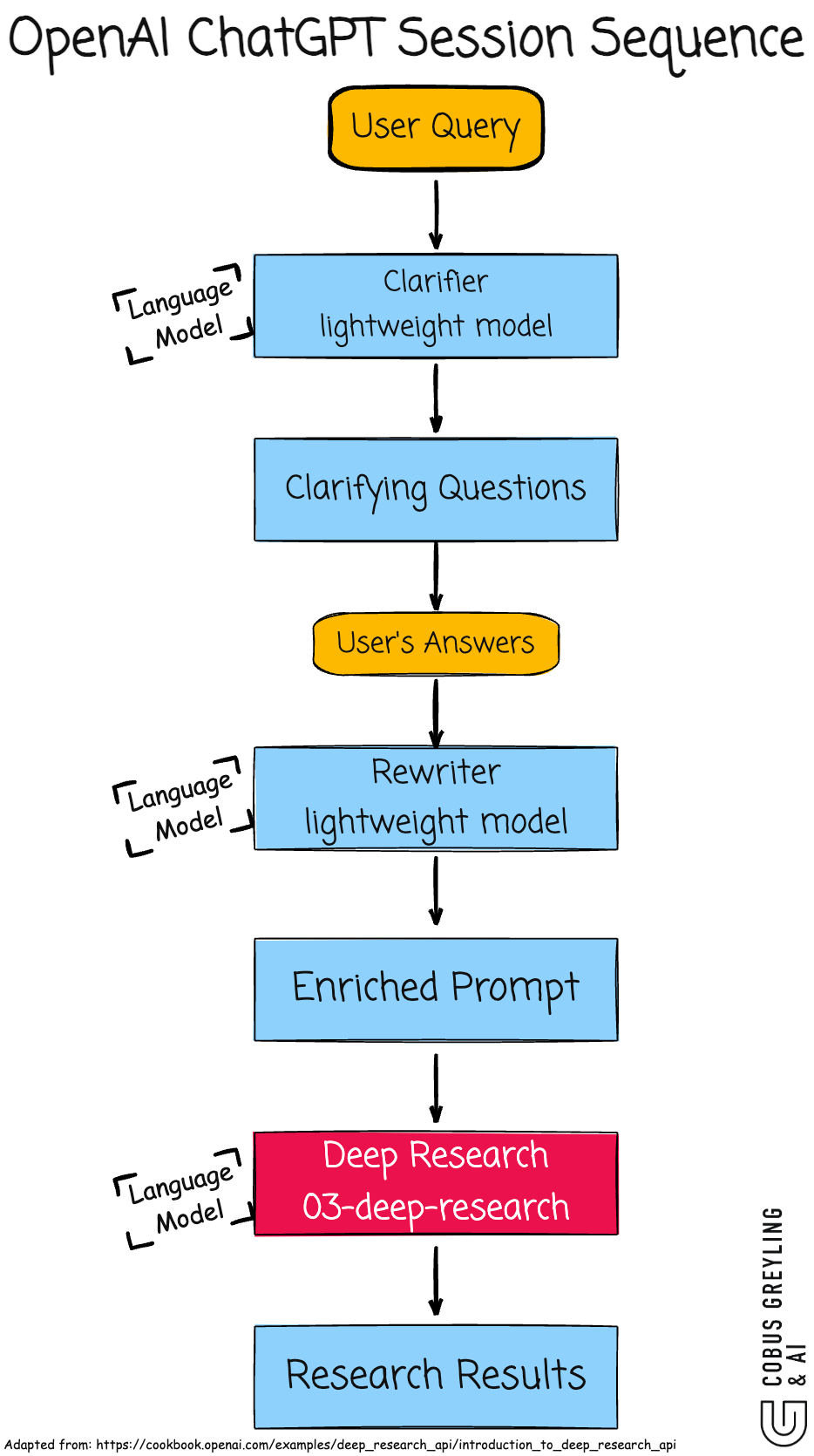
It employs three distinct language models for different stages.
The first clarifies user intent through disambiguation questions.
For example it asks for details on vague queries like trip planning to France including budget dates and preferences to avoid misaligned outputs.
The second optimizes the prompt by rewriting it for clarity precision and structure often fixing logical gaps or format issues.
The third conducts the deep research synthesising information into outputs like reports summaries or data sets ready for visualisation.
This mirrors the Deep Research API which exposes similar internals but gives developers control over input framing through explicit tool configurations and system messages.
In the API models include o3-deep-research-2025–06–26 for high-quality synthesis and o4-mini-deep-research-2025–06–26 as a lightweight option for faster tasks with lower latency.
The system routes queries through a pipeline of agents…
A Triage Agent assesses the input and directs it to a Clarifier if needed for additional context gathering.
The Clarifier establishes intent by asking targeted follow-ups and integrating responses.
An Instruction Builder then crafts a precise research brief outlining steps and tools.
Finally the Research Agent handles web searches knowledge retrieval and synthesis streaming progress events for real-time transparency during execution.
This modular design allows debugging via functions like print_agent_interaction which logs sequenced activities including handoffs and tool calls.
Disambiguation plays a key role
Without it ambiguous queries lead to poor results or wasted compute.
By asking targeted follow-ups the system aligns with user needs reducing errors in complex tasks.
For instance in planning scenarios it probes for constraints like timelines or scopes to refine the query upfront.
Establishing intent early ensures the orchestration flows smoothly especially for deep research where incomplete context can derail multi-step reasoning.
Deep research queries are long-running and expensive.
They involve multi-step reasoning web-scale searches knowledge integration and synthesis which can take minutes or longer even with optimised models.
To mitigate costs OpenAI uses cheaper small models for initial steps like clarification prompt building and intent collection reserving larger models for the core research phase.
Asynchronous processing in the API enables batch handling for scalability while outputs include bibliographies raw data for charts and verifiable sources minimizing manual post-processing.
This optimisation extends to custom integrations like querying internal documents via tools such as MCP for enterprise applications in healthcare or finance.
This modularity extends to prompt optimisation where agents check for contradictions format issues and consistency with examples.
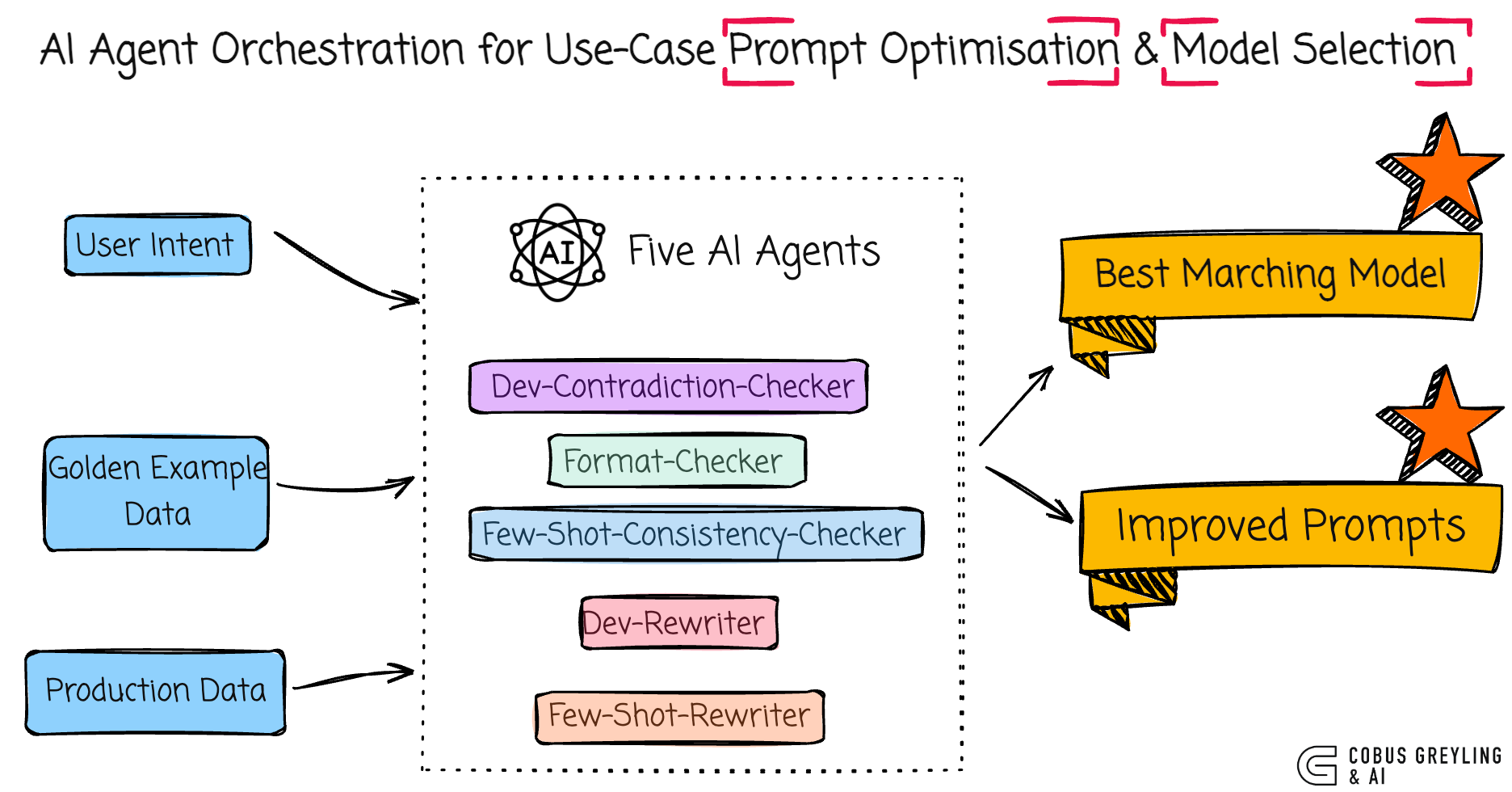
Specialized AI Agents work in parallel using structured data models to rewrite prompts while preserving intent.
For example a Dev-Contradiction-Checker scans for logical conflicts like conflicting number requirements and lists them in JSON.
Model selection factors in accuracy cost and speed evaluated against benchmarks like golden examples to choose options like o3 for precision or lighter variants for speed.

NVIDIA takes a similar path emphasising small language models for agentic AI.
They argue SLMs offer lower latency reduced memory needs and lower costs making them ideal for most sub-tasks in agents with LLMs invoked only when necessary for heavy lifting.
Recent papers affirm this positioning SLMs as powerful enough for constrained domains while enabling edge deployment and fine-tuning agility.
Tool Selection
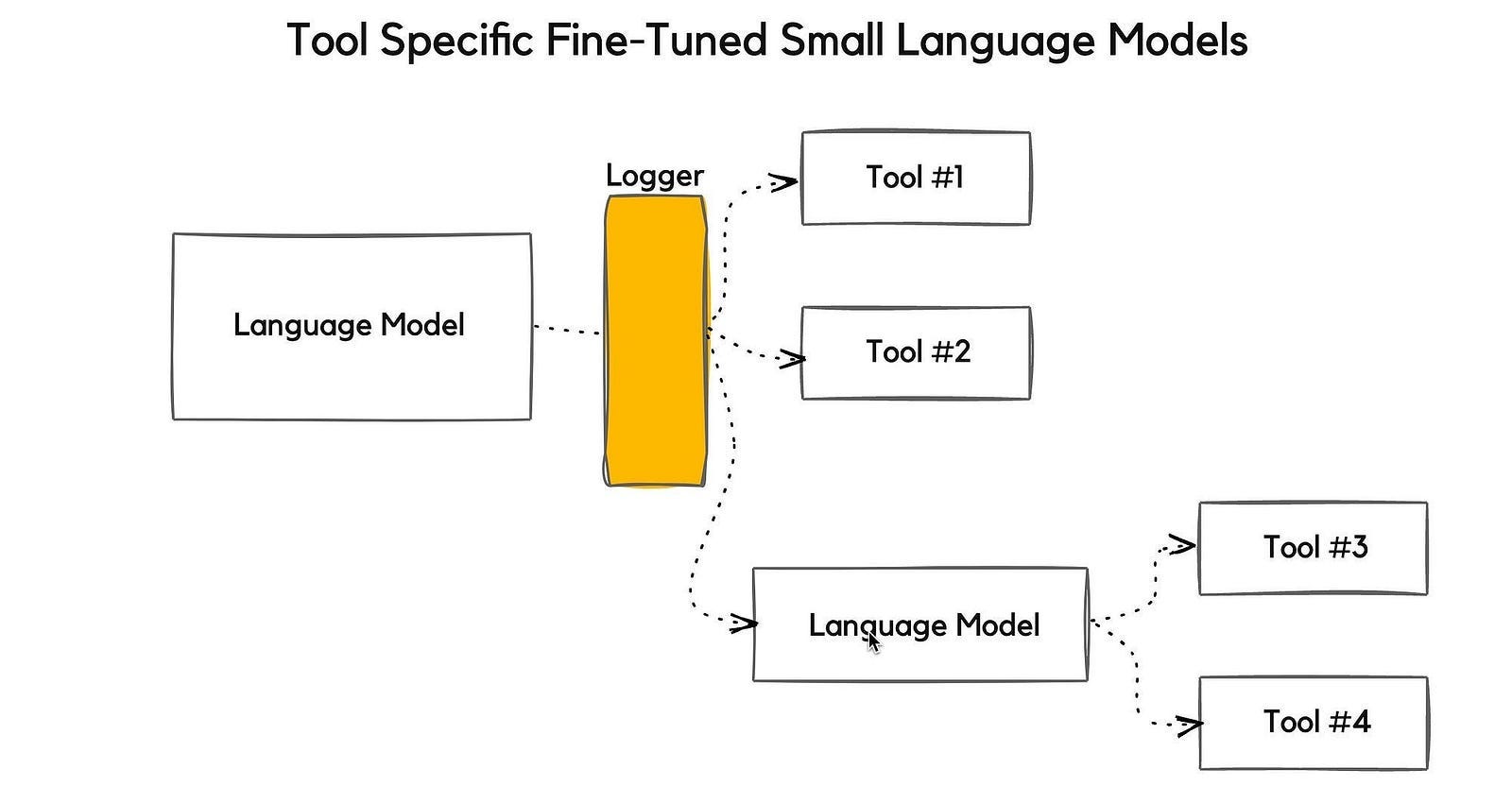
A compelling aspect is NVIDIA’s fine-tuning for tool selection.
They train models specifically to choose the right tool for a step optimising accuracy through a data flywheel.
User interactions generate feedback which curates data for fine-tuning.
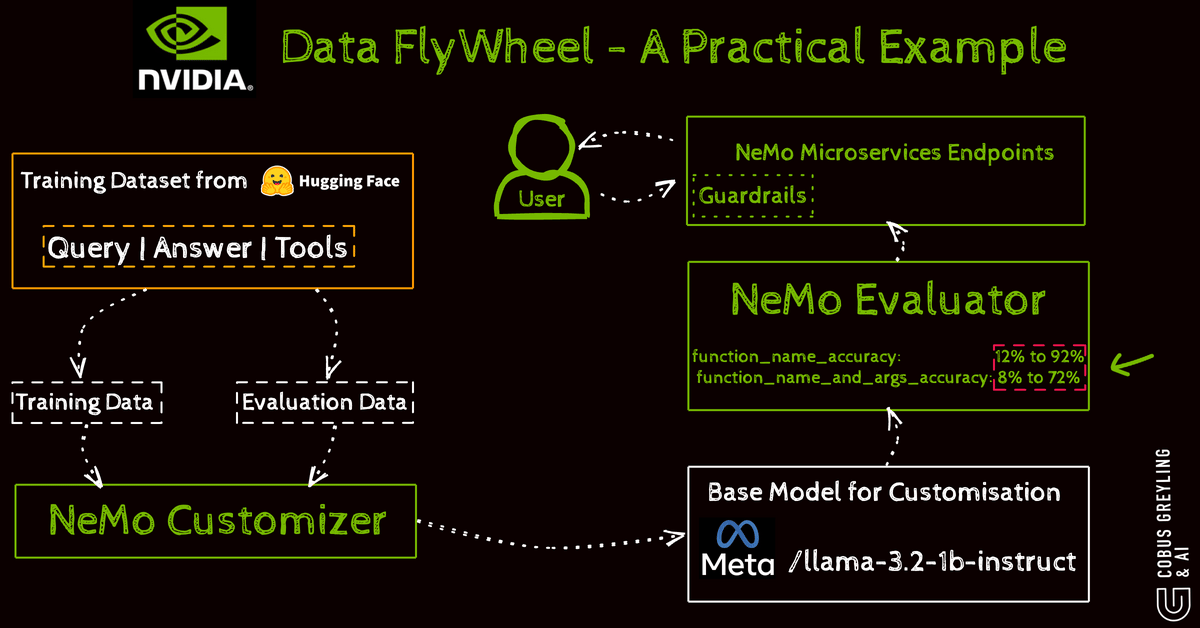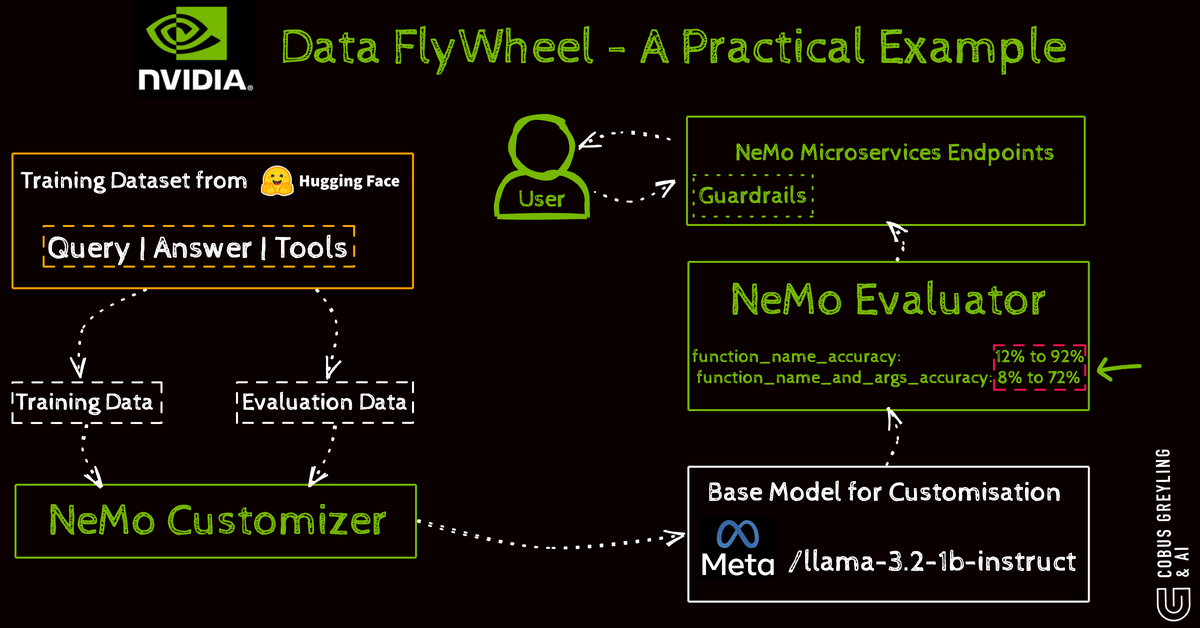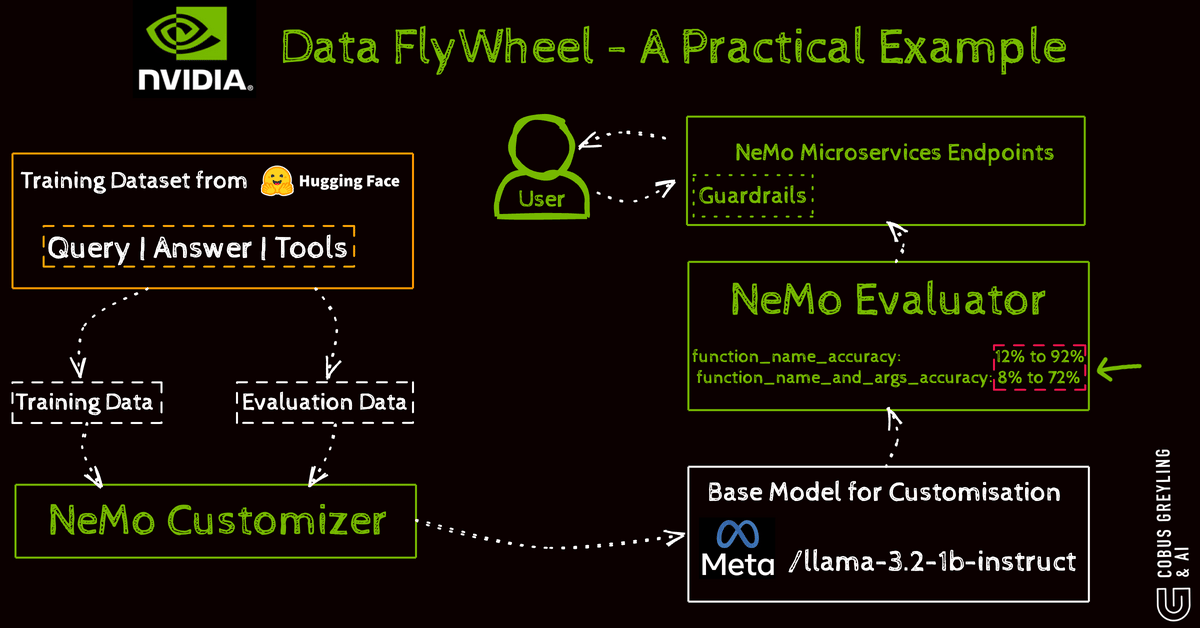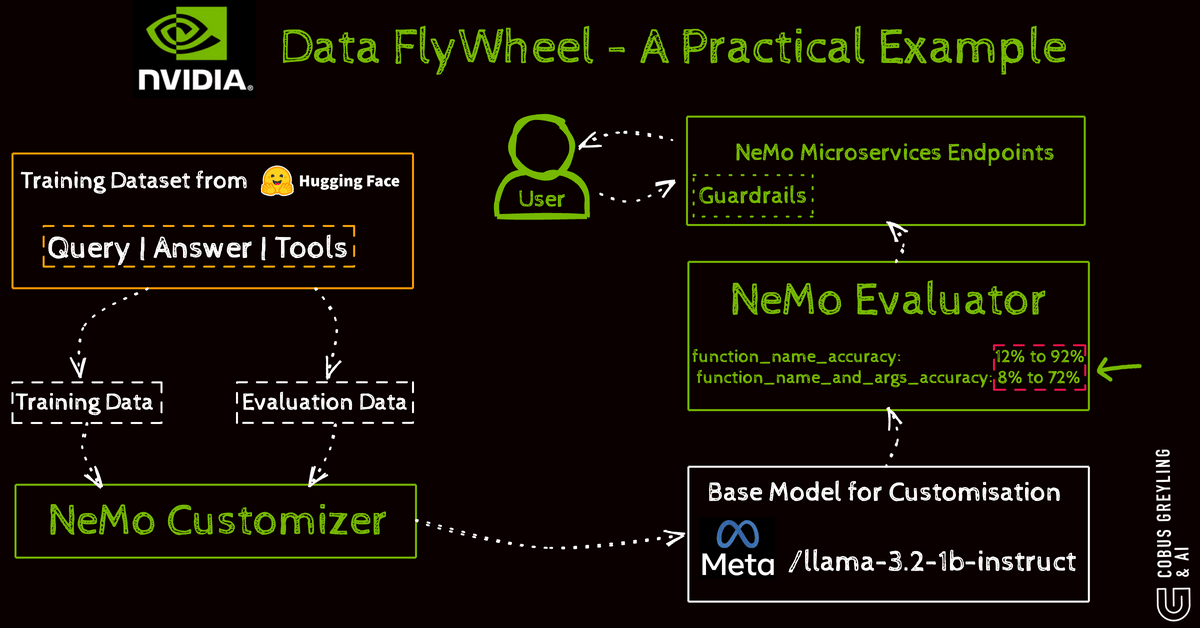
Tools like NeMo handle this cycle with steps including setup data preparation fine-tuning inference evaluation and guardrails for safety.
For instance fine-tuning Llama-3.2–1B-Instruct on function-calling datasets improves tool identification in workflows using GPU-accelerated techniques for enterprise scalability.
NVIDIA outlines a six-step process to build SLM agents.
It starts with gathering usage data from LLM setups scrubbing it for sensitivity then clustering to identify task patterns.
Next select SLMs per cluster fine-tune with tailored datasets and implement a continuous loop for refinement. In agents this means decomposing goals into sub-tasks assigning small models where possible and invoking LLMs sparingly.
Recent developments in 2025 highlight this trend’s momentum.
Multi-agent systems now coordinate specialised models for tandem operations as seen in enterprise orchestration platforms.
Frameworks like LangGraph support graph-based agent building with multiple LLMs while Microsoft advances open agentic webs with enhanced reasoning. Projections show the AI agent market growing rapidly driven by these efficient multi-model setups.
Both OpenAI and NVIDIA show that orchestrating multiple models — mostly small — boosts efficiency.
Agents handle complex work by breaking it down matching models to tasks and iterating via data loops.
For long-running queries optimisation via disambiguation intent alignment modular design and continuous fine-tuning cuts costs and improves outputs.
This shift to multi-model systems marks a practical evolution in AI applications setting the stage for broader adoption in 2025 and beyond.
Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. Language Models, AI Agents, Agentic Apps, Dev Frameworks & Data-Driven Tools shaping tomorrow.
Resources:
Using AI Agents For Prompt Optimisation & Language Model Selection

Thanks for reading Cobus Greyling on LLMs, NLU, NLP, chatbots & voicebots! Subscribe for free to receive new posts and support my work.
NVIDIA Tool-Calling Data Flywheel for Smarter, Smaller Language Models— A Practical Guide

Thanks for reading Cobus Greyling on LLMs, NLU, NLP, chatbots & voicebots! Subscribe for free to receive new posts and support my work.
NVIDIA Says Small Language Models Are The Future of Agentic AI

Thanks for reading Cobus Greyling on LLMs, NLU, NLP, chatbots & voicebots! Subscribe for free to receive new posts and support my work.

The AI Agent economy is small & personal......